
1. 背景
https://blog.51cto.com/u_15327484/8193991介绍了海外Hadoop集群一般将冷数据放入到AWS S3或者存放到Google gcs对象存储中。这些对象存储都提供了各自的客户端进行访问,例如aws s3的客户端命令就是aws s3;gcs的客户端命令是gsutil。这些命令一般需要直接登陆到授权机器中执行,比较麻烦。
为了解决这个问题,AWS S3和Google gcs都提供了对应的SDK给Hadoop进行集成,通过指定对应的文件系统类,可以通过sdk访问s3和gcs。
2. hadoop整合aws s3对象存储
下载aws的SDK文件:hadoop-aws-x.x.x.jar,aws-java-sdk-bundle-x.x.x.jar,放到hadoop的安装目录hadoop/share/hadoop/common下。
在core-site.xml增加如下配置:
<property>
<name>fs.s3a.access.key</name>
<description>AWS access key ID.
Omit for IAM role-based or provider-based authentication.</description>
<value>xxxxxx</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<description>AWS secret key.
Omit for IAM role-based or provider-based authentication.</description>
<value>xxxxxx</value>
</property>
<property>
<name>fs.s3a.aws.credentials.provider</name>
<value>org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider</value>
</property>
注意,fs.s3a.aws.credentials.provider可以有多种配置:
- com.amazonaws.auth.EnvironmentVariableCredentialsProvider:使用环境变量AWS_ACCESS_KEY_ID 和AWS_SECRET_ACCESS_KEY。
- com.amazonaws.auth.InstanceProfileCredentialsProvider: 使用profile。
- org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider: 使用fs.s3a.access.key and fs.s3a.secret.key 配置项。一般都是用这种方式。
如果想通过credentials文件的方式访问,就在hdfs中创建credential文件:
hadoop credential create fs.s3a.access.key -value xxxxx -provider jceks://hdfs@cluster1/user/s3key/credential.jceks
hadoop credential create fs.s3a.secret.key -value xxxxx -provider jceks://hdfs@cluster1/user/s3key/credential.jceks
方法方式:
hadoop fs -D hadoop.security.credential.provider.path=jceks://hdfs@cluster1/user/s3key/credential.jceks -ls s3a://bucket/
3. hadopo整合google gcs对象存储
下载gcs的SDK文件:gcs-connector-hadoop3-latest.jar,放到hadoop的安装目录hadoop/share/hadoop/common下。
在core-site.xml增加如下配置:
<property>
<name>fs.AbstractFileSystem.gs.impl</name>
<value>com.google.cloud.hadoop.fs.gcs.GoogleHadoopFS</value>
<description>The AbstractFileSystem for 'gs:' URIs.</description>
</property>
这样就搭建好了基础的使用姿势。如果gcs开启了aksk认证,需要将aksk转化为credential写到hdfs中,在访问时指定credential即可完成认证:
hadoop credential create fs.gs.auth.service.account.email \
-provider jceks://hdfs/app/client-app-a/sa-data-access-a.jceks \
-value "具体email"
hadoop credential create fs.gs.auth.service.account.private.key.id \
-provider jceks://hdfs/app/client-app-a/sa-data-access-a.jceks \
-value "ak"
hadoop credential create fs.gs.auth.service.account.private.key \
-provider jceks://hdfs/app/client-app-a/sa-data-access-a.jceks \
-value "sk"
如下,指定credential,即可完成认证并访问gcs:
hadoop dfs -Dhadoop.security.credential.provider.path=jceks://hdfs@cluster/user/yuliang02/test/gdc-data-tianma.jceks -ls gs://gdc-data-tianma-sa/test/test_gcs_distcp_file
