
.NET:CLR via C# Exceptions and State Management
- unhandled exceptions
- constrained execution regions
- code contracts
- runtime wrapped exceptions
- uncatchable exceptions
Many developers incorrectly believe that an exception is related to how frequently something happens. For example, a developer designing a file Read method is likely to say the following: “When reading from a file, you will eventually reach the end of its data. Because reaching the end will always happen, I’ll design my Read method so that it reports the end by returning a special value; I won’t have it throw an exception.” The problem with this statement is that it is being made by the developer designing the Read method, not by the developer calling the Read method.
When designing the Read method, it is impossible for the developer to know all of the possible situations in which the method gets called. Therefore, the developer can’t possibly know how often the caller of the Read method will attempt to read past the end of the file. In fact, because most files contain structured data, attempting to read past the end of a file is something that rarely happens.
how much code they should put inside a single try block?Sometimes developers ask how much code they should put inside a single try block. The answer to this depends on state management. If, inside a try block, you execute multiple operations that could all throw the same exception type and the way that you’d recover this exception type is different depending on the operation, then you should put each operation in its own try block so that you can recover your state correctly.
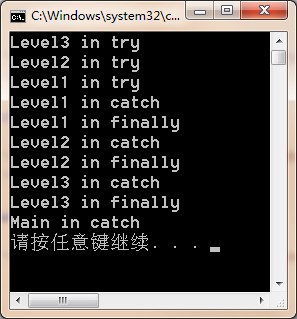
Unhandled ExceptionIf an exception is thrown by code executing within the try block (or any method called from within the try block), the CLR starts searching for catch blocks whose catch type is the same type as or a base type of the thrown exception. If none of the catch types matches the exception, the CLR continues searching up the call stack looking for a catch type that matches the exception. If after reaching the top of the call stack, no catch block is found with a matching catch type, an unhandled exception occurs.
Unfortunately, every application model Microsoft produces has its own way of tapping into unhandled exceptions. The members that you want to look up in the FCL documentation are.
- For many applications, look at System.AppDomain’s UnhandledException event. Windows Store applications and Microsoft Silverlight applications cannot access this event.
- For a Windows Store App, look at Windows.UI.Xaml.Application’s UnhandledException event.
- For a Windows Forms application, look at System.Windows.Forms.NativeWindow’s OnThreadException virtual method, System.Windows.Forms.Application’s OnThreadException virtual method, and System.Windows.Forms.Application’s ThreadException event.
- For a Windows Presentation Foundation (WPF) application, look at System.Windows. Application’s DispatcherUnhandledException event and System.Windows. Threading.Dispatcher’s UnhandledException and UnhandledExceptionFilter events.
- For Silverlight, look at System.Windows.Application’s UnhandledException event.
- For an ASP.NET Web Form application, look at System.Web.UI.TemplateControl’s Error event. TemplateControl is the base class of the System.Web.UI.Page and System.Web.UI.UserControl classes. Furthermore, you should also look at System. Web.HttpApplication’s Error event.
