
环境;高可用k8s集群连带N个work node节点。在以下命令的时候
kubectl get pod --all-namespaces -o wide | grep cal
发现pod重启达上百次。且状态是imagepullbackoff 下面使用以下命令可以看到readness、liveness探针失败,容器创建成功
kubectl describe pod -n (空间) (pod名称)
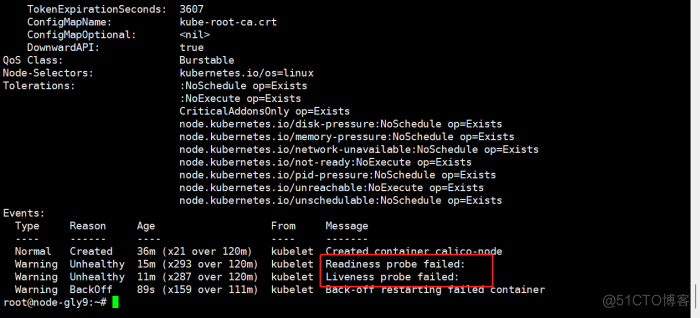 为了确保pod是否报错,使用以下命令查看日志,发现pod未报错
为了确保pod是否报错,使用以下命令查看日志,发现pod未报错
kubectl logs (pod名) -n (空间)
使用命令导出calico的yaml文件
kubectl get deployment -n (空间) (名称) -o yaml > /tmp/calico.yaml
查看里面相关的readness和liveness探针,发现里面的timeout超时检测一个是1一个是5;把他们都重新设置成10后,删除原先的pod,重新apply -f这个yaml文件后,pod整成功running

结论:探针健康检查的超时时间过短,导致pod无限重启。且状态是imagepullbackoff


















