
一键抠图Portrait Matting人像抠图 (C++和Android源码)
目录
一键抠图Portrait Matting人像抠图 (C++和Android源码)
1. 项目介绍:
2. MODNet抠图算法:
3. Matting数据集
(1) 开源数据集
(2) 训练和测试数据说明
(3) 合成代码实现
4. Android JNI接口
5. Demo测试效果
6. Android完整项目代码
抠图算法中(英文中,一般称为Matting),一种是基于辅助信息输入的,加入一些先验信息(如Trimap,背景图,用户交互信息,深度等信息)提供抠图效果,如比较经典的Deep Image Matting和Semantic Image Matting这些算法加入Trimap; Background Matting算法需要提供背景图等;另一种是无需辅助信息,输入RGB图像,直接预测matte的方法,其效果相对第一种方法,会差很多。而对Portrait Matting(人像抠图),现在有很多方案在无需Trimap条件下,也可以获得不错的抠图效果,比如MODNet,Fast Deep Matting等算法,真正实现健抠图的效果。
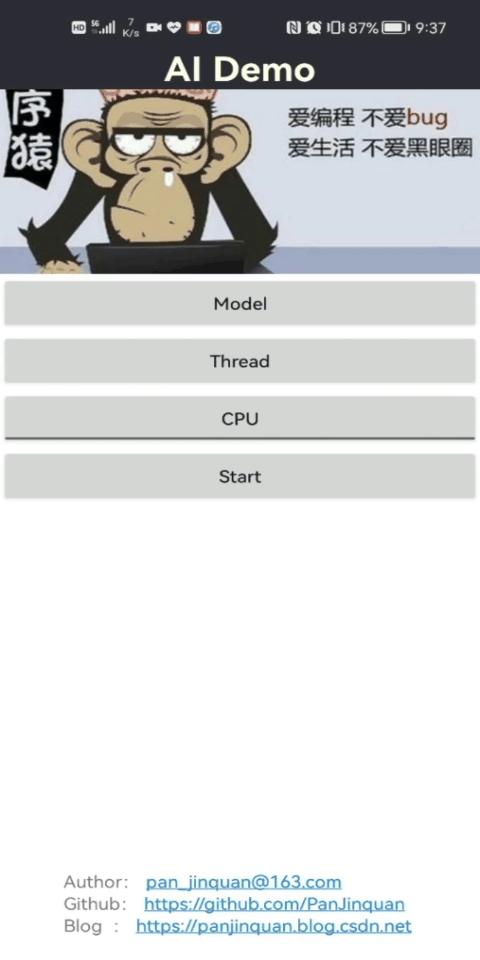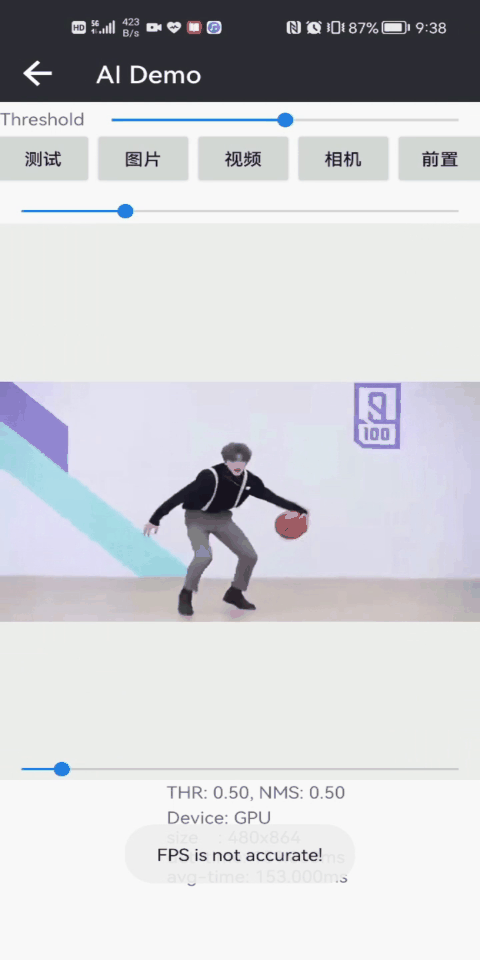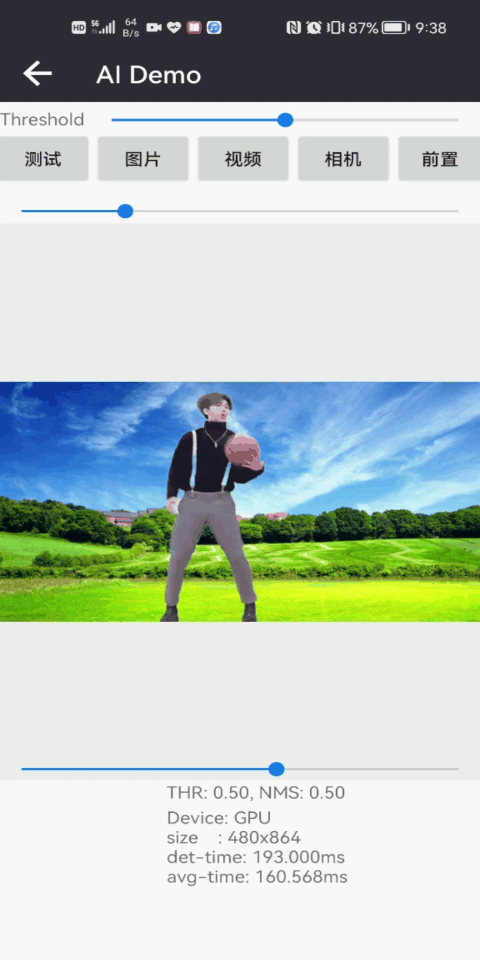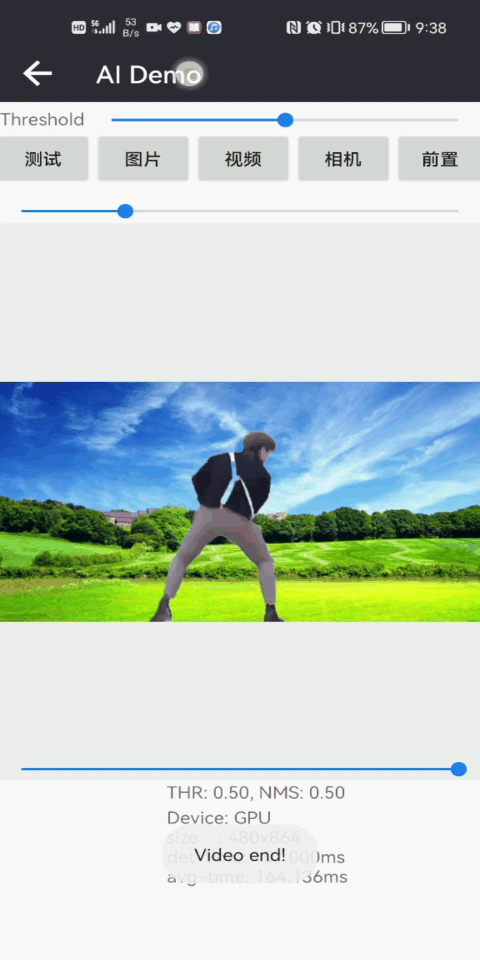
本篇博客将介绍MODNet人像抠图算法,一个效果相当不错的Matting算法,可以达到头发细致级别的人像抠图效果,是一健抠图哦,先展示一下Android测试效果:
- Demo APP下载地址
- Android Demo完整项目代码:一键抠图Portrait Matting人像抠图 (C++和Android源码)
模型选择 | 原图 | 高精度人像抠图 | 视频抠图 |
|
|
|
|



更多抠图算法(Matting),请参考我的一篇博客《图像抠图Image Matting算法调研》:
可能,有小伙伴搞不清楚分割(segmentation)和抠图(matting)有什么区别,我这里简单说明一下:
- 分割(segmentation):从深度学习的角度来说,分割本质是像素级别的分类任务,其损失函数最简单的莫过于是交叉熵CrossEntropyLoss(当然也可以是Focal Loss,IOU Loss,Dice Loss等);对于前景和背景分割任务,输出Mask的每个像素要么是0,要么是1。如果拿去直接做图像融合,就很不自然,Mask边界很生硬,这时就需要使用抠图算法了
