
算法与数据结构
BTree和B+tree
BTree
B树是为了磁盘或者其他存储设备而设计的一种多叉平衡查找树,相对于二叉树,B树的每个内节点有多个分支,即多叉。
参考文章:https://www.jianshu.com/p/da59af78ec59
B+Tree
B+树是B树的变体,也是一种多路搜索树。
参考文章:https://www.jianshu.com/p/da59af78ec59
排序算法
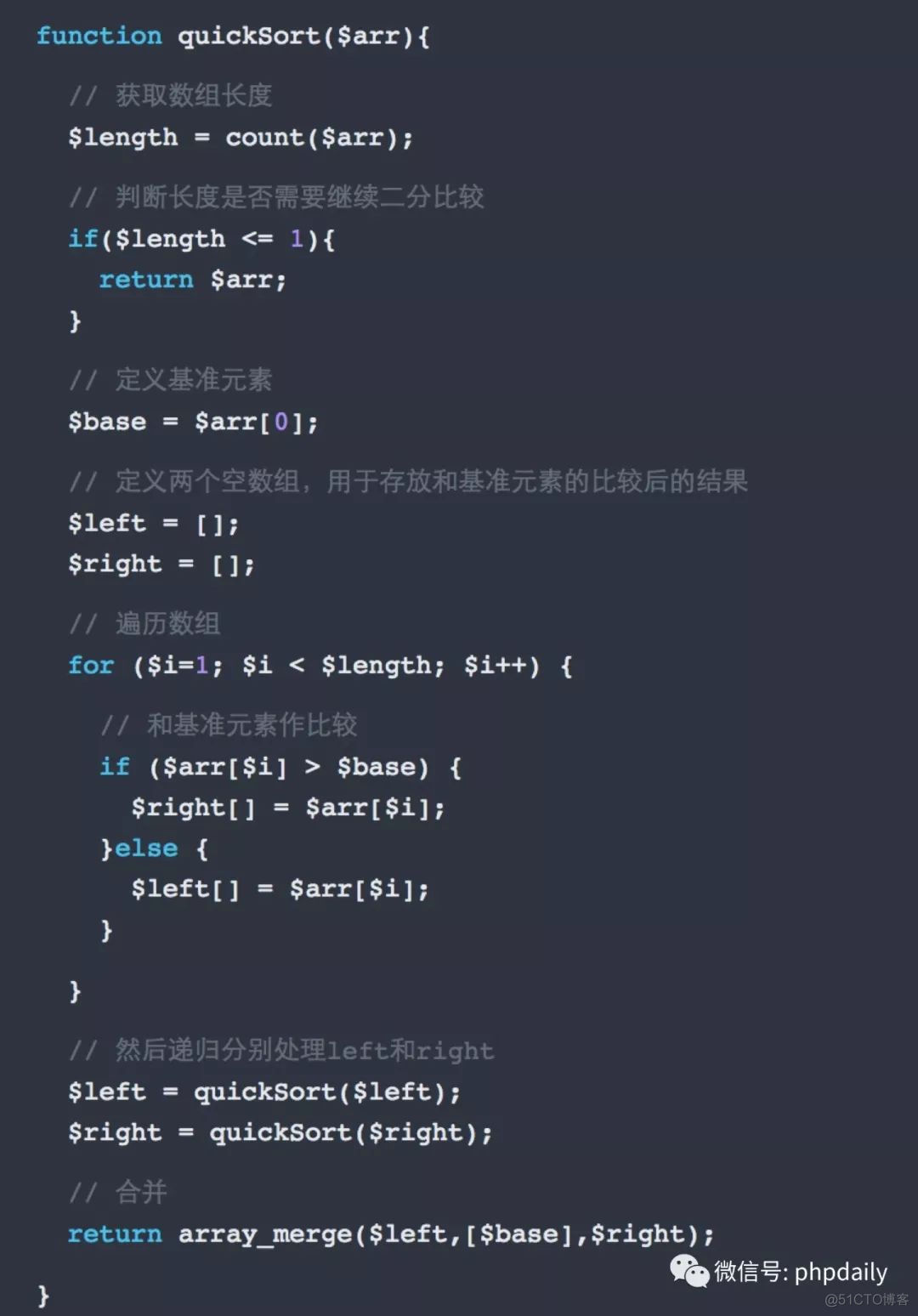
快速排序
快速排序是十分常用的高效率的算法,其思想是:先选一个标尺,用它把整个队列过一遍筛选,以保证其左边的元素都不大于它,其右边的元素都不小与它
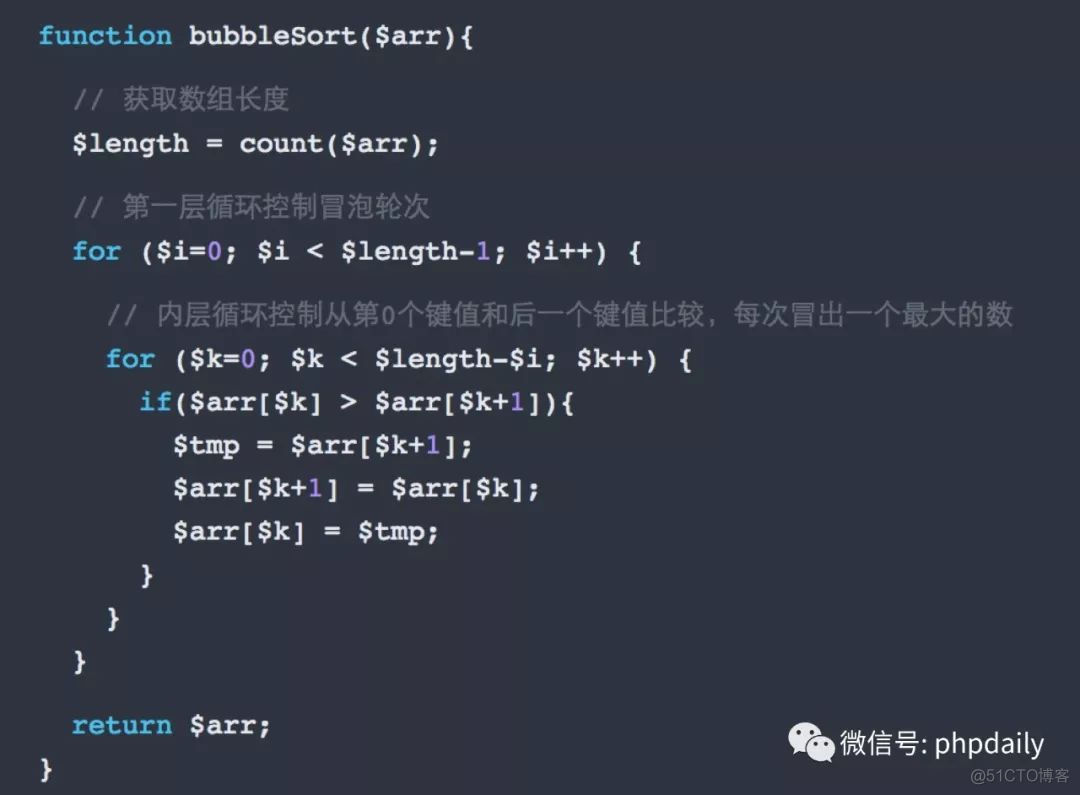
冒泡排序
思路:法如其名,就像冒泡一样,每次从数组中冒出一个最大的数。
比如:2,4,1
第一次冒出4:2,1,4
第二次冒出2:1,2,4
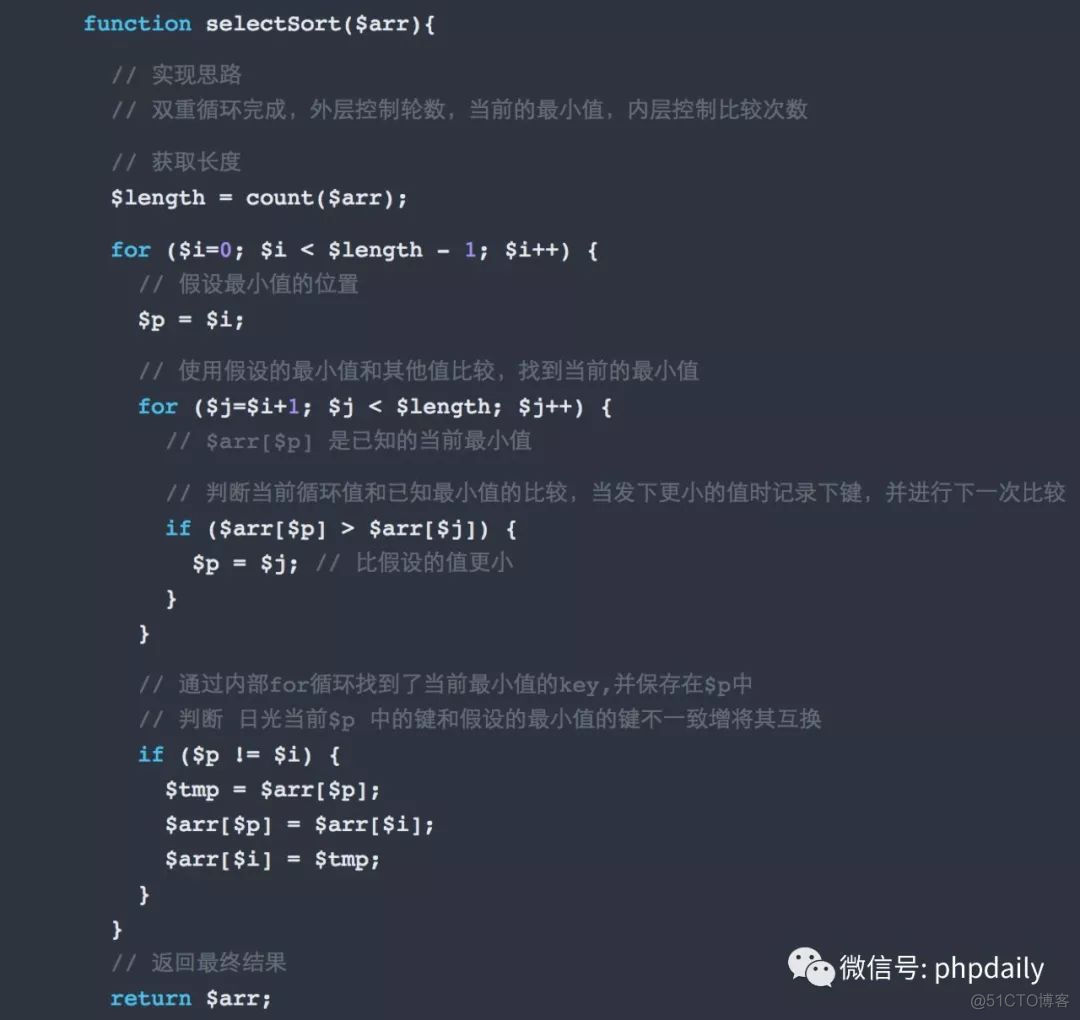
选择排序
思路:每次选择一个相应的元素,然后将其放到指定的位置
计算机网络
TCP/UDP区别
TCP
-
TCP是一种面向连接的、可靠的、基于字节流的传输层通信协议
-
TCP面向连接,提供可靠地数据服务
-
TCP首部开销20字节
-
TCP逻辑通信信道是全双工的可靠信道
-
TCP连接只能是点到点的
UDP
-
UDP是参考模型中一种无连接的传输层协议,提供面向事务的简单不可靠的信息传递服务
-
UDP无连接,不可靠
-
UDP首部开销8字节
-
UDP逻辑通信信道是不可靠信道
-
UDP没有拥塞机制,因此网络出现拥堵不会使源主机的发送效率降低
-
UDP支持一对一,多对一,多对多的交互通信
