
Windows环境下现有文本编辑器以UltraEdit功能最为强大,对大文件的处理速度是其它编辑器所望尘莫及的。在输入法词库整理过程中,我的绝大部分操作是用UltraEdit来完成。
设置:
1、选择菜单“高级 / 设置代码页地区”,如下设置:

2、自定义工具栏,添加“转换为Unicode”和“转换自Unicode”命令按钮至工具栏。

说明:UltraEdit对中文支持不太完善。把处理文件转换为Unicode格式可解决99%的兼容性问题。但少量时候需用ASCII模式处理,如下文所述“查找特定字结尾词条”时。如对查找结果不放心可用ASCII格式和Unicode格式分别查找,然后对比结果。
我的整理方法是在不考虑词频的前提下把大词库按规律分割为若干个小库,然后分类整理。
多音字(含拼音)词条和非多音字(不含拼音)词条的分割:
1、调出查找窗口,选中“列出包含字符串的行”和“正则表达式”
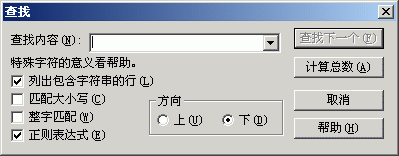
2、查找内容中输入“[a-z]”,点击“查找下一个”按钮。
3、此时弹出“包含查找字符串的行”对话框,可以直接选择相应的条目进行修改。
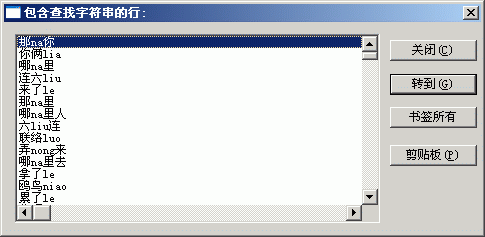
4、因为我们需要把含拼音词条分离出来,点击“剪切板”按钮,新建文件后粘贴,可把查找到词条复制到新文件中。这样得到的新文件就是多音字(含拼音)词条了。
5、在词组工具1.0中用原文件删去多音字(含拼音)词条可以得到非多音字(不含拼音)词条。
校对多音字:
同样,多音字词条的校对可按多音字来查找词条校对,校对完毕后粘贴到新文件中。
1、打开多音字字频表,复制“的”到剪贴板。
2、在词库文件中查找“的”。
3、依次选择查找到词条进行校对。

4、校对完毕后重新查找含“的”的词条粘贴到新文件中保存。
5、用词组工具1.0删除校对过词条。
6、重复1-5,校对下一个多音字词条。
查找中国人名(特定字开始):
1、通过常见姓氏表,在词库文件中查找“%[李王张刘陈杨赵黄周吴徐孙胡朱高林何郭马罗]”。

2、粘贴到新文件中按需求整理。
3、重复1-3,查找下一组姓氏。
查找特定字结尾词条(比方说“的”、“得”、“地”结尾):
查找关键字:“的de$”、“得de$”、“地de$”、“地di$”

说明:$为行尾匹配符,如$前一个字符为英文(比方说上述的查找关键字“的de$”)则需要使用ASCII模式,Unicode模式有可能吃掉最后一个字母。
删除所有的拼音(把词库导出至其它输入法使用)
1、打开替换窗口,查找关键字为“[a-z]”,替换关键字为空。
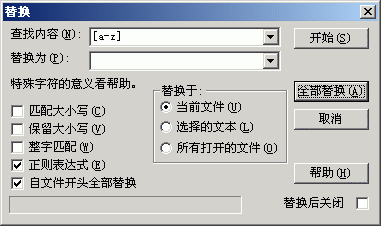
2、此操作文件格式必须为Unicode,如感兴趣者可用两种模式分别去拼比较一下结果。
综上所述,主要是用到了正则表达式查找功能。以下是UltraEdit正则表达式的完整语法:
符号 | 功能 |
% | 匹配行首 - 表示搜索字符串必须在行首,但不包括任何选定的结果字符中的行终止字符。 |
$ | 匹配行尾 - 表示搜索字符串必须在行尾,但不包括任何选定的结果字符中的行终止字符。 |
? | 匹配任何除换行符的字符。 |
* | 匹配任何除换行符外所出现的字符数。 |
+ | 匹配一个或多个前面的字符/表达式。必须找到至少一个出现的字符。不匹配重复的换行符。 |
++ | 0 次或多次匹配前面的字符/表达式。不匹配重复的换行符。 |
^b | 匹配一个分页任。 |
^p | 匹配一个换行符 (CR/LF) (段落) (DOS 文件) |
^r | 匹配一个换行符 (仅 CR) (段落) (MAC 文件) |
^n | 匹配一个换行符 (仅 LF) (段落) (UNIX 文件) |
^t | 匹配一个制表符 |
[ ] | 匹配任何括号中的单个字符或范围 |
^{A^}^{B^} | 匹配表达式 A 或 B |
^ | 忽略其后的正则表达式字符 |
^(*^) | 在表达式加上括号或标签在替换命令中使用。正则表达式中可以有 9 个表达式标签,数字根据它们在正则表达式中的次序确定数字。 |
其它常用操作:
EmEditor是一款日本人编写的文件编辑器,对大文件的处理速度较慢,但双字节字符集支持良好。以下操作使用EmEditor完成较为适合。
词条排序:
UltraEdit中的词条排序效果不好,而Excel有行数限制。可使用EmEditor加载排序插件来进行(可选择按拼音或笔画排序)。

删除重复行:
EmEditor加载插件完成。



