- For a Windows Communication Foundation application, look at System.ServiceModel. Dispatcher.ChannelDispatcher’s ErrorHandlers property.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Threading.Tasks;
6
7 namespace ExceptionManagementStudy
8 {
9 class Program
10 {
11 static void Main(string[] args)
12 {
13 try
14 {
15 Level3();
16 }
17 catch
18 {
19 Console.WriteLine("Main in catch");
20 }
21 }
22
23 static void Level3()
24 {
25 try
26 {
27 Console.WriteLine("Level3 in try");
28 Level2();
29 }
30 catch
31 {
32 Console.WriteLine("Level3 in catch");
33 throw;
34 }
35 finally
36 {
37 Console.WriteLine("Level3 in finally");
38 }
39 }
40
41 static void Level2()
42 {
43 try
44 {
45 Console.WriteLine("Level2 in try");
46 Level1();
47 }
48 catch
49 {
50 Console.WriteLine("Level2 in catch");
51 throw;
52 }
53 finally
54 {
55 Console.WriteLine("Level2 in finally");
56 }
57 }
58
59 static void Level1()
60 {
61 try
62 {
63 Console.WriteLine("Level1 in try");
64 throw new Exception("Level1");
65 }
66 catch
67 {
68 Console.WriteLine("Level1 in catch");
69 throw;
70 }
71 finally
72 {
73 Console.WriteLine("Level1 in finally");
74 }
75 }
76 }
77 }
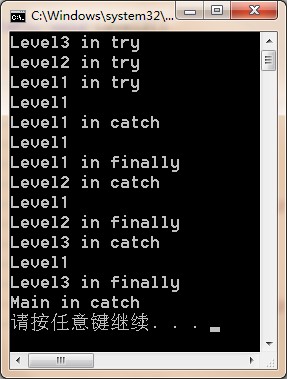
Your code can register with AppDomain’s FirstChanceException event to receive notifications as soon as an exception occurs within an AppDomain. This notification occurs before the CLR searches for any catch blocks. For more information about this event.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Threading.Tasks;
6
7 namespace ExceptionManagementStudy
8 {
9 class Program
10 {
11 static void Main(string[] args)
12 {
13 AppDomain.CurrentDomain.FirstChanceException += CurrentDomain_FirstChanceException;
14 try
15 {
16 Level3();
17 }
18 catch
19 {
20 Console.WriteLine("Main in catch");
21 }
22 }
23
24 static void CurrentDomain_FirstChanceException(object sender, System.Runtime.ExceptionServices.FirstChanceExceptionEventArgs e)
25 {
26 Console.WriteLine(e.Exception.Message);
27 }
28
29 static void Level3()
30 {
31 try
32 {
33 Console.WriteLine("Level3 in try");
34 Level2();
35 }
36 catch
37 {
38 Console.WriteLine("Level3 in catch");
39 throw;
40 }
41 finally
42 {
43 Console.WriteLine("Level3 in finally");
44 }
45 }
46
47 static void Level2()
48 {
49 try
50 {
51 Console.WriteLine("Level2 in try");
52 Level1();
53 }
54 catch
55 {
56 Console.WriteLine("Level2 in catch");
57 throw;
58 }
59 finally
60 {
61 Console.WriteLine("Level2 in finally");
62 }
63 }
64
65 static void Level1()
66 {
67 try
68 {
69 Console.WriteLine("Level1 in try");
70 throw new Exception("Level1");
71 }
72 catch
73 {
74 Console.WriteLine("Level1 in catch");
75 throw;
76 }
77 finally
78 {
79 Console.WriteLine("Level1 in finally");
80 }
81 }
82 }
83 }
It is always possible that exception-recovery code or cleanup code could fail and throw an exception. Although possible, it is unlikely and if it does happen it usually means that there is something very wrong somewhere. Most likely some state has gotten corrupted somewhere. If an exception is inadvertently thrown within a catch or finally block, the world will not come to an end—the CLR’s exception mechanism will execute as though the exception were thrown after the finally block. However, the CLR does not keep track of the first exception that was thrown in the corresponding try block (if any), and you will lose any and all information (such as the stack trace) available about the first exception. Probably (and hopefully), this new exception will not be handled by your code and the exception will turn into an unhandled exception. The CLR will then terminate your process, which is good because all the corrupted state will now be destroyed. This is much better than having your application continue to run with unpredictable results and possible security holes.
这段话比较有意思Personally, I think the C# team should have chosen different language keywords for the exceptionhandling mechanism. What programmers want to do is try to execute some piece of code. And then, if something fails, either recover from the failure and move on or compensate to undo some state change and continue to report the failure up to a caller. Programmers also want to have guaranteed cleanup no matter what happens.

Many programmers are not aware that the CLR allows any object to be thrown to report an exception. Most developers believe that only Exception-derived objects can be thrown. Prior to CLR 2.0, when programmers wrote catch blocks to catch exceptions, they were catching CLS-compliant exceptions only. If a C# method called a method written in another language, and that method threw a non–CLS-compliant exception, the C# code would not catch this exception at all, leading to some security vulnerabilities.