三次握手,四次挥手,为什么是三次握手四次挥手
在TCP/IP协议中,TCP协议提供可靠的连接服务,采用三次握手建立一个连接,完成三次握手,客户端与服务器开始传送数据。
简单点说:A与B建立TCP连接时,首先A向B发送SYN(同步请求),然后B回复SYN+ACK(同步请求应答),最后A回复ACK确认,这样TCP的一次连接(三次握手)就完成了。
TCP三次握手
所谓三次握手,是指简历一个TCP连接时需要客户端和服务器总共发送三个包
三次握手的目的是连接服务器指定端口,简历TCP连接,并同步连接双方的序列号并交换TCP窗口大小信息。
TCP三次握手图解:
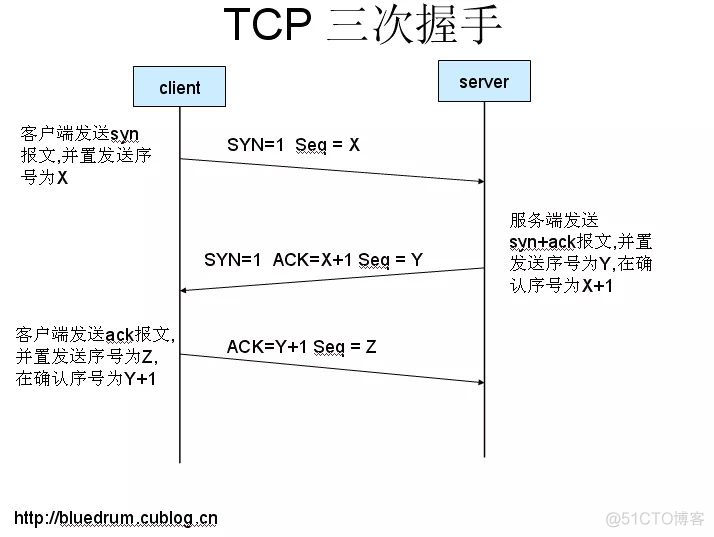
1.第一次握手
客户端发送一个TCP的SYN标志位置1的包,指明客户打算连接的服务器的端口,以及初始化序号,保存在包头的序列号字段里。
2.第二次握手
服务器发挥确认包应答,即SYN标志位和ACK标志均为1,同时将确认序号设置为客户的ISN加1,即X+1。
3.第三次握手
客户端再次发送确认包,SYN标识为0,ACK标识为1,并且把服务器发来的序号字段+1,放在确定字段中发送给对方,并且在数据字段写入ISN的+1。
简单解释TCP三次握手:参考https://github.com/jawil/blog/issues/14
四次挥手
TCP的连接的拆除需要发送四个包,因此称为四次挥手。客户端或服务器均可主动发起挥手动作。
由于TCP连接时全双工的,因此每个方向都必须单独进行关闭。这个原则是当一方完成他的数据发送任务后就能发送一个FIN来终止这个方向的连接。收到一个FIN只意味着这一方向上没有数据流动,一个TCP连接在收到一个FIN后仍能发送数据。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
