
首先说明,这个内容不能说完全原创,结合了其他学习平台学习的思路,加上一点自己的理解。就是记录下来方便自己之后查阅。
目录
**1. 数据采集
2. 认识数据集 **
数据集有csv json
xlsx等格式,可以储存在本地或者服务器上。在分析数据之前需要将数据集导入到Jupyter中。本次利用Pandas库(能够规范数据框架)对csv格式的汽车数据集进行试验。
1.1数据库引入和查看
#数据库引入
import pandas as pd
#引用函数pd.read_csv读取csv文件,命名为df
df = pd.read_csv("/resources/jupyter/DA001/DA001-001/imports-85.data", header = None)
#查看前10行、后10行数据,head函数
df.head(10)
df.tail(10)1.2为数据集添加标题
从上面图可知,数据有26列,标题从最后一列开始赋值,添加一个标题就整体往前移动一格。所以一般情况下要写26个标题。(此处因为不想打字所以在后面用数字代替。)
在不进行单独赋值的前提下,pandas为数据列赋值为0,1,2…,记在df.columns中。因此直接用编辑好的表头(headers)进行替换即可。
#现将编辑好的标题存在headers(=[" ", , ])中
headers = ["symboling",“normalizes-losses","make","fuel-type","aspiration","6","7","8","9","10","11","12","13","14","15","16","17","18","19","20","21","22","23","24","25","26"]
#将标题替换掉pandas自带的0,1,2,3,4,5...的标题
df.columns = headers
df.head(10)#查看,默认5行
1.3数据的保存
用pandas里面的dataframe.to_cav()函数进行保存,括号填写本地路径以及文件名称。其中dataframe是之前引入数据时保存的名称。在这里用的是df
df.to_csv("automobile.csv")在这里引用这个博客的方法查询默认保存路径 Jupyter notebook文件默认存储路径以及更改方法
运行结果如下

其他类型文件的保存语法
process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zODE2OTY1NQ==,size_16,color_FFFFFF,t_70)2.1数据类型
数据本身有object float int bool
datetime64,有些数据集还会在后面显示64,如float64。数据类型可以通过dateframe.dtypes进行查询.
df.dtypes2.2对数据类型进行计数和汇总
dataframe.describe()
df.describe(include = "all")这个函数返回每列数字类型的数目、平均值、标准差、最小值、最大值、缺失值,第25%、50%、75%等,输出如下:

2.3只对其中的几列进行查看
语法为dataframe[[‘column name 1’, ‘…2’, ‘…3’]]
df[['6', '7','8']]输出(直截取前几行)

然后再通过引用describe函数查看这几列的信息
df[['6', '7', '8']].describe(include = "all")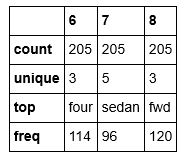
第二个查询列的方法是用dataframe.info函数,它可以展示数据列的前30行和后30行。但是我不太喜欢这个方式,标题和数字对不上,不如之间用notebook++看。



















