
一、为何需要生物数据库?
上期在介绍GenBank格式时举了新冠病毒基因组的例子,仅一个S基因就长达3822 nt(nucleotide,这里指核苷酸数),基因组全长接近3万个碱基。
LOCUS NC_045512 29903 bp ss-RNA linear VRL 18-JUL-2020
...
gene 21563..25384
/gene="S"
/locus_tag="GU280_gp02"
/gene_synonym="spike glycoprotein"
/db_xref="GeneID:43740568"
...一页A4纸大概能记录1.5万个碱基

北京大学图书馆以800万册的藏书量坐拥国内高校Top1 按照一本书500页A4纸计算,一个人的基因组约等于200本书,北京大学图书馆纸质书的数量近乎于4万人的基因组。
这还仅仅是一个物种的一小部分,成千上万的物种都有基因组数据,有的基因组甚至是人类基因组的数十倍,如重楼百合有150 Gb大小的基因组(表1), 人均每分钟英文字符的阅读量不足1千个[1] 。
如此算来,即便你昼夜不停地读,也要超过285年才能读完一个重楼百合的基因组序列。此外还有大量的注释信息,需要借助大型计算机才能存储下这些庞大的数据资源。
基于计算机资源构建的生物信息数据库可以更好地管理、更新和读取分析基因组数据
表1. 代表性物种的基因组大小
物种 | 基因组大小 |
新冠病毒 | ~30 Kb |
大肠杆菌 | ~5 Mb |
酵母 | 12 Mb |
秀丽隐杆线虫 | ~100 Mb |
果蝇 | 120 Mb |
人 | 3 Gb |
小麦 | ~17 Gb |
重楼百合 | 150 Gb |
二、数据库的分类
根据存储数据的类型,可划分为核酸数据库、蛋白质数据库和专用数据库
表2. 常用的生物数据库
分类 | 数据库名称 | 备注 |
核酸数据库 | 核酸数据库 | |
| 核酸数据库 | |
| 核酸数据库 | |
| 线虫数据库 | |
| 果蝇数据库 | |
| microRNA数据库 | |
蛋白质数据库 | 蛋白结构数据库 | |
| 蛋白序列数据库 | |
| 蛋白序列数据库 | |
| 蛋白结构域数据库 | |
| 蛋白互作数据库 | |
| 蛋白结构分类数据库 | |
| 蛋白保守基序数据库 | |
| 蛋白结构分类数据库 | |
| 蛋白序列特征数据库 | |
专用数据库 | 代谢通路数据库 | |
| 基因本体数据库 | |
| 文献数据库 | |
| 人类孟德尔遗传数据库 |
表3. 常用生物数据库ID
数据来源 | 数据类型 | 示例 |
GenBank | DNA sequences | AF071988.1 U12345.1 |
ENA | Projects Studies | PRJEB12345 ERP123456 |
| BioSamples Samples | SAMEA123456 ERS123456 |
| Experiments | ERX123456 |
| Runs | ERR123456 |
| Analyses | ERZ123456 |
| Assemblies | GCA_123456789.1 |
| Assembled/Annotated Sequences | A12345.1 AB123456.1 AB12345678 ABCD01123456 ABCDEF011234567 |