为什么是三次握手四次挥手
这是因为服务端的LISTEN状态下的socket当收到SKY报文的简历连接的请求后,它可以把ACK和SYN放在一个报文里来发送。但关闭连接时,当收到对方的FIN报文通知时,他仅仅表示对方没有数据发送给你了,但未必你的所有数据都全部发送给对方了,所以你可以不是马上回关闭socket,即你可能还会发送一些数据给对方之后,在发送FIN报文给对方来表示你同意现在可以关闭连接了,所以这里的ACK和FIN报文多情况下都是分开发送的。
长连接和短连接
TCP在真正的读写操作之前,server和client之间必须建立一个连接,当读写操作完成后,双方不再需要这个链接时他们可能释放这个连接,连接的建立是通过三次握手,释放则需要四次挥手,所以说每个连接的建立都是需要消耗资源和时间的。
TCP短连接
-
client向server发起连接请求
-
server接到请求,双方建立连接
-
client向server发消息
-
server回应client
-
一次读写完成,此时双方任何一个都可以发起close操作
一般都是client先发起close操作,因为一般的server不会回复完client就立即关闭连接。
所以短连接一般只会在client和server间传递一次读写操作,短连接管理起来比较简单,存在的连接都是有用的连接,不需要额外的控制手段
长连接
-
client向server发起连接
-
server接到请求后,双方建立连接
-
client向server发送消息
-
server回应client
-
一次读写完成,连接不关闭
-
后续读写操作
长/短连接的操作过程
-
短连接的操作步骤:建立连接 -> 数据传输 -> 关闭连接
-
长连接的操作步骤:建立连接 -> 数据传输 -> (保持连接) -> 数据传输 -> 关闭连接