In CLR 2.0, Microsoft introduced a new RuntimeWrappedException class (defined in the System.Runtime.CompilerServices namespace). This class is derived from Exception, so it is a CLS-compliant exception type. The RuntimeWrappedException class contains a private field of type Object (which can be accessed by using RuntimeWrappedException’s WrappedException read-only property). In CLR 2.0, when a non–CLS-compliant exception is thrown, the CLR automatically constructs an instance of the RuntimeWrappedException class and initializes its private field to refer to the object that was actually thrown. In effect, the CLR now turns all non–CLS-compliant exceptions into CLS-compliant exceptions. Any code that now catches an Exception type will catch non–CLS-compliant exceptions, which fixes the potential security vulnerability problem.
关于 StackTraceWhen an exception is thrown, the CLR internally records where the throw instruction occurred. When a catch block accepts the exception, the CLR records where the exception was caught. If, inside a catch block, you now access the thrown exception object’s StackTrace property, the code that implements the property calls into the CLR, which builds a string identifying all of the methods between the place where the exception was thrown and the filter that caught the exception.
When you throw an exception, the CLR resets the starting point for the exception; that is, the CLR remembers only the location where the most recent exception object was thrown.
The following code throws the same exception object that it caught and causes the CLR to reset its starting point for the exception.
1 private void SomeMethod()
2 {
3 try
4 {
5 //...
6 }
7 catch (Exception e)
8 {
9 throw e;
10 // CLR thinks this is where exception originated.
11 // FxCop reports this as an error
12 }
13 }
In contrast, if you re-throw an exception object by using the throw keyword by itself, the CLR doesn’t reset the stack’s starting point. The following code re-throws the same exception object that it caught, causing the CLR to not reset its starting point for the exception.
private void SomeMethod()
{
try
{
//...
}
catch (Exception e)
{
throw;
// This has no effect on where the CLR thinks the exception originated.
// FxCop does NOT report this as an error.
}
}
If the CLR can find debug symbols (located in the .pdb files) for your assemblies, the string returned by System.Exception’s StackTrace property or System.Diagnostics.StackTrace’s ToString method will include source code file paths and line numbers. This information is incredibly useful for debugging.
Whenever you obtain a stack trace, you might find that some methods in the actual call stack don’t appear in the stack trace string. There are two reasons for this. First, the stack is really a record of where the thread should return to, not where the thread has come from. Second, the just-in-time (JIT) compiler can inline methods to avoid the overhead of calling and returning from a separate method.
如何定义自己的异常体系?If you want to define an exception type hierarchy, it is highly recommended that the hierarchy be shallow and wide in order to create as few base classes as possible. The reason is that base classes act as a way of treating lots of errors as one error, and this is usually dangerous. Along these lines, you should never throw a System.Exception object, and you should use extreme caution if you throw any other base class exception type.
There are versioning ramifications here, too. If you define a new exception type derived from an existing exception type, then all code that catches the existing base type will now catch your new type as well. In some scenarios, this may be desired and in some scenarios, it may not be desired. The problem is that it really depends on how code that catches the base class responds to the exception type and types derived from it. Code that never anticipated the new exception may now behave unpredictably and open security holes. The person defining the new exception type can’t know about all the places where the base exception is caught and how it is handled. And so, in practice, it is impossible to make a good intelligent decision here.
如何避免异常导致的状态不一致?- The CLR doesn’t allow a thread to be aborted when executing code inside a catch or finally block.
- You can use the System.Diagnostics.Contracts.Contract class to apply code contracts to your methods. Code contracts give you a way to validate arguments and other variables before you attempt to modify state by using these arguments/variables. If the arguments/ variables meet the contract, then the chance of corrupted state is minimized (not completely eliminated). If a contract fails, then an exception is thrown before any state has been modified.
- You can use constrained execution regions (CERs), which give you a way to take some CLR uncertainty out of the picture. For example, before entering a try block, you can have the CLR load any assemblies needed by code in any associated catch and finally blocks. In addition, the CLR will compile all the code in the catch and finally blocks including all the methods called from within those blocks. This will eliminate a bunch of potential exceptions (including FileLoadException, BadImageFormatException, InvalidProgramException, FieldAccessException, MethodAccessException, MissingFieldException, and MissingMethodException) from occurring when trying to execute error recovery code (in catch blocks) or cleanup code (in the finally block). It will also reduce the potential for OutOfMemoryException and some other exceptions as well. I talk about CERs later in this chapter.