- 抠图(matting): 而抠图本质是一种回归任务,其损失函数可以是MSE Loss,L1 Loss,L2 Loss等,对于前景和背景抠图任务,输出Mask的每个像素是0~1之间的连续值,可看作是对图像透明通道(Alpha)的回归预测。可以用公式表示为C = αF + (1-α)B ,其中α(不透明度)、F(前景色)和B(背景色),alpha是[0, 1]之间的连续值,可以理解为像素属于前景的概率。在人像分割任务中,alpha只能取0或1,而抠图任务中,alpha可取[0, 1]之间的连续值,
- 本质上就是一句话:分割是分类任务,而抠图是回归任务。
1. 项目介绍:
关于《MODNet: Trimap-Free Portrait Matting in Real Time》,请参考:
- Paper: https://arxiv.org/pdf/2011.11961.pdf
- 官方Github: GitHub - ZHKKKe/MODNet: A Trimap-Free Solution for Portrait Matting in Real Time
官方GitHub仅仅放出推理代码,并未提供训练过程和数据处理代码 ;鄙人参考原论文花了几个星期的时间,总算复现了其基本效果,并做了一些轻量化和优化的工作,主要有:
- 复现Pytorch版本的MODNet训练过程和数据处理
- 增加了数据增强方法:如多尺度随机裁剪,Mosaic(拼图),随机背景融合等方法,提高模型泛化性
- 对MODNet骨干网络backbone进行轻量化,减少计算量
- 目前提供三个版本:高精度人像抠图+快速人像抠图+超快人像抠图
- 转写模型推理过程,实现C++版本人像抠图算法
- 实现Android版本人像抠图算法,支持CPU和GPU
- 提供高精度版本人像抠图,可以达到精细到发丝级别的抠图效果(Android GPU 150ms, CPU 500ms左右)
- 提供轻量化快速版人像抠图,满足基本的人像抠图效果,可以在Android达到实时的抠图效果(Android GPU 60ms, CPU 140ms左右)
最近发现,百度PaddleSeg团队也复现了MODNet算法(基于PaddlePaddle框架,非Pytorch版本),提供了更丰富的backbone模型选择,如MobileNetV2,ResNet50,HRNet_W18,可适用边缘端、服务端等多种任务场景,有兴趣的可以看看:
PaddlePaddle版本:https:///PaddlePaddle/PaddleSeg/tree/release/2.3/contrib/Matting
2. MODNet抠图算法:
基于深度学习的Matting分为两大类:
- 一种是基于辅助信息输入。即除了原图和标注图像外,还需要输入其他的信息辅助预测。最常见的辅助信息是Trimap,即将图片划分为前景,背景及过度区域三部分。另外也有以背景或交互点作为辅助信息。
- 一种是不依赖任何辅助信息,直接对Alpha进行预测。如本博客复现的MODNet
第一种方法,需要加入辅助信息,而辅助信息一般较难获取,这也限制其应用,为了提升Matting的应用性,针对Portrait Matting领域MODNet摒弃了辅助信息,直接实现Alpha预测,实现了实时Matting,极大提升了基于深度学习Matting的应用价值。
MODNet模型学习分为三个部分,分别为:语义部分(S),细节部分(D)和融合部分(F)。
- 在语义估计中,对high-level的特征结果进行监督学习,标签使用的是下采样及高斯模糊后的GT,损失函数用的L2-Loss,用L2loss应该可以学到更soft的语义特征;
- 在细节预测中,结合了输入图像的信息和语义部分的输出特征,通过encoder-decoder对人像边缘进行单独地约束学习,用的是交叉熵损失函数。为了减小计算量,encoder-decoder结构较为shallow,同时处理的是原图下采样后的尺度。
- 在融合部分,把语义输出和细节输出结果拼起来后得到最终的alpha结果,这部分约束用的是L1损失函数。

3. Matting数据集
(1) 开源数据集
数据集 | 说明 |
| |
Deep Image Matting |
|
PPM-100下载:https:///PaddlePaddle/PaddleSeg/tree/release/2.3/contrib/Matting | |
RealWorldPortrait-636 |
|
Compsition-1k |
|
AM-2k |
|
BG-20k |
|
VideoMatte240K |
|
PhotoMatte85 |
其他的:
- VideoMatte240K
- PhotoMatte85
- https:///thuyngch/Human-Segmentation-PyTorch
- Automatic Portrait Segmentation for Image Stylization: 1800 images
- Supervisely Person: 5711 images
(2) 训练和测试数据说明
关于训练数据如何生成的问题:
- 原论文MODNet使用了PPM-100数据集+私有的数据集,并合成了大部分训练数据
