
当使用MYSQL单实例,因数据量剧增出现性能问题的时候,普通的分库分表又难以满足其需求,一些客户会考虑迁移至分布式数据库。TDSQL 分布式是一款面向金融领域的一款数据库,适合应用在海量数据、高性能,高并发的使用场景。那么我们从MYSQL迁移至TDSQL都有哪些途径呢 ?这里我们对MYSQL离线迁移至分布式TDSQL 介绍一种方法:
使用LOAD_DATA 导入至TDSQL分布式实例 ,LOAD_DATA 是在原生 MYSQL load data 基础上,针对导入分布式TDSQL 进行优化逻辑处理后的一款导入工具。此工具只适用于导入TDSQL分布式 ,不适合TDSQL非分布式。究其原因是 TDSQL分布式 在插入语句中有一个严格限制,插入语句必须带有shardkey ,没有shardkey的情况下会导入失败。所以LOAD_DATA 工具会对shardkey 这一层面有一个处理。
**我们可以通过./load_data查看帮助 具体的使用方法:**
cd /data/tdsql_run/15002/gateway/bin
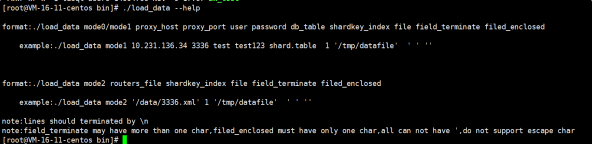
**命令的参数说明**
导入命令:./load_data mode1 $proxy_host $proxy_port $proxy_username $proxy_passwd $proxy_dbname.$proxy_tablename auto '$file_name' ',' '"'
**参数说明:**
mode0:load_data的原理是分割数据,然后导入数据,mode0是先分割数据不进行导入。
mode1:分割数据,然后导入数据。
proxy_host:网关的host
proxy_port:网关的端口
user:用户名
password:密码
db_talbe:库表,格式为db.table
shardkey_index:shardkey字段在导入文件的索引(位置,从0开始)
file:绝对路径的文件所在位置
field_terminated:与导出时使用的field terminated 一致,行的分割
field_enclosed:与导出时使用的field enclosed一致,设置字段包围字符
下面我们简单做个迁移测试,具体介绍一下迁移步骤:
**第一步 从mysql单实例中 导出数据至csv格式:**
导出csv 格式的方法也有多种 ,这里我们就使用 into outfile ,我们以test库下T1 表为例
**T1 表结构**
CREATE TABLE `game_score_log` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) NOT NULL,
`score` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ;
**插入一些数据**
insert into t1 (id,name,score) values ("10001","王五","100");
insert into t1 (id,name,score) values ("10002","李四","95" );
insert into t1 (id,name,score) values ("10003","李四","100");
insert into t1 (id,name,score) values ("10004","李四","75" );
insert into t1 (id,name,score) values ("10005","王五","70" );
insert into t1 (id,name,score) values ("10006","张三","85" );
insert into t1 (id,name,score) values ("10007","张三","65" );
insert into t1 (id,name,score) values ("10008","王五","70" );
**使用select into outfile 进行导出**
SELECT * FROM t1
INTO OUTFILE '/tmp/t1.csv'
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n';
FIELDS TERMINATED BY ',' 字段间分割符
OPTIONALLY ENCLOSED BY '"' 将字段包围 对数值型无效
LINES TERMINATED BY '\n' 换行符
cat /tmp/t1.csv
"10001","王五","100"
"10002","李四","95"
"10003","李四","100"
"10004","李四","75"
"10005","王五","70"
"10006","张三","85"
"10007","张三","65"
"10008","王五","70"
**第二步:导入数据到TDSQL分布式实例**
**(1)首先在TDSQL分布式实例上准备库和表结构,这里注意shardkey 的选取(建议选择一个区分度较高的字段,以便数据均匀打散到各个分片中,这里需要业务人员的参与)**
CREATE TABLE `t1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) NOT NULL,
`score` int(11) NOT NULL,
PRIMARY KEY (`id`)
) shardkey=id;
**(2)mode0模式 分割成 n个(看实例有几个分片)文件 ,但不导入**
./load_data mode0 172.21.16.11 15002 ju2 ju2 test.t1 auto '/tmp/t1.csv' ',' '"'
执行后分割为:t1.csv_set_1605000504_1 和 t1.csv_set_1605000688_3两个文件

**(3)mode1模式,直接分割并导入**
./load_data mode1 172.21.16.11 15002 ju2 ju2 test.t1 auto '/tmp/t1.csv' ',' '"'
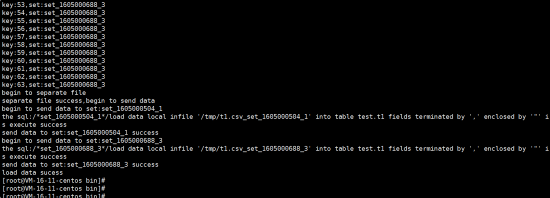
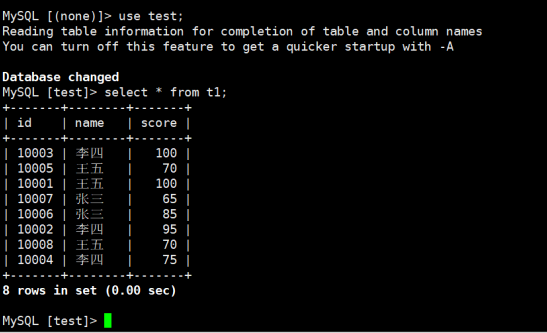
**(4)最后验证:**
MYSQL-uju2 -pju2 -h172.21.16.11 -P15002 -c
查看各个分片上的数据
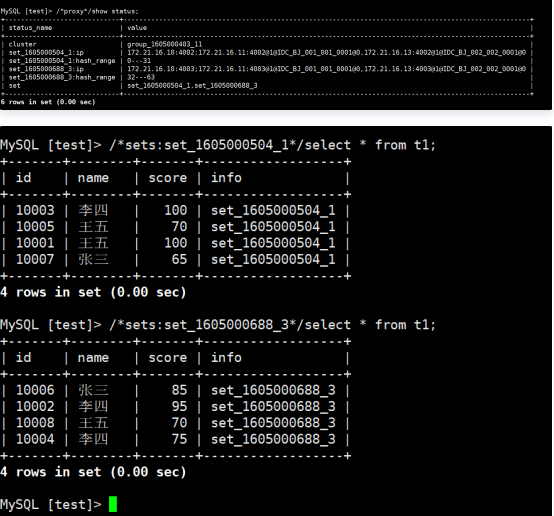
至此,迁移完成。
原创声明,本文系作者授权云+社区发表,未经许可,不得转载。
如有侵权,请联系 yunjia_community@tencent.com 删除。


