- Depending on where the state lives, you can use transactions which ensure that all state is modified or no state is modified. If the data is in a database, for example, transactions work well. Windows also now supports transacted registry and file operations (on an NTFS volume only), so you might be able to use this; however, the .NET Framework doesn’t expose this functionality directly today. You will have to P/Invoke to native code to leverage it. See the System.Transactions.TransactionScope class for more details about this.
Use finally Blocks Liberally
Ensuring that cleanup code always executes is so important that many programming languages offer constructs that make writing cleanup code easier. For example, the C# language automatically emits try/finally blocks whenever you use the lock, using, and foreach statements. The C# compiler also emits try/finally blocks whenever you override a class’s destructor (the Finalize method). When using these constructs, the compiler puts the code you’ve written inside the try block and automatically puts the cleanup code inside the finally block.Specifically:
- When you use the lock statement, the lock is released inside a finally block.
- When you use the using statement, the object has its Dispose method called inside a finally block.
- When you use the foreach statement, the IEnumerator object has its Dispose method called inside a finally block.
- When you define a destructor method, the base class’s Finalize method is called inside a finally block.
Don’t Catch Everything
A type that’s part of a class library should never, ever, under any circumstance catch and swallow all exceptions because there is no way for the type to know exactly how the application intends to respond to an exception. In addition, the type will frequently call out to application code via a delegate, virtual method, or interface method. If the application code throws an exception, another part of the application is probably expecting to catch this exception. The exception should be allowed to filter its way up the call stack and let the application code handle the exception as it sees fit.
If the exception is unhandled, the CLR terminates the process. Most unhandled exceptions will be discovered during testing of your code. To fix these unhandled exceptions, you will either modify the code to look for a specific exception, or you will rewrite the code to eliminate the conditions that cause the exception to be thrown. The final version of the code that will be running in a production environment should see very few unhandled exceptions and will be extremely robust.
Recovering Gracefully from an Exception
Sometimes you call a method knowing in advance some of the exceptions that the method might throw. Because you expect these exceptions, you might want to have some code that allows your application to recover gracefully from the situation and continue running.
Backing Out of a Partially Completed Operation When an Unrecoverable Exception Occurs—Maintaining State
Usually, methods call several other methods to perform a single abstract operation. Some of the individual methods might complete successfully, and some might not. For example, let’s say that you’re serializing a set of objects to a disk file. After serializing 10 objects, an exception is thrown. (Perhaps the disk is full or the next object to be serialized isn’t marked with the Serializable custom attribute.) At this point, the exception should filter up to the caller, but what about the state of the disk file? The file is now corrupted because it contains a partially serialized object graph. It would be great if the application could back out of the partially completed operation so that the file would be in the state it was in before any objects were serialized into it.
To properly back out of the partially completed operation, write code that catches all exceptions. Yes, catch all exceptions here because you don’t care what kind of error occurred; you need to put your data structures back into a consistent state. After you’ve caught and handled the exception, don’t swallow it—let the caller know that the exception occurred. You do this by re-throwing the same exception. In fact, C# and many other languages make this easy. Just use C#’s throw keyword without specifying anything after throw, as shown in the previous code.
Hiding an Implementation Detail to Maintain a “Contract”
In some situations, you might find it useful to catch one exception and re-throw a different exception. The only reason to do this is to maintain the meaning of a method’s contract.
Here is a good use of this technique: when a type constructor throws an exception that is not caught within the type constructor method, the CLR internally catches that exception and throws a new TypeInitializationException instead. This is useful because the CLR emits code within your methods to implicitly call type constructors. If the type constructor threw a DivideByZeroException,your code might try to catch it and recover from it but you didn’t even know you were invoking the type constructor. So the CLR converts the DivideByZeroException into a TypeInitializationException so that you know clearly that the exception occurred due to a type constructor failing; the problem wasn’t with your code.
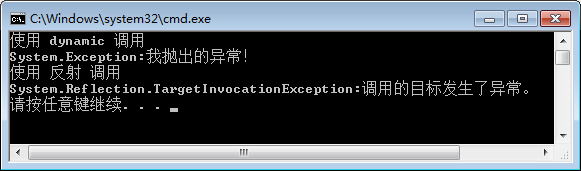
On the other hand, here is a bad use of this technique: when you invoke a method via reflection, the CLR internally catches any exception thrown by the method and converts it to a TargetInvocationException. This is incredibly annoying because you must now catch the TargetInvocationException object and look at its InnerException property to discern the real reason for the failure. In fact, when using reflection.