- 鄙人复现时,先使用matting_human_datasets数据集训练base-model当作pretrained模型;然后合并多个数据集(PPM-100 + RealWorldPortrait-636 + Deep Image Matting),采用背景图来自VOC+COCO+BG-20k ,一共合成了5W+的训练数据和500+的测试数据
- 合成的方法有两种:方法1:利用公式:合成图 = 前景*alpha+背景*(1-alpha) ;方法二:前景+mask+背景通过GAN生成;
(3) 合成代码实现
这是Python实现的背景合成,需要提供原始图像image,以及image的前景图像alpha,和需要合成的背景图像bg_img:
当然,为了方便JNI调用,我这里还实现C++版本图像合成算法,这部分图像处理的基本工具,都放在我的base-utils中
4. Android JNI接口
- 目前已经实现Android版本人像抠图算法,支持CPU和GPU
- 提供高精度版本人像抠图,可以达到精细到发丝级别的抠图效果(Android GPU 150ms, CPU 500ms左右)
- 提供轻量化快速版人像抠图,满足基本的人像抠图效果,可以在Android达到实时的抠图效果(Android GPU 60ms, CPU 140ms左右)
目前,提供Demo源码提供三个JNI接口,可实现一健抠图效果,当然你可以在我C++基础上修改源码,实现更多功能;
matting接口:实现基本的人像构图Matting功能 fusion接口:实现人像构图Matting,并与背景图进行融合 mattingFusion接口:人像构图Matting,并与背景图进行融合(会返回mask)
5. Demo测试效果
实际使用中,建议你:
- 背景越单一,抠图的效果越好,背景越复杂,抠图效果越差;建议你实际使用中,找一比较单一的背景,如墙面,天空等
- 上半身抠图的效果越好,下半身或者全身抠图效果较差;本质上这是数据的问题,因为训练数据70%都是只有上半身的
- 白种人抠图的效果越好,黑人和黄种人抠图效果较差;这也是数据的问题,因为训练数据大部分都是隔壁的老外
下图是高精度版本人像抠图和快速人像构图的测试效果,相对而言,高精度版本人像抠图可以精细到发丝级别的抠图效果;而快速人像构图目前仅能实现基本的抠图效果:
原图 | Mask图像 | 融合图像 | |
高 精 度 人 像 抠图 |
|
|
|
超 快 人 像 抠图 |
|
|
|




其他测试图片
|
|
|
|




6. Android完整项目代码
- Demo APP下载地址
- Android Demo完整项目代码:一键抠图Portrait Matting人像抠图 (C++和Android源码)

