长/短连接的优缺点
-
长连接可以省去较多的TCP建立和关闭操作,减少资源浪费,节省时间,对于比较频繁的请求资源的客户端比较适用于长连接
-
短连接对于服务器来说管理较为简单,存在的连接都是有用的连接,不需要额外的控制手段
从浏览器输入域名到展示页面都发生了什么
DNS域名解析
先找本地hosts文件,检查对应域名ip的关系,有则想ip地址发送请求,没有再去找DNS服务器
建立TCP连接
拿到服务器IP后,向服务器发送求求,三次握手,建立TCP连接。
简单理解三次握手:
-
客户端:您好,在家不,有你快递
-
服务端:在的,送来吧
-
客户端:好滴,来了
发送HTTP请求
与服务器建立连接后,就可以向服务器发起请求了。具体请求内容可以在浏览器中查看。
服务器处理请求
服务器收到请求后由web服务器(Apache,Nginx)处理请求,web服务器解析用户请求,知道了需要调用那些资源文件,再通过相应的这些资源文件处理用户请求和参数,并调用数据库等,然后将结果通过web服务器返回给浏览器。
返回响应结果
在响应结果中都会有一个HTTP状态码,诸如我们熟知的200、404、500等。
状态码都是由三位数字和原因短语组成,大致为五类:
-
1XX 信息性状态码 接收的请求正在处理
-
2XX 成功状态码 请求正常处理完毕
-
3XX 重定向状态码 需要附加操作以完成请求
-
4XX 客户端错误状态码 服务器也无法处理的请求
-
5XX 服务器错误状态码 服务器请求处理出错
关闭TCP连接
为了避免服务器与客户端双方资源占用和消耗,当双方没有请求或者响应传递时,任意一方都可以发起关闭请求,与创建TCP连接的三次握手类似,关闭TCP连接需要4次挥手
简单比喻为:
-
客户端:哥们,我这边没有数据要传了,咱们关闭连接吧
-
