
smp架构与numa架构
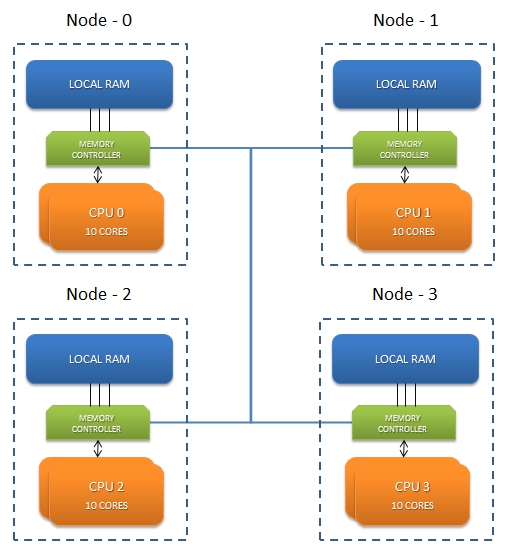
这些具有巨大内核的盒子带有非统一内存访问(NUMA)架构。 NUMA是可提高本地节点的内存访问性能的体系结构。 这些新的硬件盒分为称为节点的不同区域。 这些节点具有一定数量的核心,并分配有一部分内存。 因此,对于具有1 TB RAM和80个核心的机箱,我们有4个节点,每个节点具有20个核心和256 GB的内存分配。
您可以使用命令numactl --hardware
>numactl --hardware
available: 4 nodes (0-3)
node 0 size: 258508 MB
node 0 free: 186566 MB
node 1 size: 258560 MB
node 1 free: 237408 MB
node 2 size: 258560 MB
node 2 free: 234198 MB
node 3 size: 256540 MB
node 3 free: 237182 MB
node distances:
node 0 1 2 3
0: 10 20 20 20
1: 20 10 20 20
2: 20 20 10 20
3: 20 20 20 10JVM启动时,它将启动线程,这些线程是在某些随机节点的内核上调度的。 每个线程都尽可能快地使用其本地内存。 线程可能在某个时候处于WAITING状态,并在CPU上重新调度。 这次不能保证它将在同一节点上。 现在这一次,它必须访问一个远程存储位置,这会增加延迟。 远程存储器访问速度较慢,因为指令必须遍历互连链路,从而引入额外的跃点。
Linux命令numactl提供了一种仅将进程绑定到某些节点的方法。 它将进程锁定到特定的节点以执行和分配内存。 如果将JVM实例锁定到单个节点,则将删除节点间的流量,并且所有内存访问都将在快速本地内存上进行。
numactl --cpunodebind=nodes, -c nodes
Only execute process on the CPUs of nodes.创建了一个小型测试,该测试试图序列化一个大对象并计算每秒的事务和延迟。
要执行绑定到一个节点的Java进程,请执行
numactl --cpunodebind=0 java -Dthreads=10 -jar serializationTest.jar将此测试运行在两个不同的盒子上。
盒子A
4个CPU x 10核x 2(超线程)=总共80核
节点:0,1,2,3
方块B
2个CPU x 10个内核x 2个(超线程)=总共40个内核
节点:0,1
CPU速度:两者均为2.4 GHz。
默认设置也使用包装盒上所有可用的节点。
框 | NUMA政策 | TPS | 延迟(平均) | 延迟(分钟) |
一个 | 默认 | 261 | 37 | 18 |
乙 | 默认 | 387 | 25 | 5 |
一个 | –cpunodebind = 0,1 | 405 | 23 | 3 |
乙 | –cpunodebind = 0 | 1,613 | 5 | 3 |
一个 | –cpunodebind = 0 | 1,619 | 5 | 3 |
因此,我们可以推断,与“ 2个节点” Box B上的默认设置相比,“节点较多”的Box A上的默认设置在“ CPU密集型”测试中的性能较低。但是,由于我们仅将流程绑定到2个节点,因此它的性能相同更好。 可能是因为它的节点跳数更少,并且在同一节点上重新安排线程的概率增加到50%。
当--cpunodebind=0 ,它的表现优于所有情况。
注意:以上测试是在10个内核上使用10个线程运行的。



















{kind=link}