I have good news though: if you use C#’s dynamic primitive type (discussed in Chapter 5, “Primitive, Reference, and Value Types”) to invoke a member, the compiler-generated code does not catch any and all exceptions and throw a TargetInvocationException object; the originally thrown exception object simply walks up the stack. For many developers, this is a good reason to prefer using C#’s dynamic primitive type rather than reflection.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Threading.Tasks;
6 using System.Reflection;
7
8 namespace ExceptionManagementStudy
9 {
10 static class TargetInvocationExceptionStudy
11 {
12 internal static void Test()
13 {
14 try
15 {
16 Console.WriteLine("使用 dynamic 调用");
17 dynamic test = Activator.CreateInstance(typeof(TestClass));
18 test.TestMethod();
19 }
20 catch (Exception ex)
21 {
22 Console.WriteLine(ex.GetType() + ":" + ex.Message);
23 }
24
25 try
26 {
27 Console.WriteLine("使用 反射 调用");
28 object test = Activator.CreateInstance(typeof(TestClass));
29 test.GetType().GetMethod("TestMethod").Invoke(test,new object[0]);
30 }
31 catch (Exception ex)
32 {
33 Console.WriteLine(ex.GetType() + ":" + ex.Message);
34 }
35 }
36
37 private class TestClass
38 {
39 public void TestMethod()
40 {
41 throw new Exception("我抛出的异常!");
42 }
43 }
44 }
45 }
in an object-oriented platform, exception handling is not an option; it is mandatory. And besides, if you didn’t use it, what would you use instead? Would you have your methods return true/false to indicate success/failure or perhaps some error code enum type? Well, if you did this, then you have the worst of both worlds: the CLR and the class library code will throw exceptions and your code will return error codes. You’d have to now deal with both of these in your code.
If you write code to check the return value of every method call and filter the return value up to your own callers, your application’s performance will be seriously affected. But performance aside, the amount of additional coding you must do and the potential for mistakes is incredibly high when you write code to check the return value of every method. Exception handling is a much better alternative.
When defining types and their members, you should define the members so that it is unlikely that they will fail for the common scenarios in which you expect your types to be used. If you later hear from users that they are dissatisfied with the performance due to exceptions being thrown, then and only then should you consider adding TryXxx methods. In other words, you should produce the best object model first and then, if users push back, add some TryXxx methods to your type so that the users who experience performance trouble can benefit. Users who are not experiencing performance trouble should continue to use the non-TryXxx versions of the methods because this is the better object model.
Constrained Execution Regions (CERs)By definition, a CER is a block of code that must be resilient to failure. Because AppDomains can be unloaded, destroying their state, CERs are typically used to manipulate any state that is shared by multiple AppDomains or processes. CERs are useful when trying to maintain state in the face of exceptions that get thrown unexpectedly. Sometimes we refer to these kinds of exceptions as asynchronous exceptions. For example, when calling a method, the CLR has to load an assembly, create a type object in the AppDomain’s loader heap, call the type’s static constructor, JIT IL into native code, and so on. Any of these operations could fail, and the CLR reports the failure by throwing an exception.
The PrepareConstrainedRegions method is a very special method. When the JIT compiler sees this method being called immediately before a try block, it will eagerly compile the code in the try’s catch and finally blocks. The JIT compiler will load any assemblies, create any type objects, invoke any static constructors, and JIT any methods. If any of these operations result in an exception, then the exception occurs before the thread enters the try block.
When the JIT compiler eagerly prepares methods, it also walks the entire call graph eagerly preparing called methods. However, the JIT compiler only prepares methods that have the ReliabilityContractAttribute applied to them with either Consistency.WillNotCorruptState or Consistency. MayCorruptInstance because the CLR can’t make any guarantees about methods that might corrupt AppDomain or process state. Inside a catch or finally block that you are protecting with a call to PrepareConstrainedRegions, you want to make sure that you only call methods with the ReliabillityContractAttribute set as I’ve just described.
·




