4. aws s3智能分层支持
4.1 aws s3智能分层介绍
AWS对S3有以下三种经常存储策略:
- Standard:通用策略。
- Standard-IA:不频繁访问策略,必须手动设置S3对象为不频繁访问,设置之后对象无法自动升级和降级。
- Intelligent - Tiering:智能分层策略,根据数据冷热程度自动对存储进行升级和降级。
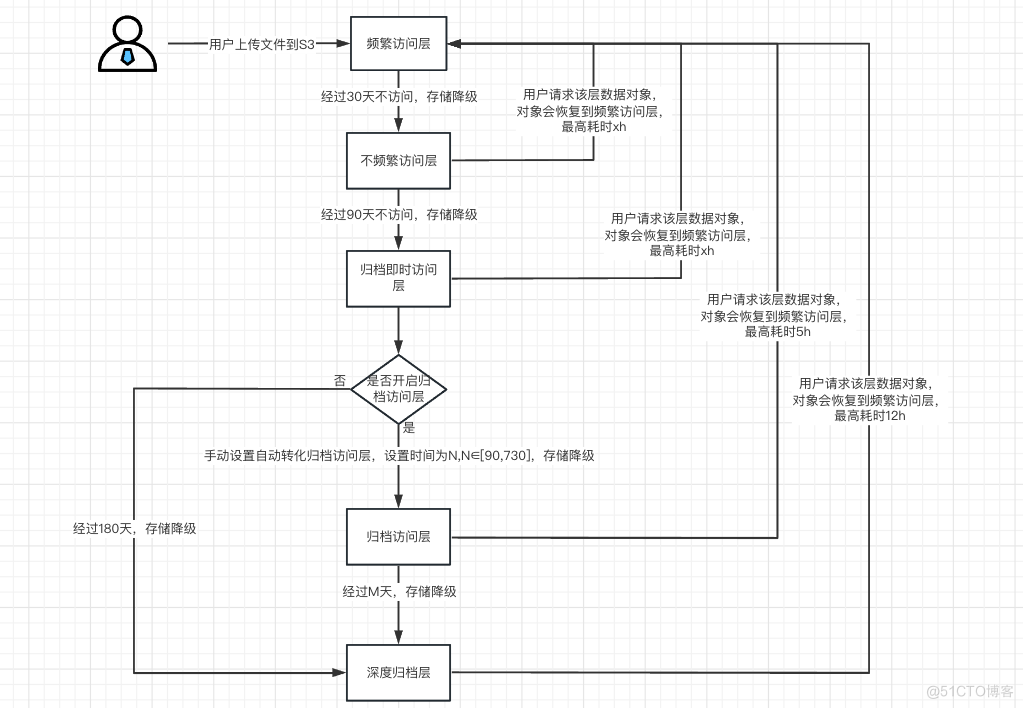
AWS S3智能分层策略流程:
- 初次上传文件到s3后,会存储在频繁访问层。
- 对于频繁访问层大于128KB的文件,如果超过30天没访问,就转移到不频繁访问层。
- 对于不频繁访问层的文件,如果超过90天没有访问,就转移到归档即时访问层。
- 对于归档即时访问层,如果手动设置N天移动归档访问层,经过N天会移动到归档访问层。
- 对于归档即时访问层,如果没有设置移动归档访问层,超过180天移动到深度存储归档层。
- 对于归档访问层,由于设置了存储时间上限,超过时间上限,会移动到深度存储归档层。
- 对于所有非频繁访问层的文件,一旦用户再次访问S3对象,就会将S3对象转化为频繁访问层。
- 不频繁访问层转化为频繁访问层,需要?时间(理论上切换不需要时间)。
- 归档即时访问层转化为频繁访问层,需要?时间(理论上切换不需要时间)。
- 归档访问层转化为频繁访问层,最长需要5h。
- 深度存储归档层转化为频繁访问层,最长需要12h。
其流程图如下所示:
经过统计,总共2000TB的S3数据,最终大约会有1996.43TB落到不频繁访问层,最终每月能节省4779.03刀的存储费用。
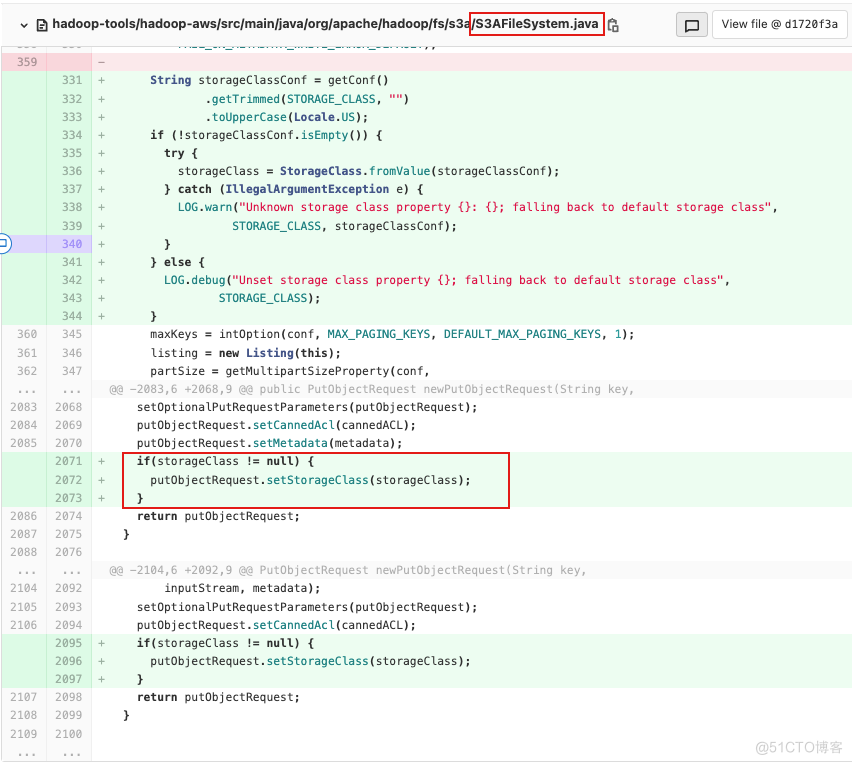
HDFS默认情况下没有指定对象的存储策略,那么文件存储时就是通用策略。只有当设置了桶的存储策略后一段时间内才会将对象转变为Intelligent - Tiering类型。因此,可以引入https://issues.apache.org/jira/browse/HADOOP-12020,在s3a客户端指定对象的存储策略为Intelligent - Tiering类型。可以有效降低存储成本。其关键代码如下:
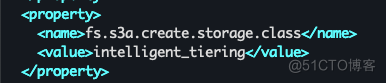
客户端上传文件到S3时,在HDFS-site.xml中新增存储类型:
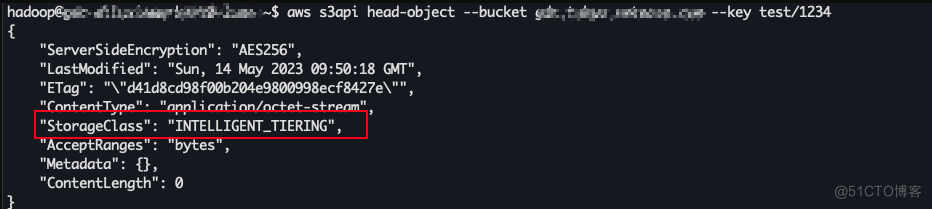
 上传到S3后,发现对象的存储类型就是智能分层类型:
上传到S3后,发现对象的存储类型就是智能分层类型:
5. 智能分层相关业务适配
S3的整体存储信息来自于S3的inventory生成的文件,一般会建立一张hive表用于查询inventory信息。开启了智能分层后,inventory新增了智能分层字段,为了获取S3中每个对象的存储层次,需要在hive表中增加相应字段:
如下,在hive表中增加对象的存储类型和目前所处的层次字段:



















