

今天给大家介绍一个Python用作数据分析的库,使用三行代码即可生成一个完整的数据分析报告,过程中不需要其他额外的代码,零基础也可以学会的方法,是不是很神奇?下面一起学习吧~
本节使用到的库是pandas_profiling库,它可以做延展性的数据探索分析,仅需三行代码即可生成一份具有交互式效果的HTML报告,简单几步就可以实现,轻松实现数据探索分析。
示例工具:anconda3.7
本文讲解内容:三行代码生成数据分析报告
适用范围:pandas_profiling库的使用
数据导入
本节我们导入一组seaborn自带的数据集,先查看seaborn自带数据集的种类。
如下seaborn自带的数据集有20余种,作者已将其下载至本地保存。
数据获取
公众号后台回复
0827
获取本节使用的案例数据
这里我们导入泰坦尼克号数据。

我们首先使用df.describe()函数进行数据探索分析,可以得出平均值、中位数、众数,四分位数等值。

其次使用df.info()可以查看各个字段的数据类型和数据缺失值情况等。

数据探索分析
而使用pandas_profiling库只需要三行代码即可完成包含上述的数据探索分析,并且还有数据的相关性分析、色阶图等等功能,由于anaconda没有自带pandas_profiling库,需要在命令行中输入如下代码下载。
如下使用简单的三行代码即可生成一份数据分析报告。
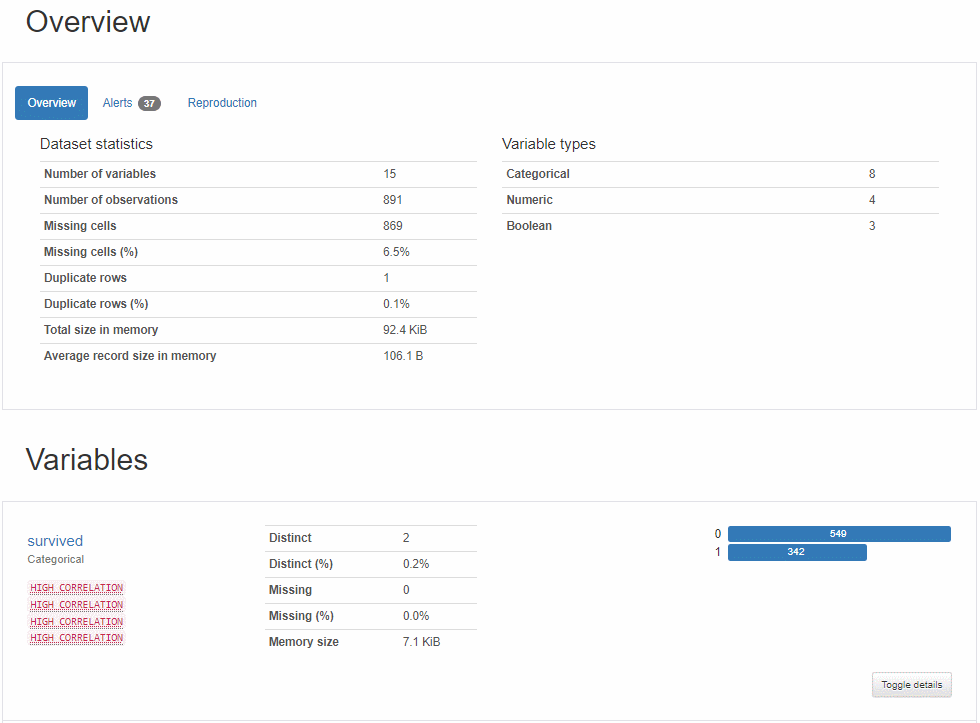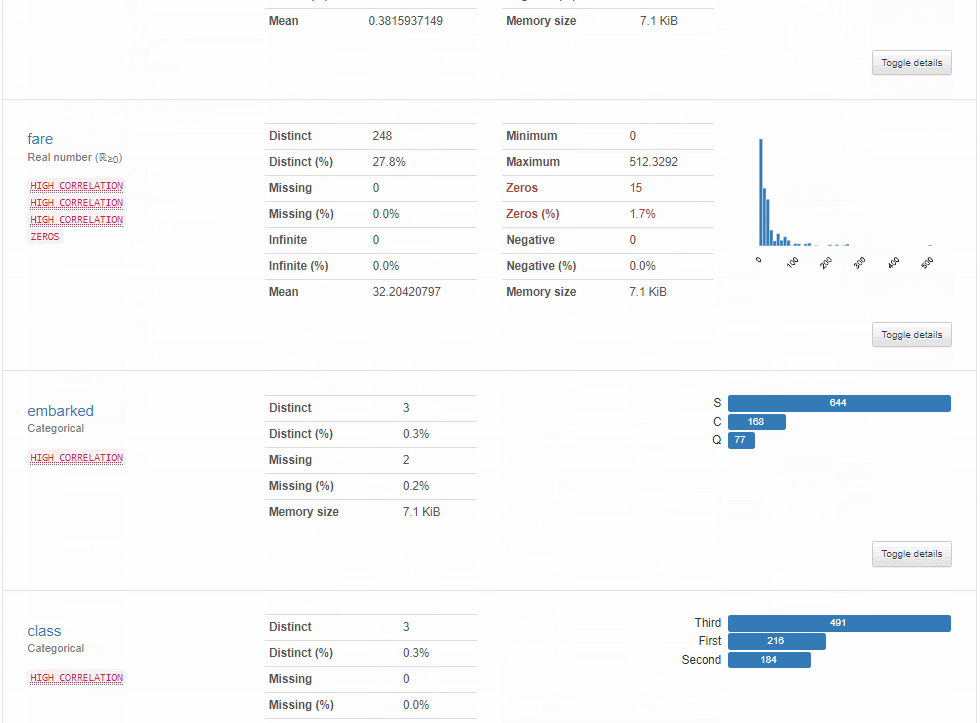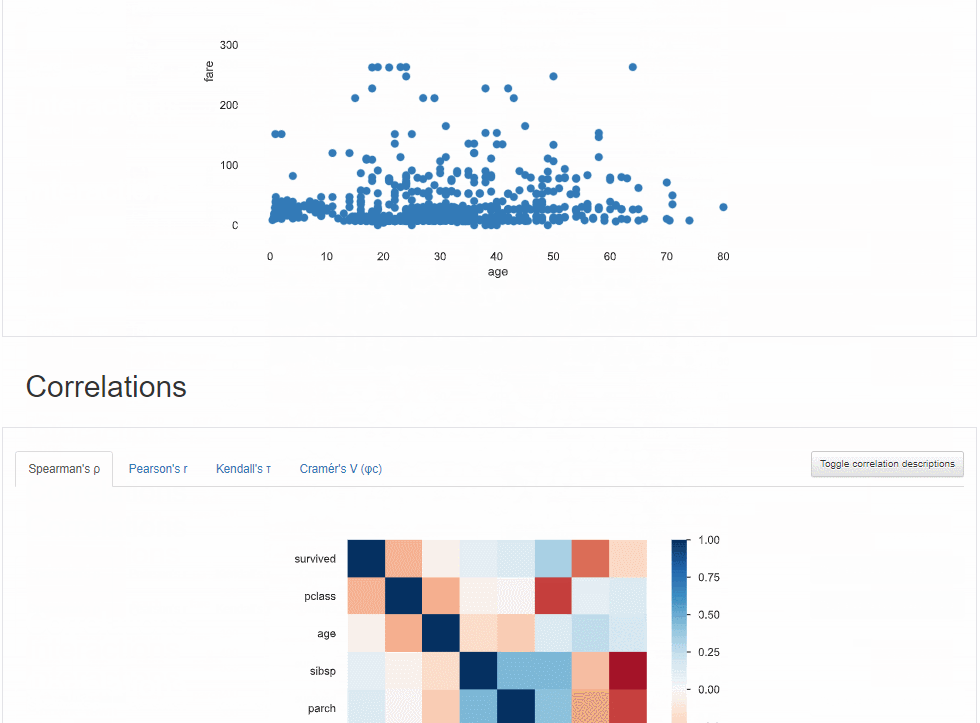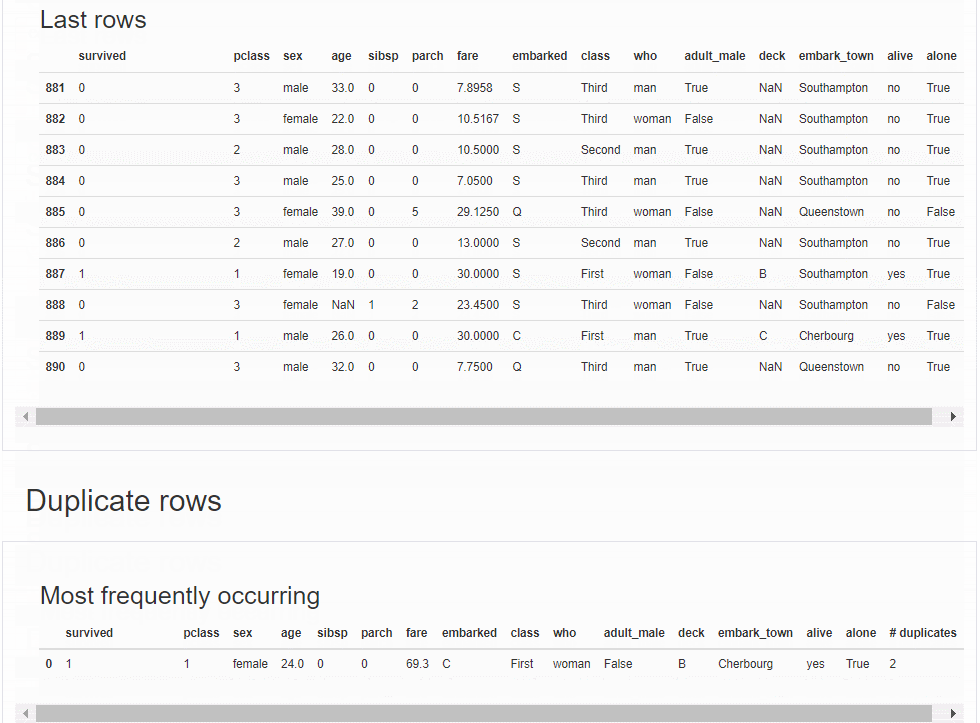
具体的由分析报告可以看出报告大体由五部分组成,分别是数据集的基本信息、数据类型的分布情况、相关性分析可视化、缺失值数据可视化、样本信息展示。
1、数据集的基本信息:包含数据类型、变量数(列)、观察数(行)、数据缺失率、内存信息。