| Protein Coding Sequences | ABC12345.1 ABC1234567.1 |
Ensemble Genome Broswer | Genome | ENSG00000221914 |
UniProtKB/Swiss-Prot | Proteins with accurate, consistent and rich annotation | A2BC19 P12345 A0A023GPI8 |
很多编号看起来挺复杂,还不赶紧收藏一下本帖以备不时之需~
三、数据库的使用
下面简单介绍一下NCBI数据库的使用
Web blast

Nucleotide BLAST
核酸序列比对,query sequence为核酸序列,目标database为核酸数据库(NT)
blastx
核酸序列比对蛋白序列,query sequence为核酸序列,目标database为蛋白序列数据库(NR)
tblastn
蛋白序列比对核酸序列,query sequence为蛋白质序列,目标database为核酸数据库
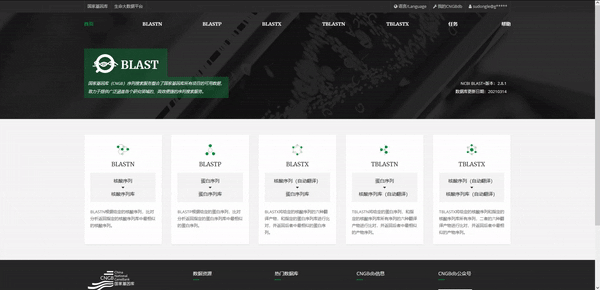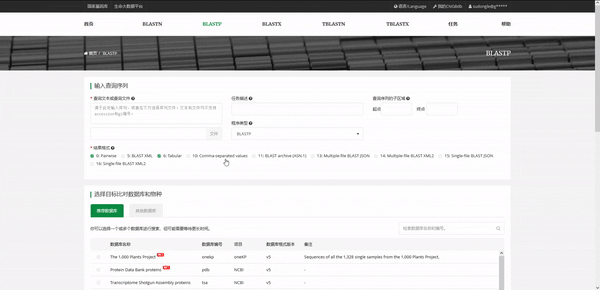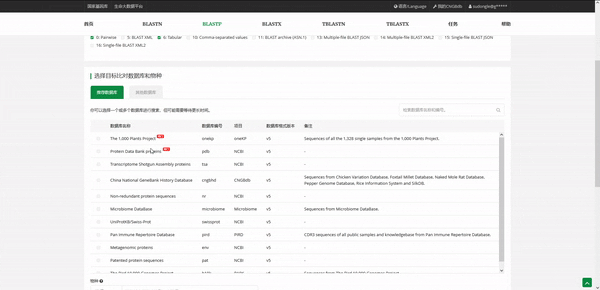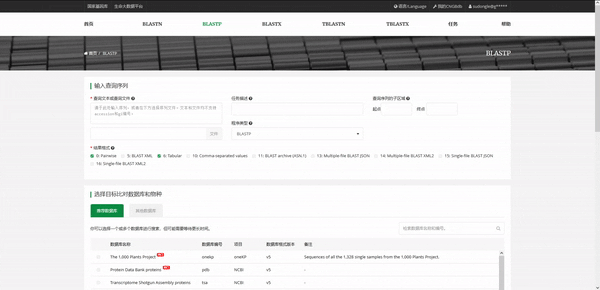
Protein BLAST
蛋白序列比对,query sequence为蛋白序列,目标database为蛋白序列数据库
举个例子
当你做PCR成功扩增出目的片段时,为了验证产物,得到产物的序列信息后应该进行核酸序列比对(Nucleotide blast)以确认产物是正确的,而非污染造成的假阳性。
此外,如果所扩增的片段编码蛋白质,还可以进行核酸序列比对蛋白序列(blastx)来查看相应的蛋白功能信息。
寻找同源蛋白
我们知道蛋白质在生物体的生命活动中承担着丰富而复杂的功能,而结构相同或相似的蛋白质一般具有相同的功能,其中有一部分我们可以基于序列相似性来判定这些蛋白的同源性
既然可以用序列相似性来判定两个蛋白是否为同源蛋白,那判定的阈值是多少呢?
研究表明,两个序列相似性达到50%及以上的蛋白,在同源建模时结构相差大约在1埃(0.1 nm)
当相似性低于30%时,仅通过序列信息预测获得的蛋白结构,其准确性难以保证[1]
也就是说 30% 就是我们用序列相似性评判蛋白质是否同源的一个阈值
其它数据库——国家基因库CNGBdb
除了NCBI的数据库,你还可以在国家基因库平台使用千种植物基因组项目(The 1000 Plants Project)和万种鸟类基因组项目(The Bird 10000 Genomes Project)等项目的数据库
参考文献
[1] Chung SY, Subbiah S. A structural explanation for the twilight zone of protein sequence homology. Structure. 1996;4(10):1123-1127. doi:10.1016/s0969-2126(96)00119-0


















