
OpenCV之Python学习笔记
直都在用Python+OpenCV做一些算法的原型。本来想留下发布一些文章的,可是整理一下就有点无奈了,都是写零散不成系统的小片段。现在看 到一本国外的新书《OpenCV Computer Vision with Python》,于是就看一遍,顺便把自己掌握的东西整合一下,写成学习笔记了。更需要的朋友参考。
阅读须知:
本文不是纯粹的译文,只是比较贴近原文的笔记;
请设法购买到出版社出版的书,支持正版。
从书名就能看出来本书是介绍在Python中使用OpenCV,全书分为5章,两个附录:
- 第一章OpenCV设置,介绍如何在Windows、Mac和Ubuntu上设置Pyhton、OpenCV和相关库的环境。还讨论了OpenCV社区、OpenCV文档以及官方的示例代码。
- 第二章处理文件、摄像头和GUI,讨论OpenCV的I/O功能,接着使用面向对象的设计编写一个主应用程序,用于显示摄像头实时场景、处理键盘输入、将摄像头写入视频文件和静态图像文件。
- 第三章图像过滤,介绍使用OpenCV、NumPy和SciPy来编写图像过滤器。过滤器可用于线性颜色操作、曲线颜色操作、模糊化、锐化和寻找边缘。本章修改第一章的主程序,将过滤器应用到实时摄像头场景中。
- 第四章使用Haar Cascades追踪人脸,本章将编写一个层次化的人脸追踪器,使用OpenCV定位图像中的脸部、眼睛、鼻子和嘴巴。同时还编写了用于复制和改变图像中某块区域的大小。同样,本章也将修改之前的主应用程序,让其可以用于找到并处理摄像头场景中的人脸。
- 第五章检测前景/背景区域和深度。通过本章将了解有关OpenCV(在OpenNI和SensorKinect的支持下)从深度摄像头中获得的数据类型的信息。接着编写一些函数,使用这些数据对前景区域施加一些限制效果。最后将这些函数整合到主程序中,使得在处理人脸之前先进行细化操作。
- 附录A,与Pygame整合。修改主程序,用Pygame替换OpenCV来处理特定的I/O事件。(Pygame提供了更多样的事件处理函数。)
- 附录B,为自定义目标生成Haar Cascades,允许我们检测一系列的OpenCV工具,来对任何类型的目标或模式构建跟踪器,而不仅仅是人脸。
OpenCV Python教程(1、图像的载入、显示和保存)
本文是OpenCV 2 Computer Vision Application Programming Cookbook读书笔记的第一篇。在笔记中将以Python语言改写每章的代码。
PythonOpenCV的配置这里就不介绍了。
注意,现在OpenCV for Python就是通过NumPy进行绑定的。所以在使用时必须掌握一些NumPy的相关知识!
图像就是一个矩阵,在OpenCV for Python中,图像就是NumPy中的数组!
如果读取图像首先要导入OpenCV包,方法为:
[python] view plain copy
- import cv2
读取并显示图像
在Python中不需要声明变量,所以也就不需要C++中的cv::Mat xxxxx了。只需这样:
[python] view plain copy
- img = cv2.imread("D:\cat.jpg")
OpenCV目前支持读取bmp、jpg、png、tiff等常用格式。更详细的请参考OpenCV的参考文档。
接着创建一个窗口
[python] view plain copy
- cv2.namedWindow("Image")
然后在窗口中显示图像
[python] view plain copy
- cv2.imshow("Image", img)
最后还要添上一句:
[python] view plain copy
- cv2.waitKey (0)
如果不添最后一句,在IDLE中执行窗口直接无响应。在命令行中执行的话,则是一闪而过。
完整的程序为:
[python] view plain copy
- import cv2
- img = cv2.imread("D:\\cat.jpg")
- cv2.namedWindow("Image")
- cv2.imshow("Image", img)
- cv2.waitKey (0)
- cv2.destroyAllWindows()
最后释放窗口是个好习惯!
创建/复制图像
新的OpenCV的接口中没有CreateImage接口。即没有cv2.CreateImage这样的函数。如果要创建图像,需要使用numpy的函数(现在使用OpenCV-Python绑定,numpy是必装的)。如下:
[python] view plain copy
- emptyImage = np.zeros(img.shape, np.uint8)
在新的OpenCV-Python绑定中,图像使用NumPy数组的属性来表示图像的尺寸和通道信息。如果输出img.shape,将得到(500, 375, 3),这里是以OpenCV自带的cat.jpg为示例。最后的3表示这是一个RGB图像。
也可以复制原有的图像来获得一副新图像。
[python] view plain copy
- emptyImage2 = img.copy();
如果不怕麻烦,还可以用cvtColor获得原图像的副本。
[python] view plain copy
- emptyImage3=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
- #emptyImage3[…]=0
后面的emptyImage3[…]=0是将其转成空白的黑色图像。
保存图像
保存图像很简单,直接用cv2.imwrite即可。
cv2.imwrite("D:\\cat2.jpg", img)
第一个参数是保存的路径及文件名,第二个是图像矩阵。其中,imwrite()有个可选的第三个参数,如下:
cv2.imwrite("D:\\cat2.jpg", img,[int(cv2.IMWRITE_JPEG_QUALITY), 5])
第三个参数针对特定的格式: 对于JPEG,其表示的是图像的质量,用0-100的整数表示,默认为95。 注意,cv2.IMWRITE_JPEG_QUALITY类型为Long,必须转换成int。下面是以不同质量存储的两幅图:

对于PNG,第三个参数表示的是压缩级别。cv2.IMWRITE_PNG_COMPRESSION,从0到9,压缩级别越高,图像尺寸越小。默认级别为3:
[python] view plain copy
- cv2.imwrite("./cat.png", img, [int(cv2.IMWRITE_PNG_COMPRESSION), 0])
- cv2.imwrite("./cat2.png", img, [int(cv2.IMWRITE_PNG_COMPRESSION), 9])
保存的图像尺寸如下:

还有一种支持的图像,一般不常用。
完整的代码为:
[python] view plain copy
- import cv2
- import numpy as np
- img = cv2.imread("./cat.jpg")
- emptyImage = np.zeros(img.shape, np.uint8)
- emptyImage2 = img.copy()
- emptyImage3=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
- #emptyImage3[…]=0
- cv2.imshow("EmptyImage", emptyImage)
- cv2.imshow("Image", img)
- cv2.imshow("EmptyImage2", emptyImage2)
- cv2.imshow("EmptyImage3", emptyImage3)
- cv2.imwrite("./cat2.jpg", img, [int(cv2.IMWRITE_JPEG_QUALITY), 5])
- cv2.imwrite("./cat3.jpg", img, [int(cv2.IMWRITE_JPEG_QUALITY), 100])
- cv2.imwrite("./cat.png", img, [int(cv2.IMWRITE_PNG_COMPRESSION), 0])
- cv2.imwrite("./cat2.png", img, [int(cv2.IMWRITE_PNG_COMPRESSION), 9])
- cv2.waitKey (0)
- cv2.destroyAllWindows()
参考资料:
《OpenCV References Manuel》
《OpenCV 2 Computer Vision Application Programming Cookbook》
《OpenCV Computer Vision with Python》
OpenCV Python教程(2、图像元素的访问、通道分离与合并)
访问像素
像素的访问和访问numpy中ndarray的方法完全一样,灰度图为:
[python] view plain copy
- img[j,i] = 255
其中j,i分别表示图像的行和列。对于BGR图像,为:
[python] view plain copy
- img[j,i,0]= 255
- img[j,i,1]= 255
- img[j,i,2]= 255
第三个数表示通道。
下面通过对图像添加人工的椒盐现象来进一步说明OpenCV Python中需要注意的一些问题。完整代码如下:
[python] view plain copy
- import cv2
- import numpy as np
- def salt(img, n):
- for k in range(n):
- 1]);
- 0]);
- if img.ndim == 2:
- 255
- elif img.ndim == 3:
- 0]= 255
- 1]= 255
- 2]= 255
- return img
- if __name__ == ‘__main__’:
- "图像路径")
- 500)
- "Salt", saltImage)
- 0)
- cv2.destroyAllWindows()
处理后能得到类似下面这样带有模拟椒盐现象的图片:

上面的代码需要注意几点:
1、与C++不同,在Python中灰度图的img.ndim = 2,而C++中灰度图图像的通道数img.channel() =1
2、为什么使用np.random.random()?
这里使用了numpy的随机数,Python自身也有一个随机数生成函数。这里只是一种习惯,np.random模块中拥有更多的方法,而Python自 带的random只是一个轻量级的模块。不过需要注意的是np.random.seed()不是线程安全的,而Python自带的 random.seed()是线程安全的。如果使用随机数时需要用到多线程,建议使用Python自带的random()和random.seed(), 或者构建一个本地的np.random.Random类的实例。
分离、合并通道
由于OpenCV Python和NumPy结合的很紧,所以即可以使用OpenCV自带的split函数,也可以直接操作numpy数组来分离通道。直接法为:
[python] view plain copy
- import cv2
- import numpy as np
- img = cv2.imread("D:/cat.jpg")
- b, g, r = cv2.split(img)
- cv2.imshow("Blue", r)
- cv2.imshow("Red", g)
- cv2.imshow("Green", b)
- cv2.waitKey(0)
- cv2.destroyAllWindows()
其中split返回RGB三个通道,如果只想返回其中一个通道,可以这样:
[python] view plain copy
- b = cv2.split(img)[0]
- g = cv2.split(img)[1]
- r = cv2.split(img)[2]
最后的索引指出所需要的通道。
也可以直接操作NumPy数组来达到这一目的:
[python] view plain copy
- import cv2
- import numpy as np
- img = cv2.imread("D:/cat.jpg")
- b = np.zeros((img.shape[0],img.shape[1]), dtype=img.dtype)
- g = np.zeros((img.shape[0],img.shape[1]), dtype=img.dtype)
- r = np.zeros((img.shape[0],img.shape[1]), dtype=img.dtype)
- b[:,:] = img[:,:,0]
- g[:,:] = img[:,:,1]
- r[:,:] = img[:,:,2]
- cv2.imshow("Blue", r)
- cv2.imshow("Red", g)
- cv2.imshow("Green", b)
- cv2.waitKey(0)
- cv2.destroyAllWindows()
注意先要开辟一个相同大小的图片出来。这是由于numpy中数组的复制有些需要注意的地方,具体事例如下:
[python] view plain copy
- >>> c= np.zeros(img.shape, dtype=img.dtype)
- >>> c[:,:,:] = img[:,:,:]
- >>> d[:,:,:] = img[:,:,:]
- >>> c is a
- False
- >>> d is a
- False
- >>> c.base is a
- False
- >>> d.base is a #注意这里!!!
- True
这里,d只是a的镜像,具体请参考《NumPy简明教程(二,数组3)》中的“复制和镜像”一节。
通道合并
同样,通道合并也有两种方法。第一种是OpenCV自带的merge函数,如下:
[python] view plain copy
- merged = cv2.merge([b,g,r]) #前面分离出来的三个通道
接着是NumPy的方法:
[python] view plain copy
- mergedByNp = np.dstack([b,g,r])
注意:这里只是演示,实际使用时请用OpenCV自带的merge函数!用NumPy组合的结果不能在OpenCV中其他函数使用,因为其组合方式与OpenCV自带的不一样,如下:
[python] view plain copy
- merged = cv2.merge([b,g,r])
- print "Merge by OpenCV"
- print merged.strides
- mergedByNp = np.dstack([b,g,r])
- print "Merge by NumPy "
- print mergedByNp.strides
结果为:
[python] view plain copy
- Merge by OpenCV
- (1125, 3, 1)
- Merge by NumPy
- (1, 500, 187500)
NumPy数组的strides属性表示的是在每个维数上以字节计算的步长。这怎么理解呢,看下面这个简单点的例子:
[python] view plain copy
- >>> a = np.arange(6)
- >>> a
- array([0, 1, 2, 3, 4, 5])
- >>> a.strides
- (4,)
a数组中每个元素都是NumPy中的整数类型,占4个字节,所以第一维中相邻元素之间的步长为4(个字节)。
同样,2维数组如下:
[python] view plain copy
- >>> b = np.arange(12).reshape(3,4)
- >>> b
- array([[ 0, 1, 2, 3],
- 4, 5, 6, 7],
- 8, 9, 10, 11]])
- >>> b.strides
- (16, 4)
从里面开始看,里面是一个4个元素的一维整数数组,所以步长应该为4。外面是一个含有3个元素,每个元素的长度是4×4=16。所以步长为16。
下面来看下3维数组:
[python] view plain copy
- >>> c = np.arange(27).reshape(3,3,3)
其结果为:
[python] view plain copy
- array([[[ 0, 1, 2],
- 3, 4, 5],
- 6, 7, 8]],
- 9, 10, 11],
- 12, 13, 14],
- 15, 16, 17]],
- 18, 19, 20],
- 21, 22, 23],
- 24, 25, 26]]])
根据前面了解的,推断下这个数组的步长。从里面开始算,应该为(3×4×3,3×4,4)。验证一下:
[python] view plain copy
- >>> c.strides
- (36, 12, 4)
完整的代码为:
[python] view plain copy
- import cv2
- import numpy as np
- img = cv2.imread("D:/cat.jpg")
- b = np.zeros((img.shape[0],img.shape[1]), dtype=img.dtype)
- g = np.zeros((img.shape[0],img.shape[1]), dtype=img.dtype)
- r = np.zeros((img.shape[0],img.shape[1]), dtype=img.dtype)
- b[:,:] = img[:,:,0]
- g[:,:] = img[:,:,1]
- r[:,:] = img[:,:,2]
- merged = cv2.merge([b,g,r])
- print "Merge by OpenCV"
- print merged.strides
- print merged
- mergedByNp = np.dstack([b,g,r])
- print "Merge by NumPy "
- print mergedByNp.strides
- print mergedByNp
- cv2.imshow("Merged", merged)
- cv2.imshow("MergedByNp", merged)
- cv2.imshow("Blue", b)
- cv2.imshow("Red", r)
- cv2.imshow("Green", g)
- cv2.waitKey(0)
- cv2.destroyAllWindows()
OpenCV Python教程(3、直方图的计算与显示)
本篇文章介绍如何用OpenCV Python来计算直方图,并简略介绍用NumPy和Matplotlib计算和绘制直方图
直方图的背景知识、用途什么的就直接略过去了。这里直接介绍方法。
计算并显示直方图
与C++中一样,在Python中调用的OpenCV直方图计算函数为cv2.calcHist。
cv2.calcHist的原型为:
[python] view plain copy
- cv2.calcHist(images, channels, mask, histSize, ranges[, hist[, accumulate ]]) #返回hist
通过一个例子来了解其中的各个参数:
[python] view plain copy
- #coding=utf-8
- import cv2
- import numpy as np
- image = cv2.imread("D:/histTest.jpg", 0)
- hist = cv2.calcHist([image],
- 0], #使用的通道
- None, #没有使用mask
- 256], #HistSize
- 0.0,255.0]) #直方图柱的范围
其中第一个参数必须用方括号括起来。
第二个参数是用于计算直方图的通道,这里使用灰度图计算直方图,所以就直接使用第一个通道;
第三个参数是Mask,这里没有使用,所以用None。
第四个参数是histSize,表示这个直方图分成多少份(即多少个直方柱)。第二个例子将绘出直方图,到时候会清楚一点。
第五个参数是表示直方图中各个像素的值,[0.0, 256.0]表示直方图能表示像素值从0.0到256的像素。
最后是两个可选参数,由于直方图作为函数结果返回了,所以第六个hist就没有意义了(待确定)
最后一个accumulate是一个布尔值,用来表示直方图是否叠加。
彩色图像不同通道的直方图
彩色图像不同通道的直方图
下面来看下彩色图像的直方图处理。以最著名的lena.jpg为例,首先读取并分离各通道:
[python] view plain copy
- import cv2
- import numpy as np
- img = cv2.imread("D:/lena.jpg")
- b, g, r = cv2.split(img)
接着计算每个通道的直方图,这里将其封装成一个函数:
[python] view plain copy
- def calcAndDrawHist(image, color):
- 0], None, [256], [0.0,255.0])
- minVal, maxVal, minLoc, maxLoc = cv2.minMaxLoc(hist)
- 256,256,3], np.uint8)
- 0.9* 256);
- for h in range(256):
- intensity = int(hist[h]*hpt/maxVal)
- 256), (h,256-intensity), color)
- return histImg;
这里只是之前代码的简单封装,所以注释就省掉了。
接着在主函数中使用:
[python] view plain copy
- if __name__ == ‘__main__’:
- "D:/lena.jpg")
- b, g, r = cv2.split(img)
- 255, 0, 0])
- 0, 255, 0])
- 0, 0, 255])
- "histImgB", histImgB)
- "histImgG", histImgG)
- "histImgR", histImgR)
- "Img", img)
- 0)
- cv2.destroyAllWindows()
这样就能得到三个通道的直方图了,如下:

更进一步
这样做有点繁琐,参考abid rahman的做法,无需分离通道,用折线来描绘直方图的边界可在一副图中同时绘制三个通道的直方图。方法如下:
- #coding=utf-8
- import cv2
- import numpy as np
- img = cv2.imread(‘D:/lena.jpg’)
- h = np.zeros((256,256,3)) #创建用于绘制直方图的全0图像
- bins = np.arange(256).reshape(256,1) #直方图中各bin的顶点位置
- color = [ (255,0,0),(0,255,0),(0,0,255) ] #BGR三种颜色
- for ch, col in enumerate(color):
- None,[256],[0,256])
- 0,255*0.9,cv2.NORM_MINMAX)
- hist=np.int32(np.around(originHist))
- pts = np.column_stack((bins,hist))
- False,col)
- h=np.flipud(h)
- cv2.imshow(‘colorhist’,h)
- cv2.waitKey(0)
结果如下图所示:

代码说明:
这里的for循环是对三个通道遍历一次,每次绘制相应通道的直方图的折线。for循环的第一行是计算对应通道的直方图,经过上面的介绍,应该很容易就能明白。
这里所不同的是没有手动的计算直方图的最大值再乘以一个系数,而是直接调用了OpenCV的归一化函数。该函数将直方图的范围限定在 0-255×0.9之间,与之前的一样。下面的hist= np.int32(np.around(originHist))先将生成的原始直方图中的每个元素四舍六入五凑偶取整(cv2.calcHist函数得 到的是float32类型的数组),接着将整数部分转成np.int32类型。即61.123先转成61.0,再转成61。注意,这里必须使用 np.int32(…)进行转换,numpy的转换函数可以对数组中的每个元素都进行转换,而Python的int(…)只能转换一个元素,如果 使用int(…),将导致only length-1 arrays can be converted to Python scalars错误。
下面的pts = np.column_stack((bins,hist))是将直方图中每个bin的值转成相应的坐标。比如hist[0] =3,…,hist[126] = 178,…,hist[255] = 5;而bins的值为[[0],[1],[2]…,[255]]。使用np.column_stack将其组合成[0, 3]、[126, 178]、[255, 5]这样的坐标作为元素组成的数组。
最后使用cv2.polylines函数根据这些点绘制出折线,第三个False参数指出这个折线不需要闭合。第四个参数指定了折线的颜色。
当所有完成后,别忘了用h = np.flipud(h)反转绘制好的直方图,因为绘制时,[0,0]在图像的左上角。这在直方图可视化一节中有说明。
NumPy版的直方图计算
在查阅abid rahman的资料时,发现他用NumPy的直方图计算函数np.histogram也实现了相同的效果。如下:
[python] view plain copy
- #coding=utf-8
- import cv2
- import numpy as np
- img = cv2.imread(‘D:/lena.jpg’)
- h = np.zeros((300,256,3))
- bins = np.arange(257)
- bin = bins[0:-1]
- color = [ (255,0,0),(0,255,0),(0,0,255) ]
- for ch,col in enumerate(color):
- item = img[:,:,ch]
- N,bins = np.histogram(item,bins)
- v=N.max()
- 255)/v))
- 256,1)
- pts = np.column_stack((bin,N))
- False,col)
- h=np.flipud(h)
- cv2.imshow(‘img’,h)
- cv2.waitKey(0)
效果图和上面的一个相同。NumPy的histogram函数将在NumPy通用函数这篇博文中介绍,这里就不详细解释了。这里采用的是与一开始相同的比例系数的方法,参考本文的第二节。
另外,通过NumPy和matplotlib可以更方便的绘制出直方图,下面的代码供大家参考,如果有机会,再写的专门介绍matplotlib的文章。
[python] view plain copy
- import matplotlib.pyplot as plt
- import numpy as np
- import cv2
- img = cv2.imread(‘D:/lena.jpg’)
- bins = np.arange(257)
- item = img[:,:,1]
- hist,bins = np.histogram(item,bins)
- width = 0.7*(bins[1]-bins[0])
- center = (bins[:-1]+bins[1:])/2
- plt.bar(center, hist, align = ‘center’, width = width)
- plt.show()

这里显示的是绿色通道的直方图。
未完待续。。。如有错误请指正,本人会虚心接受并改正!谢谢!
OpenCV-Python教程(4、形态学处理)
- 本文介绍使用OpenCV-Python进行形态学处理
- 本文不介绍形态学处理的基本概念,所以读者需要预先对其有一定的了解。
定义结构元素
形态学处理的核心就是定义结构元素,在OpenCV-Python中,可以使用其自带的getStructuringElement函数,也可以直 接使用NumPy的ndarray来定义一个结构元素。首先来看用getStructuringElement函数定义一个结构元素:
[python] view plain copy
- element = cv2.getStructuringElement(cv2.MORPH_CROSS,(5,5))
这就定义了一个5×5的十字形结构元素,如下:

也可以用NumPy来定义结构元素,如下:
[python] view plain copy
- NpKernel = np.uint8(np.zeros((5,5)))
- for i in range(5):
- 2, i] = 1 #感谢chenpingjun1990的提醒,现在是正确的
- 2] = 1
这两者方式定义的结构元素完全一样:
[python] view plain copy
- [[0 0 1 0 0]
- 0 0 1 0 0]
- 1 1 1 1 1]
- 0 0 1 0 0]
- 0 0 1 0 0]]
这里可以看出,用OpenCV-Python内置的常量定义椭圆(MORPH_ELLIPSE)和十字形结构(MORPH_CROSS)元素要简单一些,如果定义矩形(MORPH_RECT)和自定义结构元素,则两者差不多。
本篇文章将用参考资料1中的相关章节的图片做测试:

腐蚀和膨胀
下面先以腐蚀图像为例子介绍如何使用结构元素:
[python] view plain copy
- #coding=utf-8
- import cv2
- import numpy as np
- img = cv2.imread(‘D:/binary.bmp’,0)
- #OpenCV定义的结构元素
- kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(3, 3))
- #腐蚀图像
- eroded = cv2.erode(img,kernel)
- #显示腐蚀后的图像
- cv2.imshow("Eroded Image",eroded);
- #膨胀图像
- dilated = cv2.dilate(img,kernel)
- #显示膨胀后的图像
- cv2.imshow("Dilated Image",dilated);
- #原图像
- cv2.imshow("Origin", img)
- #NumPy定义的结构元素
- NpKernel = np.uint8(np.ones((3,3)))
- Nperoded = cv2.erode(img,NpKernel)
- #显示腐蚀后的图像
- cv2.imshow("Eroded by NumPy kernel",Nperoded);
- cv2.waitKey(0)
- cv2.destroyAllWindows()
如上所示,腐蚀和膨胀的处理很简单,只需设置好结构元素,然后分别调用cv2.erode(…)和cv2.dilate(…)函数即可,其中第一个参数是需要处理的图像,第二个是结构元素。返回处理好的图像。
结果如下:

开运算和闭运算
了解形态学基本处理的同学都知道,开运算和闭运算就是将腐蚀和膨胀按照一定的次序进行处理。但这两者并不是可逆的,即先开后闭并不能得到原先的图像。代码示例如下:
[python] view plain copy
- #coding=utf-8
- import cv2
- import numpy as np
- img = cv2.imread(‘D:/binary.bmp’,0)
- #定义结构元素
- kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(5, 5))
- #闭运算
- closed = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)
- #显示腐蚀后的图像
- cv2.imshow("Close",closed);
- #开运算
- opened = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)
- #显示腐蚀后的图像
- cv2.imshow("Open", opened);
- cv2.waitKey(0)
- cv2.destroyAllWindows()
闭运算用来连接被误分为许多小块的对象,而开运算用于移除由图像噪音形成的斑点。因此,某些情况下可以连续运用这两种运算。如对一副二值图连续使用 闭运算和开运算,将获得图像中的主要对象。同样,如果想消除图像中的噪声(即图像中的“小点”),也可以对图像先用开运算后用闭运算,不过这样也会消除一 些破碎的对象。
对原始图像进行开运算和闭运算的结果如下:

用形态学运算检测边和角点
这里通过一个较复杂的例子介绍如何用形态学算子检测图像中的边缘和拐角(这里只是作为介绍形态学处理例子,实际使用时请用Canny或Harris等算法)。
检测边缘
形态学检测边缘的原理很简单,在膨胀时,图像中的物体会想周围“扩张”;腐蚀时,图像中的物体会“收缩”。比较这两幅图像,由于其变化的区域只发生在边缘。所以这时将两幅图像相减,得到的就是图像中物体的边缘。这里用的依然是参考资料1中相关章节的图片:

代码如下:
[python] view plain copy
- #coding=utf-8
- import cv2
- import numpy
- image = cv2.imread("D:/building.jpg",0);
- #构造一个3×3的结构元素
- element = cv2.getStructuringElement(cv2.MORPH_RECT,(3, 3))
- dilate = cv2.dilate(image, element)
- erode = cv2.erode(image, element)
- #将两幅图像相减获得边,第一个参数是膨胀后的图像,第二个参数是腐蚀后的图像
- result = cv2.absdiff(dilate,erode);
- #上面得到的结果是灰度图,将其二值化以便更清楚的观察结果
- retval, result = cv2.threshold(result, 40, 255, cv2.THRESH_BINARY);
- #反色,即对二值图每个像素取反
- result = cv2.bitwise_not(result);
- #显示图像
- cv2.imshow("result",result);
- cv2.waitKey(0)
- cv2.destroyAllWindows()
处理结果如下:

检测拐角
与边缘检测不同,拐角的检测的过程稍稍有些复杂。但原理相同,所不同的是先用十字形的结构元素膨胀像素,这种情况下只会在边缘处“扩张”,角点不发生变化。接着用菱形的结构元素腐蚀原图像,导致只有在拐角处才会“收缩”,而直线边缘都未发生变化。
第二步是用X形膨胀原图像,角点膨胀的比边要多。这样第二次用方块腐蚀时,角点恢复原状,而边要腐蚀的更多。所以当两幅图像相减时,只保留了拐角处。示意图如下(示意图来自参考资料1):

代码如下:
[python] view plain copy
- #coding=utf-8
- import cv2
- image = cv2.imread("D:/building.jpg", 0)
- origin = cv2.imread("D:/building.jpg")
- #构造5×5的结构元素,分别为十字形、菱形、方形和X型
- cross = cv2.getStructuringElement(cv2.MORPH_CROSS,(5, 5))
- #菱形结构元素的定义稍麻烦一些
- diamond = cv2.getStructuringElement(cv2.MORPH_RECT,(5, 5))
- diamond[0, 0] = 0
- diamond[0, 1] = 0
- diamond[1, 0] = 0
- diamond[4, 4] = 0
- diamond[4, 3] = 0
- diamond[3, 4] = 0
- diamond[4, 0] = 0
- diamond[4, 1] = 0
- diamond[3, 0] = 0
- diamond[0, 3] = 0
- diamond[0, 4] = 0
- diamond[1, 4] = 0
- square = cv2.getStructuringElement(cv2.MORPH_RECT,(5, 5))
- x = cv2.getStructuringElement(cv2.MORPH_CROSS,(5, 5))
- #使用cross膨胀图像
- result1 = cv2.dilate(image,cross)
- #使用菱形腐蚀图像
- result1 = cv2.erode(result1, diamond)
- #使用X膨胀原图像
- result2 = cv2.dilate(image, x)
- #使用方形腐蚀图像
- result2 = cv2.erode(result2,square)
- #result = result1.copy()
- #将两幅闭运算的图像相减获得角
- result = cv2.absdiff(result2, result1)
- #使用阈值获得二值图
- retval, result = cv2.threshold(result, 40, 255, cv2.THRESH_BINARY)
- #在原图上用半径为5的圆圈将点标出。
- for j in range(result.size):
- 0]
- 0]
- if result[x, y] == 255:
- 5, (255,0,0))
- cv2.imshow("Result", image)
- cv2.waitKey(0)
- cv2.destroyAllWindows()
注意,由于封装的缘故,OpenCV中函数参数中使用的坐标系和NumPy的ndarray的坐标系是不同的,在46行可以看出来。抽空我向OpenCV邮件列表提一下,看我的理解是不是正确的。
大家可以验证一下,比如在代码中插入这两行代码,就能知道结果了:
[python] view plain copy
- cv2.circle(image, (5, 10), 5, (255,0,0))
- image[5, 10] = 0
通过上面的代码就能检测到图像中的拐角并标出来,效果图如下:

当然,这只是个形态学处理示例,检测结果并不好。
未完待续…
在将来的某一篇文章中将做个总结,介绍下OpenCV中常用的函数,如threshold、bitwise_xxx,以及绘制函数等。
参考资料:
1、《Opencv2 Computer Vision Application Programming Cookbook》
2、《OpenCV References Manule》
如果觉得本文写的还可以的话,请轻点“顶”,方便读者、以及您的支持是我写下去的最大的两个动力。
OpenCV-Python教程(5、初级滤波内容)
简介
过滤是信号和图像处理中基本的任务。其目的是根据应用环境的不同,选择性的提取图像中某些认为是重要的信息。过滤可以移除图像中的噪音、提取感兴趣 的可视特征、允许图像重采样,等等。其源自于一般的信号和系统理论,这里将不介绍该理论的细节。但本章会介绍关于过滤的基本概念,以及如何在图像处理程序 中使用滤波器。首先,简要介绍下频率域分析的概念。
当我们观察一张图片时,我们观察的是图像中有多少灰度级(或颜色)及其分布。根据灰度分布的不同来区分不同的图像。但还有其他方面可以对图像进行分 析。我们可以观察图像中灰度的变化。某些图像中包含大量的强度不变的区域(如蓝天),而在其他图像中的灰度变化可能会非常快(如包含许多小物体的拥挤的图 像)。因此,观察图像中这些变化的频率就构成了另一条分类图像的方法。这个观点称为频域。而通过观察图像灰度分布来分类图像称为空间域。
频域分析将图像分成从低频到高频的不同部分。低频对应图像强度变化小的区域,而高频是图像强度变化非常大的区域。目前已存在若干转换方法,如傅立叶 变换或余弦变换,可以用来清晰的显示图像的频率内容。注意,由于图像是一个二维实体,所以其由水平频率(水平方向的变化)和竖直频率(竖直方向的变化)共 同组成。
在频率分析领域的框架中,滤波器是一个用来增强图像中某个波段或频率并阻塞(或降低)其他频率波段的操作。低通滤波器是消除图像中高频部分,但保留低频部分。高通滤波器消除低频部分
本篇文章介绍在OpenCV-Python中实现的初级的滤波操作,下一篇文章介绍更加复杂的滤波原理及其实现。
本篇文章使用传统的lena作为实验图像。
用低通滤波来平滑图像
低通滤波器的目标是降低图像的变化率。如将每个像素替换为该像素周围像素的均值。这样就可以平滑并替代那些强度变化明显的区域。在OpenCV中,可以通过blur函数做到这一点:
[python] view plain copy
- dst = cv2.blur(image,(5,5));
其中dst是blur处理后返回的图像,参数一是输入的待处理图像,参数2是低通滤波器的大小。其后含有几个可选参数,用来设置滤波器的细节,具体可查阅参考资料2。不过这里,这样就够了。下面是一个简单的示例代码:
[python] view plain copy
- #coding=utf-8
- import cv2
- img = cv2.imread("D:/lena.jpg", 0)
- result = cv2.blur(img, (5,5))
- cv2.imshow("Origin", img)
- cv2.imshow("Blur", result)
- cv2.waitKey(0)
- cv2.destroyAllWindows()
结果如下,左边是平滑过的图像,右边是原图像:

这种滤波器又称为boxfilter(注,这与化学上的箱式过滤器是两码事,所以这里就不翻译了)。所以也可通过OpenCV的cv2.bofxfilter(…)函数来完成相同的工作。如下:
[python] view plain copy
- result1 = cv2.boxFilter(img, –1, (5, 5))
这行代码与上面使用blur函数的效果完全相同。其中第二个参数的-1表示输出图像使用的深度与输入图像相同。后面还有几个可选参数,具体可查阅OpenCV文档。
高斯模糊
在某些情况下,需要对一个像素的周围的像素给予更多的重视。因此,可通过分配权重来重新计算这些周围点的值。这可通过高斯函数(钟形函数,即喇叭形数)的权重方案来解决。cv::GaussianBlur函数可作为滤波器用下面的方法调用:
[python] view plain copy
- gaussianResult = cv2.GaussianBlur(img,(5,5),1.5)
区别
低通滤波与高斯滤波的不同之处在于:低通滤波中,滤波器中每个像素的权重是相同的,即滤波器是线性的。而高斯滤波器中像素的权重与其距中心像素的距离成比例。关于高斯模糊的详细内容,抽空将写一篇独立的文章介绍。
使用中值滤波消除噪点
前面介绍的是线性过滤器,这里介绍非线性过滤器——中值滤波器。由于中值滤波器对消除椒盐现象特别有用。所以我们使用第二篇教程中椒盐函数先对图像进行处理,将处理结果作为示例图片。
调用中值滤波器的方法与调用其他滤波器的方法类似,如下:
[python] view plain copy
- result = cv2.medianBlur(image,5)
函数返回处理结果,第一个参数是待处理图像,第二个参数是孔径的尺寸,一个大于1的奇数。比如这里是5,中值滤波器就会使用5×5的范围来计算。即对像素的中心值及其5×5邻域组成了一个数值集,对其进行处理计算,当前像素被其中值替换掉。
如果在某个像素周围有白色或黑色的像素,这些白色或黑色的像素不会选择作为中值(最大或最小值不用),而是被替换为邻域值。代码如下:
[python] view plain copy
- #coding=utf-8
- import cv2
- import numpy as np
- def salt(img, n):
- for k in range(n):
- 1]);
- 0]);
- if img.ndim == 2:
- 255
- elif img.ndim == 3:
- 0]= 255
- 1]= 255
- 2]= 255
- return img
- img = cv2.imread("D:/lena.jpg", 0)
- result = salt(img, 500)
- median = cv2.medianBlur(result, 5)
- cv2.imshow("Salt", result)
- cv2.imshow("Median", median)
- cv2.waitKey(0)
处理结果如下:

由于中值滤波不会处理最大和最小值,所以就不会受到噪声的影响。相反,如果直接采用blur进行均值滤波,则不会区分这些噪声点,滤波后的图像会受到噪声的影响。
中值滤波器在处理边缘也有优势。但中值滤波器会清除掉某些区域的纹理(如背景中的树)。
其他
由于方向滤波器与这里的原理有较大的出入,所以将用独立的一篇文章中介绍其原理以及实现。
参考资料:
1、《Opencv2 Computer Vision Application Programming Cookbook》
2、《OpenCV References Manule》
OpenCV-Python教程(6、Sobel算子)
Sobel算子
原型
Sobel算子依然是一种过滤器,只是其是带有方向的。在OpenCV-Python中,使用Sobel的算子的函数原型如下:
[python] view plain copy
- dst = cv2.Sobel(src, ddepth, dx, dy[, dst[, ksize[, scale[, delta[, borderType]]]]])
函数返回其处理结果。
前四个是必须的参数:
- 第一个参数是需要处理的图像;
- 第二个参数是图像的深度,-1表示采用的是与原图像相同的深度。目标图像的深度必须大于等于原图像的深度;
- dx和dy表示的是求导的阶数,0表示这个方向上没有求导,一般为0、1、2。
其后是可选的参数:
- dst不用解释了;
- ksize是Sobel算子的大小,必须为1、3、5、7。
- scale是缩放导数的比例常数,默认情况下没有伸缩系数;
- delta是一个可选的增量,将会加到最终的dst中,同样,默认情况下没有额外的值加到dst中;
- borderType是判断图像边界的模式。这个参数默认值为cv2.BORDER_DEFAULT。
使用
在OpenCV-Python中,Sobel函数的使用如下:
[python] view plain copy
- #coding=utf-8
- import cv2
- import numpy as np
- img = cv2.imread("D:/lion.jpg", 0)
- x = cv2.Sobel(img,cv2.CV_16S,1,0)
- y = cv2.Sobel(img,cv2.CV_16S,0,1)
- absX = cv2.convertScaleAbs(x) # 转回uint8
- absY = cv2.convertScaleAbs(y)
- dst = cv2.addWeighted(absX,0.5,absY,0.5,0)
- cv2.imshow("absX", absX)
- cv2.imshow("absY", absY)
- cv2.imshow("Result", dst)
- cv2.waitKey(0)
- cv2.destroyAllWindows()
解释
在Sobel函数的第二个参数这里使用了cv2.CV_16S。因为OpenCV文档中对Sobel算子的介绍中有这么一句:“in the case of 8-bit input images it will result in truncated derivatives”。即Sobel函数求完导数后会有负值,还有会大于255的值。而原图像是uint8,即8位无符号数,所以Sobel建立的图 像位数不够,会有截断。因此要使用16位有符号的数据类型,即cv2.CV_16S。
在经过处理后,别忘了用convertScaleAbs()函数将其转回原来的uint8形式。否则将无法显示图像,而只是一副灰色的窗口。convertScaleAbs()的原型为:
[python] view plain copy
- dst = cv2.convertScaleAbs(src[, dst[, alpha[, beta]]])
其中可选参数alpha是伸缩系数,beta是加到结果上的一个值。结果返回uint8类型的图片。
由于Sobel算子是在两个方向计算的,最后还需要用cv2.addWeighted(…)函数将其组合起来。其函数原型为:
[python] view plain copy
- dst = cv2.addWeighted(src1, alpha, src2, beta, gamma[, dst[, dtype]])
其中alpha是第一幅图片中元素的权重,beta是第二个的权重,gamma是加到最后结果上的一个值。
结果
原图像为:

结果为:

参考资料:
1、《Opencv2 Computer Vision Application Programming Cookbook》
2、《OpenCV References Manule》
OpenCV-Python教程(7、Laplacian算子)
Laplacian算子
图像中的边缘区域,像素值会发生“跳跃”,对这些像素求导,在其一阶导数在边缘位置为极值,这就是Sobel算子使用的原理——极值处就是边缘。如下图(下图来自OpenCV官方文档):

如果对像素值求二阶导数,会发现边缘处的导数值为0。如下(下图来自OpenCV官方文档):

Laplace函数实现的方法是先用Sobel 算子计算二阶x和y导数,再求和:(CSDN,你打水印,让我的公式怎么办?)
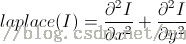
函数原型
在OpenCV-Python中,Laplace算子的函数原型如下:
[python] view plain copy
- dst = cv2.Laplacian(src, ddepth[, dst[, ksize[, scale[, delta[, borderType]]]]])
如果看了上一篇Sobel算子的介绍,这里的参数应该不难理解。
前两个是必须的参数:
- 第一个参数是需要处理的图像;
- 第二个参数是图像的深度,-1表示采用的是与原图像相同的深度。目标图像的深度必须大于等于原图像的深度;
其后是可选的参数:
- dst不用解释了;
- ksize是算子的大小,必须为1、3、5、7。默认为1。
- scale是缩放导数的比例常数,默认情况下没有伸缩系数;
- delta是一个可选的增量,将会加到最终的dst中,同样,默认情况下没有额外的值加到dst中;
- borderType是判断图像边界的模式。这个参数默认值为cv2.BORDER_DEFAULT。
使用
这里还是以Sobel一文中的石狮作为测试图像,下面是测试代码:
[python] view plain copy
- #coding=utf-8
- import cv2
- import numpy as np
- img = cv2.imread("D:/lion.jpg", 0)
- gray_lap = cv2.Laplacian(img,cv2.CV_16S,ksize = 3)
- dst = cv2.convertScaleAbs(gray_lap)
- cv2.imshow(‘laplacian’,dst)
- cv2.waitKey(0)
- cv2.destroyAllWindows()
为了让结果更清晰,这里的ksize设为3,效果图如下:

有点像粉笔画,是吧。这是因为原图像未经过去噪就直接处理了。可以通过滤波一文中,使用低通滤波一节中高斯模糊来先处理一下再用拉普拉斯函数。
OpenCV-Python教程(8、Canny边缘检测)
原型
OpenCV-Python中Canny函数的原型为:
[python] view plain copy
- edge = cv2.Canny(image, threshold1, threshold2[, edges[, apertureSize[, L2gradient ]]])
必要参数:
- 第一个参数是需要处理的原图像,该图像必须为单通道的灰度图;
- 第二个参数是阈值1;
- 第三个参数是阈值2。
其中较大的阈值2用于检测图像中明显的边缘,但一般情况下检测的效果不会那么完美,边缘检测出来是断断续续的。所以这时候用较小的第一个阈值用于将这些间断的边缘连接起来。
可选参数中apertureSize就是Sobel算子的大小。而L2gradient参数是一个布尔值,如果为真,则使用更精确的L2范数进行计算(即两个方向的倒数的平方和再开放),否则使用L1范数(直接将两个方向导数的绝对值相加)。
具体的算法可参见清华大学出版社的《图像处理与计算机视觉算法及应用(第2版) 》第二章,其中有Canny算法的详细描述及实现。
函数返回一副二值图,其中包含检测出的边缘。
使用
Canny函数的使用很简单,只需指定最大和最小阈值即可。如下:
[python] view plain copy
- #coding=utf-8
- import cv2
- import numpy as np
- img = cv2.imread("D:/lion.jpg", 0)
- img = cv2.GaussianBlur(img,(3,3),0)
- canny = cv2.Canny(img, 50, 150)
- cv2.imshow(‘Canny’, canny)
- cv2.waitKey(0)
- cv2.destroyAllWindows()
首先,由于Canny只能处理灰度图,所以将读取的图像转成灰度图。
用高斯平滑处理原图像降噪。
调用Canny函数,指定最大和最小阈值,其中apertureSize默认为3。
处理结果如下:

更多
这个程序只是静态的,在github上有一个可以在运行时调整阈值大小的程序。其代码如下:
[python] view plain copy
- import cv2
- import numpy as np
- def CannyThreshold(lowThreshold):
- 3,3),0)
- detected_edges = cv2.Canny(detected_edges,lowThreshold,lowThreshold*ratio,apertureSize = kernel_size)
- # just add some colours to edges from original image.
- ‘canny demo’,dst)
- lowThreshold = 0
- max_lowThreshold = 100
- ratio = 3
- kernel_size = 3
- img = cv2.imread(‘D:/lion.jpg’)
- gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
- cv2.namedWindow(‘canny demo’)
- cv2.createTrackbar(‘Min threshold’,‘canny demo’,lowThreshold, max_lowThreshold, CannyThreshold)
- CannyThreshold(0) # initialization
- if cv2.waitKey(0) == 27:
- cv2.destroyAllWindows()
原地址在此,其中还有其他的初级图像处理的代码,大伙可以去看看。后续文章将介绍更多的OpenCV的函数使用,以及视频的处理。
OpenCV-Python教程(9、使用霍夫变换检测直线)
霍夫变换
Hough变换是经典的检测直线的算法。其最初用来检测图像中的直线,同时也可以将其扩展,以用来检测图像中简单的结构。
OpenCV提供了两种用于直线检测的Hough变换形式。其中基本的版本是cv2.HoughLines。其输入一幅含有点集的二值图(由非0像 素表示),其中一些点互相联系组成直线。通常这是通过如Canny算子获得的一幅边缘图像。cv2.HoughLines函数输出的是[float, float]形式的ndarray,其中每个值表示检测到的线(ρ , θ)中浮点点值的参数。下面的例子首先使用Canny算子获得图像边缘,然后使用Hough变换检测直线。其中HoughLines函数的参数3和4对应 直线搜索的步长。在本例中,函数将通过步长为1的半径和步长为π/180的角来搜索所有可能的直线。最后一个参数是经过某一点曲线的数量的阈值,超过这个 阈值,就表示这个交点所代表的参数对(rho, theta)在原图像中为一条直线。具体理论可参考这篇文章。
[python] view plain copy
- #coding=utf-8
- import cv2
- import numpy as np
- img = cv2.imread("/home/sunny/workspace/images/road.jpg", 0)
- img = cv2.GaussianBlur(img,(3,3),0)
- edges = cv2.Canny(img, 50, 150, apertureSize = 3)
- lines = cv2.HoughLines(edges,1,np.pi/180,118) #这里对最后一个参数使用了经验型的值
- result = img.copy()
- for line in lines[0]:
- 0] #第一个元素是距离rho
- 1] #第二个元素是角度theta
- print rho
- print theta
- if (theta < (np.pi/4. )) or (theta > (3.*np.pi/4.0)): #垂直直线
- #该直线与第一行的交点
- 0)
- #该直线与最后一行的焦点
- 0]*np.sin(theta))/np.cos(theta)),result.shape[0])
- #绘制一条白线
- 255))
- else: #水平直线
- # 该直线与第一列的交点
- 0,int(rho/np.sin(theta)))
- #该直线与最后一列的交点
- 1], int((rho-result.shape[1]*np.cos(theta))/np.sin(theta)))
- #绘制一条直线
- 255), 1)
- cv2.imshow(‘Canny’, edges )
- cv2.imshow(‘Result’, result)
- cv2.waitKey(0)
- cv2.destroyAllWindows()
结果如下:

注意:
在C++中,HoughLines函数得到的结果是一个向量lines,其中的元素是由两个元素组成的子向量(rho, theta),所以lines的访问方式类似二维数组。因此,可以以类似:
[cpp] view plain copy
- std::vector<cv::Vec2f>::const_iterator it= lines.begin();
- float rho= (*it)[0];
- float theta= (*it)[1];
这样的方式访问rho和theta。
而在Python中,返回的是一个三维的np.ndarray!。可通过检验HoughLines返回的lines的ndim属性得到。如:
[python] view plain copy
- lines = cv2.HoughLines(edges,1,np.pi/180,118)
- print lines.ndim
- #将得到3
至于为什么是三维的,这和NumPy中ndarray的属性有关(关于NumPy的相关内容,请移步至NumPy简明教程),如果将HoughLines检测到的的结果输出,就一目了然了:
[python] view plain copy
- #上面例子中检测到的lines的数据
- 3 #lines.ndim属性
- (1, 5, 2) #lines.shape属性
- #lines[0]
- [[ 4.20000000e+01 2.14675498e+00]
- 4.50000000e+01 2.14675498e+00]
- 3.50000000e+01 2.16420817e+00]
- 1.49000000e+02 1.60570288e+00]
- 2.24000000e+02 1.74532920e-01]]
- ===============
- #lines本身
- [[[ 4.20000000e+01 2.14675498e+00]
- 4.50000000e+01 2.14675498e+00]
- 3.50000000e+01 2.16420817e+00]
- 1.49000000e+02 1.60570288e+00]
- 2.24000000e+02 1.74532920e-01]]]
概率霍夫变换
观察前面的例子得到的结果图片,其中Hough变换看起来就像在图像中查找对齐的边界像素点集合。但这样会在一些情况下导致虚假检测,如像素偶然对齐或多条直线穿过同样的对齐像素造成的多重检测。
要避免这样的问题,并检测图像中分段的直线(而不是贯穿整个图像的直线),就诞生了Hough变化的改进版,即概率Hough变换(Probabilistic Hough)。在OpenCV中用函数cv::HoughLinesP 实现。如下:
[python] view plain copy
- #coding=utf-8
- import cv2
- import numpy as np
- img = cv2.imread("/home/sunny/workspace/images/road.jpg")
- img = cv2.GaussianBlur(img,(3,3),0)
- edges = cv2.Canny(img, 50, 150, apertureSize = 3)
- lines = cv2.HoughLines(edges,1,np.pi/180,118)
- result = img.copy()
- #经验参数
- minLineLength = 200
- maxLineGap = 15
- lines = cv2.HoughLinesP(edges,1,np.pi/180,80,minLineLength,maxLineGap)
- for x1,y1,x2,y2 in lines[0]:
- 0,255,0),2)
- cv2.imshow(‘Result’, img)
- cv2.waitKey(0)
- cv2.destroyAllWindows()
结果如下:

OpenCV-Python教程(10、直方图均衡化)
相比C++而言,Python适合做原型。本系列的文章介绍如何在Python中用OpenCV图形库,以及与C++调用相应OpenCV函数的不同之处。这篇文章介绍在Python中使用OpenCV和NumPy对直方图进行均衡化处理。
提示:
- 转载请详细注明原作者及出处,谢谢!
- 本文不介详细的理论知识,读者可从其他资料中获取相应的背景知识。笔者推荐清华大学出版社的《图像处理与计算机视觉算法及应用(第2版) 》,对于本节的内容,建议直接参考维基百科直方图均衡化,只需看下页面最后的两幅图就能懂了。
本文内容:
- 使用查找表拉伸直方图
- 使用OpenCV和NumPy的函数以不同的方式进行直方图均衡化
在某些情况下,一副图像中大部分像素的强度都集中在某一区域,而质量较高的图像中,像素的强度应该均衡的分布。为此,可将表示像素强度的直方图进行拉伸,将其平坦化。如下:
图来自维基百科
实验数据
本节的实验数据来自维基百科,原图如下:
其直方图为:

使用查找表来拉伸直方图
在图像处理中,直方图均衡化一般用来均衡图像的强度,或增加图像的对比度。在介绍使用直方图均衡化来拉伸图像的直方图之前,先介绍使用查询表的方法。
观察上图中原始图像的直方图,很容易发现大部分强度值范围都没有用到。因此先检测图像非0的最低(imin)强度值和最高(imax)强度值。将最低值imin设为0,最高值imax设为255。中间的按255.0*(i-imin)/(imax-imin)+0.5)的形式设置。
实现的任务主要集中在查询表的创建中,代码如下:
[python] view plain copy
- minBinNo, maxBinNo = 0, 255
- #计算从左起第一个不为0的直方图位置
- for binNo, binValue in enumerate(hist):
- if binValue != 0:
- minBinNo = binNo
- break
- #计算从右起第一个不为0的直方图位置
- for binNo, binValue in enumerate(reversed(hist)):
- if binValue != 0:
- 255-binNo
- break
- print minBinNo, maxBinNo
- #生成查找表,方法来自参考文献1第四章第2节
- for i,v in enumerate(lut):
- print i
- if i < minBinNo:
- 0
- elif i > maxBinNo:
- 255
- else:
- 255.0*(i-minBinNo)/(maxBinNo-minBinNo)+0.5)
查询表创建完成后,就直接调用相应的OpenCV函数即可,这里调用的是cv2.LUT函数:
[python] view plain copy
- #计算
- result = cv2.LUT(image, lut)
cv2.LUT函数只有两个参数,分别为输入图像和查找表,其返回处理的结果,完整代码如下:
[python] view plain copy
- #coding=utf-8
- import cv2
- import numpy as np
- image = cv2.imread("D:/test/unequ.jpg", 0)
- lut = np.zeros(256, dtype = image.dtype )#创建空的查找表
- hist= cv2.calcHist([image], #计算图像的直方图
- 0], #使用的通道
- None, #没有使用mask
- 256], #it is a 1D histogram
- 0.0,255.0])
- minBinNo, maxBinNo = 0, 255
- #计算从左起第一个不为0的直方图柱的位置
- for binNo, binValue in enumerate(hist):
- if binValue != 0:
- minBinNo = binNo
- break
- #计算从右起第一个不为0的直方图柱的位置
- for binNo, binValue in enumerate(reversed(hist)):
- if binValue != 0:
- 255-binNo
- break
- print minBinNo, maxBinNo
- #生成查找表,方法来自参考文献1第四章第2节
- for i,v in enumerate(lut):
- print i
- if i < minBinNo:
- 0
- elif i > maxBinNo:
- 255
- else:
- 255.0*(i-minBinNo)/(maxBinNo-minBinNo)+0.5)
- #计算
- result = cv2.LUT(image, lut)
- cv2.imshow("Result", result)
- cv2.imwrite("LutImage.jpg", result)
- cv2.waitKey(0)
- cv2.destroyAllWindows()
直方图结果如下,可以看到原来占的区域很小的直方图尖峰被移动了:

处理结果为:

关于直方图的绘制,请参考这篇文章。
直方图均衡化
介绍
有时图像的视觉上的缺陷并不在强度值集中在很窄的范围内。而是某些强度值的使用频率很大。比如第一幅图中,灰度图中间值的占了很大的比例。
在完美均衡的直方图中,每个柱的值都应该相等。即50%的像素值应该小于128,25%的像素值应该小于64。总结出的经验可定义为:在标准的直方图中p%的像素拥有的强度值一定小于或等于255×p%。将该规律用于均衡直方图中:强度i的灰度值应该在对应的像素强度值低于i的百分比的强度中。因此,所需的查询表可以由下面的式子建立:
[python] view plain copy
- lut[i] = int(255.0 *p[i]) #p[i]是是强度值小于或等于i的像素的数目。
p[i]即直方图累积值,这是包含小于给点强度值的像素的直方图,以代替包含指定强度值像素的数目。比如第一幅图像的累计直方图如下图中的蓝线:

而完美均衡的直方图,其累积直方图应为一条斜线,如上图中均衡化之后的红线。
更专业一点,这种累积直方图应称为累积分布(cumulative distribition)。在NumPy中有一个专门的函数来计算。这在NumPy实现直方图均衡化一节中介绍。
通过上面的介绍,应该可以明白,直方图均衡化就是对图像使用一种特殊的查询表。在第三个例子中可以看到使用查询表来获得直方图均衡化的效果。通常来说,直方图均衡化大大增加了图像的表象。但根据图像可视内容的不同,不同图像的直方图均衡化产生的效果不尽相同。
直方图均衡化之OpenCV函数实现
用OpenCV实现直方图均衡化很简单,只需调用一个函数即可:
[python] view plain copy
- img = cv2.imread(‘图像路径’,0)
- equ = cv2.equalizeHist(img)
- cv2.imshow(‘equ’,equ)
这样图像就均衡化了。可以通过直方图的计算与显示这篇文章中介绍的方法将结果绘制出来。
直方图均衡化之NumPy函数实现
通过前面的介绍,可以明白直方图均衡化就是用一种特殊的查找表来实现的。所以这里用NumPy函数,以查找表的方式手动实现图像直方图的均衡化:
[python] view plain copy
- #coding=utf-8
- import cv2
- import numpy as np
- image = cv2.imread("D:/test/unequ.jpg", 0)
- lut = np.zeros(256, dtype = image.dtype )#创建空的查找表
- hist,bins = np.histogram(image.flatten(),256,[0,256])
- cdf = hist.cumsum() #计算累积直方图
- cdf_m = np.ma.masked_equal(cdf,0) #除去直方图中的0值
- cdf_m = (cdf_m – cdf_m.min())*255/(cdf_m.max()-cdf_m.min())#等同于前面介绍的lut[i] = int(255.0 *p[i])公式
- cdf = np.ma.filled(cdf_m,0).astype(‘uint8’) #将掩模处理掉的元素补为0
- #计算
- result2 = cdf[image]
- result = cv2.LUT(image, cdf)
- cv2.imshow("OpenCVLUT", result)
- cv2.imshow("NumPyLUT", result2)
- cv2.waitKey(0)
- cv2.destroyAllWindows()
最终结果

验证
比较查找表和OpenCV直方图均衡化生成的直方图:

可以看出,总体上来看是吻合的,但OpenCV中函数的实现可能还有一些细微的差别(有空去翻下源码,不过今天就先到这里了)。
参考资料:
1、《Opencv2 Computer Vision Application Programming Cookbook》
2、《OpenCV References Manule》
3、http://opencvpython.blogspot.com/2013/03/histograms-2-histogram-equalization.html
《用Python构建机器学习》——第十章:计算机视觉-模式识别 读后小结
本文是《Building Machine Learning Systems with Python》第十章的笔记。亚马逊英文版链接(话说亚马逊现在图书的介绍图像做得很赞啊!)
这本书和图灵出版的《机器学习实战》一书有点类似。《机器学习实战》那本书是非常建议购买一本的,如果这本书出版了,也建议购买一本。这里将阅读第十章的一些心得记录下来。
首先,关于第十章《Computer Vision: Pattern Recognition》。这一章有点名不符实,本章一半篇幅在介绍图像的基本处理,这一部分有点充数的感觉。
另外,本章使用了我以前没听过的Mahotas图像处理库。关于这个库的介绍可参见:介绍、Github、官网、文档。
我其实不清楚为什么作者使用这个库而不用OpenCV。比如,Mahotas远没有OpenCV功能强大,从目前已有的信息来看,Mahotas已有的优点,OpenCV都具有。另外,更重要的一点,根据国外友人的测试,OpenCV的速度远远快于其他常见的Python上的图像处理库,OpenCV比Mahotas快20-30倍,地址在这(自备梯子)。当然,不排除我对OpenCV先入为主的一些看法。
其实,上面一段是调侃的。。。因为后来我发现Mahotas软件包的作者就是本书的作者之一——Luis Pedro Coelho,这就不难理解为什么本书使用这个以前我没听过的库了。(仰天长笑,我还以为我out了。。。)
言归正传。本章的布局为:
10.1 Introducing image processing
10.2 Loading and displaying images
10.3 Basic image processing
Thresholding
Gaussian blurring
Filtering for different effects
Adding salt and pepper noise
Putting the center in focus
10.4 Pattern recognition
10.5 Computing features from images
10.6 Writing your own features
10.7 Classifying a harder dataset
10.8 Local feature representations
标题号是我自己加上去的,为了方便下文的说明。10.4之前的内容,除了Putting the center in focus的内容没有介绍外,其他都能在我的《OpenCV-Python教程》中找到。
10.4是模式识别,但这里有些误导。他用Tip来提示作者:“模式识别就是图像分类。由于历史原因,曾经将图像分类称为图像分类。但有关模式识别 的应用和方法不只局限于图像方面。”根据机械工业出版社的《模式识别》一书,模式识别是将对象进行分类,这些对象包括图像、信号波形或者任何可测量且需要 分类的对象。所以建议读者在记住知识点时,不要只看Tip的标题,还要看其说明。^_^。
10.5和10.6介绍计算特征图像以及如何自己编写特征。Sobel算子、Laplacian算子和Canny算子都是计算图像特征的。图像特征并没有统一的定义,但可以看一下维基百科的词条,这个词条是介绍特征提取,可以作为参考。
10.7是对10.8的铺垫,而10.8这介绍用Mahotas包中的函数应用SURF算法,并用K均值对不同结果进行了精度评价。有空我写一篇OpenCV-Python关于SURF的文章。
OpenCV-Python教程(11、轮廓检测)
轮廓检测
轮廓检测也是图像处理中经常用到的。OpenCV-Python接口中使用cv2.findContours()函数来查找检测物体的轮廓。
实现
使用方式如下:
[python] view plain copy
- import cv2
- img = cv2.imread(‘D:\\test\\contour.jpg’)
- gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
- ret, binary = cv2.threshold(gray,127,255,cv2.THRESH_BINARY)
- contours, hierarchy = cv2.findContours(binary,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
- cv2.drawContours(img,contours,-1,(0,0,255),3)
- cv2.imshow("img", img)
- cv2.waitKey(0)
需要注意的是cv2.findContours()函数接受的参数为二值图,即黑白的(不是灰度图),所以读取的图像要先转成灰度的,再转成二值图,参见4、5两行。第六行是检测轮廓,第七行是绘制轮廓。
结果
原图如下:

检测结果如下:

注意,findcontours函数会“原地”修改输入的图像。这一点可通过下面的语句验证:
[python] view plain copy
- cv2.imshow("binary", binary)
- contours, hierarchy = cv2.findContours(binary,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
- cv2.imshow("binary2", binary)
执行这些语句后会发现原图被修改了。
cv2.findContours()函数
函数的原型为
[python] view plain copy
- cv2.findContours(image, mode, method[, contours[, hierarchy[, offset ]]])
返回两个值:contours:hierarchy。
参数
第一个参数是寻找轮廓的图像;
第二个参数表示轮廓的检索模式,有四种(本文介绍的都是新的cv2接口):
cv2.RETR_EXTERNAL表示只检测外轮廓
cv2.RETR_LIST检测的轮廓不建立等级关系
cv2.RETR_CCOMP建立两个等级的轮廓,上面的一层为外边界,里面的一层为内孔的边界信息。如果内孔内还有一个连通物体,这个物体的边界也在顶层。
cv2.RETR_TREE建立一个等级树结构的轮廓。
第三个参数method为轮廓的近似办法
cv2.CHAIN_APPROX_NONE存储所有的轮廓点,相邻的两个点的像素位置差不超过1,即max(abs(x1-x2),abs(y2-y1))==1
cv2.CHAIN_APPROX_SIMPLE压缩水平方向,垂直方向,对角线方向的元素,只保留该方向的终点坐标,例如一个矩形轮廓只需4个点来保存轮廓信息
cv2.CHAIN_APPROX_TC89_L1,CV_CHAIN_APPROX_TC89_KCOS使用teh-Chinl chain 近似算法
返回值
cv2.findContours()函数返回两个值,一个是轮廓本身,还有一个是每条轮廓对应的属性。
contour返回值
cv2.findContours()函数首先返回一个list,list中每个元素都是图像中的一个轮廓,用numpy中的ndarray表示。这个概念非常重要。在下面drawContours中会看见。通过
[python] view plain copy
- print (type(contours))
- print (type(contours[0]))
- print (len(contours))
可以验证上述信息。会看到本例中有两条轮廓,一个是五角星的,一个是矩形的。每个轮廓是一个ndarray,每个ndarray是轮廓上的点的集合。
由于我们知道返回的轮廓有两个,因此可通过
[python] view plain copy
- cv2.drawContours(img,contours,0,(0,0,255),3)
和
[python] view plain copy
- cv2.drawContours(img,contours,1,(0,255,0),3)
分别绘制两个轮廓,关于该参数可参见下面一节的内容。同时通过
[python] view plain copy
- print (len(contours[0]))
- print (len(contours[1]))
输出两个轮廓中存储的点的个数,可以看到,第一个轮廓中只有4个元素,这是因为轮廓中并不是存储轮廓上所有的点,而是只存储可以用直线描述轮廓的点的个数,比如一个“正立”的矩形,只需4个顶点就能描述轮廓了。
hierarchy返回值
此外,该函数还可返回一个可选的hiararchy结果,这是一个ndarray,其中的元素个数和轮廓个数相同,每个轮廓contours[i] 对应4个hierarchy元素hierarchy[i][0] ~hierarchy[i][3],分别表示后一个轮廓、前一个轮廓、父轮廓、内嵌轮廓的索引编号,如果没有对应项,则该值为负数。
通过
[python] view plain copy
- print (type(hierarchy))
- print (hierarchy.ndim)
- print (hierarchy[0].ndim)
- print (hierarchy.shape)
得到
[python] view plain copy
- 3
- 2
- (1, 2, 4)
可以看出,hierarchy本身包含两个ndarray,每个ndarray对应一个轮廓,每个轮廓有四个属性。
轮廓的绘制
OpenCV中通过cv2.drawContours在图像上绘制轮廓。
cv2.drawContours()函数
[python] view plain copy
- cv2.drawContours(image, contours, contourIdx, color[, thickness[, lineType[, hierarchy[, maxLevel[, offset ]]]]])
- 第一个参数是指明在哪幅图像上绘制轮廓;
- 第二个参数是轮廓本身,在Python中是一个list。
- 第三个参数指定绘制轮廓list中的哪条轮廓,如果是-1,则绘制其中的所有轮廓。后面的参数很简单。其中thickness表明轮廓线的宽度,如果是-1(cv2.FILLED),则为填充模式。绘制参数将在以后独立详细介绍。
补充:
写着写着发现一篇文章介绍不完,所以这里先作为入门的。更多关于轮廓的信息有机会再开一篇文章介绍。
但有朋友提出计算轮廓的极值点。可用下面的方式计算得到,如下
[python] view plain copy
- pentagram = contours[1] #第二条轮廓是五角星
- leftmost = tuple(pentagram[:,0][pentagram[:,:,0].argmin()])
- rightmost = tuple(pentagram[:,0][pentagram[:,:,0].argmin()])
- cv2.circle(img, leftmost, 2, (0,255,0),3)
- cv2.circle(img, rightmost, 2, (0,0,255),3)
注意!假设轮廓有100个点,OpenCV返回的ndarray的维数是(100, 1, 2)!!!而不是我们认为的(100, 2)。切记!!!人民邮电出版社出版了一本《NumPy攻略:Python科学计算与数据分析》,推荐去看一下。
更新:关于pentagram[:,0]的意思
在numpy的数组中,用逗号分隔的是轴的索引。举个例子,假设有如下的数组:
[python] view plain copy
- a = np.array([[[3,4]], [[1,2]],[[5,7]],[[3,7]],[[1,8]]])
其shape是(5, 1, 2)。与我们的轮廓是相同的。那么a[:,0]的结果就是:
[python] view plain copy
- [3,4], [1,2], [5,7], [3,7], [1,8]
这里a[:,0]的意思就是a[0:5,0],也就是a[0:5,0:0:2],这三者是等价的。
回头看一下,a的shape是(5,1,2),表明是三个轴的。在numpy的数组中,轴的索引是通过逗号分隔的。同时冒号索引“:”表示的是该轴的所有元素。因此a[:, 0]表示的是第一个轴的所有元素和第二个轴的第一个元素。在这里既等价于a[0:5, 0]。
再 者,若给出的索引数少于数组中总索引数,则将已给出的索引树默认按顺序指派到轴上。比如a[0:5,0]只给出了两个轴的索引,则第一个索引就是第一个轴 的,第二个索引是第二个轴的,而第三个索引没有,则默认为[:],即该轴的所有内容。因此a[0:5,0]也等价于a[0:5,0:0:2]。
再详细一点,a的全体内容为:[[[3,4]], [[1,2]],[[5,7]],[[3,7]],[[1,8]]]。去掉第一层方括号,其中有五个元素,每个元素为[[3,4]]这样的,所以第一个索引的范围为[0:5]。注意OpenCV函数返回的多维数组和常见的numpy数组的不同之处!
观察[[3,4]],我们发现其中只有一个元素,即[3, 4],第二个索引为[0:1]。
再去掉一层方括号,我们面对的是[3,4],有两个元素,所以第三个索引的范围为[0:2]。
再次强调一下OpenCVPython接口函数返回的NumPy数组和普通的NumPy数组在组织上的不同之处。
PS:OpenCV-Python讨论群——219962286,欢迎大家加入互相探讨学习。
得到的结果为如下:

参考资料:
1、《Opencv2 Computer Vision Application Programming Cookbook》
2、《OpenCV References Manule》
3、OpenCV官方文档Contour部分




















