
1. sort命令介绍

sort命令是一个排序命令,可以对文件进行排序,然后将排序结果标准输出。
sort将文件的每一行作为一个单位,相互比较,比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
2. 语法格式及常用选项
依据惯例,我们还是先查看帮助,使用 sort --help
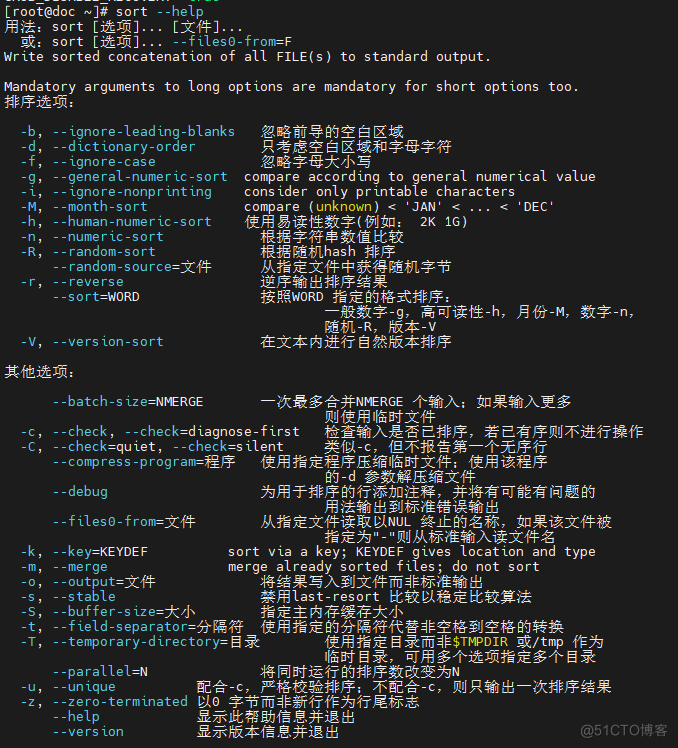
2.1 为了更直观一些,我们把常用的参数用表格来展示:
参数 | 描述 |
GNU 参数说明 | |
-c | 检查文件是否按照顺序进行排序 |
-d | 排序时,处理英文字母,数字及空格字母外,忽略其他字符 |
-f | 排序,将小写字母视为大写字母 |
-M | 将前面的3个字母依照月份缩写进行排序 |
-r | 以相反的顺序进行排序 |
-n | 依照数值的大小进行排序- |
-o | 排序后存入指定的文件 |
-t | 指定一个用来区分键位置字符 |
-k | 后面跟数字,指定按第几列进行排 |
有了具体的参数之后,我们再来看实战案例:
3. 参考案例
3.1 按照文本默认排序
此时,无需加任何参数,sort将文件/文本的每一行作为一个单位,相互比较.
比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
sort /etc/passwd | head -5

从上面的代码可以看到: 按照首字符的ASCII码排序,
这里要理解什么是ASCII码:
在计算机中,所有的数据在存储和运算时都要使用二进制表示。而ASCII是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,它是现今最通用的单字节编码系统。
英文字母对应的ACSII码如下:

3.2 忽略相同的行
-u参数主要用来忽略相同的行
## 可以看到有相同的行
[root@mufeng-06 ~]# cat a.txt
tiger
deer
lion
elphant
monkey
bear
dog
pig
pig
## 使用-u参数后
[root@mufeng06 ~]# sort -u a.txt 删除重复的行,但是空行不会被删除
bear
deer
dog
elphant
lion
monkey
pig
tiger使用-u参数后,相同的行就没有了。
我们之前写过一个脚本统计在线的IP数有多少个,代码如下:
先写一个测试脚本:
[root@mufenggrow ~]# cat ping1.sh
#!/bin/bash
str="192.168.1."
for num in {1..10}
do
ip=${str}${num}
ping -c1 -w1 $ip &>/dev/null
if [ $? -eq 0 ];then
echo $ip >>/root/online.txt
fi
done
# 统计在线IP的个数
notallow=`cat /root/online.txt|wc -l `
echo "在线ip总数为 $online"执行上面的脚本查看效果:
[root@mufenggrow ~]# ./ping1.sh
在线ip总数为 12我们发现执行的结果为12个IP,这个结果是否准确? 我们查看文件内容:
[root@mufenggrow ~]# cat online.txt
192.168.1.1
192.168.1.2
192.168.1.4
192.168.1.10
192.168.1.1
192.168.1.2
192.168.1.4
192.168.1.10
192.168.1.1
192.168.1.2
192.168.1.4
192.168.1.10通过查看文件,我们发现文件的内容为中有很多重复的IP,这时候我们就可以使用sort -u 参数:
[root@mufenggrow ~]# sort -u online.txt |wc -l
4使用这个命令之后,是不是就感觉IP少了很多,去掉了重复的,结果就对了。
3.3 按数字大小进行排序
此处使用-n 参数
当你使用sort命令对数字进行排序,但是又不用-n参数的时候,就会发现是乱序的:
[root@mufenggrow ~]# cat a.txt
1
2
333
111
110
112
223
229
91
54
[root@mufenggrow ~]# sort a.txt
1
110
111
112
2
223
229
333
54
91是不是从排序里感觉112 反而不如2大了?
加上-n参数才是正常的,我们来看下代码:
[root@mufenggrow ~]# sort -n a.txt
1
2
54
91
110
111
112
223
229
333如果向对数字进行倒序排列,需要加-r 参数, 当然这里要对数字排序,所以-n还是少不了的。
[root@mufenggrow ~]# sort -nr a.txt
333
229
223
112
111
110
91
54
2
13.4 检查文件是否已经按照顺序排序
-c参数,可以检查文件是否按照顺序排序
[root@mufenggrow ~]# sort -c a.txt
sort:a.txt:4:无序: 111可以看到无序,表示没有按照顺序排序,这里需要主要,当我们对一个文件排序后,虽然会再屏幕上显示,但并不会修改源文件。
3.5 将第3列按照数字大小进行排序
这里用到以下几个参数:
-n是按照数字大小排序
-r是以相反顺序
-k是指定需要排序的栏位
-t指定栏位分隔符为冒号
我们对/etc/passwd 以冒号为分隔符,把第三列进行大小排序
[root@mufenggrow ~]# sort -t: -nk 3 /etc/passwd |head -5
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin如果我们要将上面的排序变成从大到小排列:
[root@mufenggrow ~]# sort -t: -nrk 3 /etc/passwd |head -5
nfsnobody:x:65534:65534:Anonymous NFS User:/var/lib/nfs:/sbin/nologin
laoxin:x:1000:1000:laoxin:/home/laoxin:/bin/bash
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
colord:x:998:997:User for colord:/var/lib/colord:/sbin/nologin
libstoragemgmt:x:997:995:daemon account for libstoragemgmt:/var/run/lsm:/sbin/nologin注意:
-t后面可以跟分隔符,如果分割符为: 比如容易操作,但如果分隔符为空格的时候,需要确认空格是否是规则的,比如有的是多个空格,有的是一个空格,就很难达到预期的效果
root@mufenggrow ~]# sort -t " " -k 3 b.txt
9 9 1 0
1 2 3 4
2 2 4 5
5 6 7 8
[root@mufenggrow ~]# cat c.txt
1 2 33 44
2 2 3 4
7 9 11 4
3 4 6 7
[root@mufenggrow ~]# sort -t " " -k 4 c.txt
1 2 33 44
2 2 3 4
3 4 6 7
7 9 11 4最后一个的排序按照第四列,就没成功,所以还是那句话,如果空格比较杂乱的时候,不建议使用空格进行排序,如果非要用空格,可以先做预处理。
3.6 将排序结果输出到文件
-o参数可以将结果输出到文件,比如我们把3.5的排序输出到a.txt中
root@mufenggrow ~]# sort -t: -nrk 3 /etc/passwd -o a.txt4. 探讨 -k的高级用法
案例一: 使用-u 参数去重的时候,希望参照第一个域进行去重
我们知道-u参数是去重,但是必须两行完全重复才可以,而有时候我们根据一部分来去重。
如果我们只用-u去重:
[root@mufenggrow ~]# sort -u d.txt
lisi: 34
mufeng: 100
mufeng:60
mufeng:99
wangwu: 66
zhangsan: 59
可以看到有三个mufeng结合 -k试一下:
[root@mufenggrow ~]# sort -t: -u -k 1,1 d.txt
lisi: 34
mufeng: 100
wangwu: 66
zhangsan: 59
[root@mufenggrow ~]#可以看到mufeng下面的两个mufeng被去掉了。
这里的 -k 1,1 我们写作 -k start,end , 如果start 第一个域的第一个字符~end 最后一个域的最后一个字符,如果完全相同,仅保留第一次出现的行,后面出现的相同行都会被消除。
5.总结
sort命令在日常工作中,应用的比较广泛,一定要认真学习,记熟记牢常用参数。


