2、数据类型的分布情况:每个变量的详细情况,包括数据类型,分位数统计值、描述性统计值等,这个板块包含的信息最多。

3、相关性分析可视化:突出强相关的变量,使用散点图来可视化数据变量之间的关系。

同样还有Spearman,Pearson矩阵相关性色阶图,也用来可视化数据变量之间的关系。

4、缺失值可视化:对于各个字段的缺失值进行分析,这里也考验我们对于缺失值如何做处理,因为缺失值会影响我们的结果分析,如果说一个字段的缺失比例大于30%,该字段应废弃处理。

5、样本信息展示:突出展示一些样本信息,这里展示前10行数据信息,类似于df.head()的功能,对数据做一个预览。

发现重复行,可以将重复的那一行标记出来。

以上就是三行代码生成数据分析报告的全部内容,感兴趣就敲代码试试吧,如有问题可以评论区留言,每天学习一点代码知识~
后台回复数据分析入门,获取数据分析入门资料
加入数据分析资料群,一起交流数据分析知识
和作者一起学习数据分析!
👆点击关注干货速递👆
三年互联网数据分析经验,擅长Excel、SQL、Python、PowerBI数据处理工具,数据可视化、商业数据分析技能,统计学、机器学习知识,持续创作数据分析内容,点赞关注,不迷路。


















