
(一)管道外部实现
当我们定义一个管道时,这个管道是由内核管理的一个缓冲区,可以抽象为现实生活中的一个传输线路。管道的一端连接一个进程的输出,这个进程会向管道中放入信息。管道的另一端连接一个进程的输入,这个进程取出被放入管道的信息。当管道中没有信息的话,从管道中读取的进程会等待,直到另一端的进程放入信息。当管道被放满信息的时候,尝试放入信息的进程会等待,直到另一端的进程取出信息。当两个进程都终结的时候,管道也自动消失。 从原理上,管道利用fork机制建立,从而让两个进程可以连接到同一个PIPE上。
在Linux中,管道是一种使用非常频繁的通信机制。从本质上说,管道也是一种文件,但它又和一般的文件有所不同,管道可以克服使用文件进行通信的两个问题,具体表现为:
· (1)限制管道的大小。实际上,管道是一个固定大小的缓冲区。在Linux中,该缓冲区的大小为1页,即4K字节,使得它的大小不象文件那样不加检验地增长。使用单个固定缓冲区也会带来问题,比如在写管道时可能变满,当这种情况发生时,随后对管道的write()调用将默认地被阻塞,等待某些数据被读取,以便腾出足够的空间供write()调用写。
· (2) 读取进程也可能工作得比写进程快。当所有当前进程数据已被读取时,管道变空。当这种情况发生时,一个随后的read()调用将默认地被阻塞,等待某些数据被写入,这解决了read()调用返回文件结束的问题。
(二)管道的内部实现机制
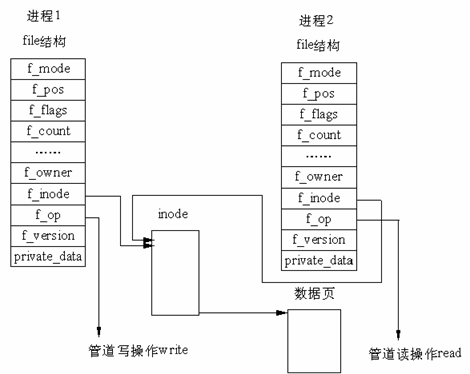
实际上pipe并没有单独的实现数据结构,他利用了文件的 在 Linux 中,而是借助了文件系统的file结构和VFS的索引节点inode。通过将两个 file 结构指向同一个临时的 VFS 索引节点,而这个 VFS 索引节点又指向一个物理页面而实现的。有两个 file 数据结构,但它们定义文件操作例程地址是不同的,其中一个是向管道中写入数据的例程地址,而另一个是从管道中读出数据的例程地址。这样,用户程序的系统调用仍然是通常的文件操作,而内核却利用这种抽象机制实现了管道这一特殊操作。
(三)管道大小和容量的区别
我们通过ulimit -a命令查看到的pipo size定义的是内核管道缓冲区的大小,这个值的大小是由内核设定的;而pipe capacity指的是管道的最大值,即容量,是内核内存中的一个缓冲区。
1)管道大小

如图,大小为8kb。
2)管道容量
当管道一端不断地读取数据,另一端却不输出数据。根据linux的实现机制当管道读满是输出端自动阻塞。所以这个管道是有容量的
现在我们编写程序来测试管道的容量

结果:

结果管道容量为64kb。
(四)管道特点:
(1)、单向通信。数据只能由一个进程流向另一个进程(其中一个读管道,一个写管道);如果要进行双工通信,需要建 立两个管道。
(2)、管道只能用于有血缘关系的进程间通信。
(3)、流式服务。发送和接收大小不受特定格式的限制。
(4)、管道的生命周期和进程有关。
(5)、同步与互斥原则。




