服务端:好的,我看看我这边还有数据不
-
服务端:兄弟,我这边也没数据要传给你了,咱们可以关闭连接了
-
客户端:好嘞
浏览器解析HTML
浏览器布局渲染
设计模式
设计模式是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性。
单例模式
当需要保证对象只有一个实例的时候,单例模式是非常有用的。他把创建对象的控制权交给一个单一的点上,任何时候应用程序都只会存在且仅存在一个实例。单例类不应该能在类的外部进行实例化。
一个单例类应该具备以下几个因素:
-
必须拥有一个访问级别为 private的构造函数,用于阻止类被随意实例化
-
必须拥有一个保存类的实例的静态变量
-
必须拥有一个访问这个实例的公共静态方法,该方法通常被命名为 getInstance()
-
必须拥有一个私有的空的 clone方法,防止实例被克隆复制
简单实例:
-
class Single
-
{
-
public static $_instance;
-
-
private function __construct()
-
{
-
}
-
-
private function __clone()
-
{
-
}
-
-
public static function getInstance()
-
{
-
if (!self::$_instance) {
-
self::$_instance = new self();
-
}
-
return self::$_instance;
-
}
-
-
public function sayHi()
-
{
-
echo "Hi \n";
-
}
-
}
-
-
$single = Single::getInstance();
-
$single->sayHi();
工厂模式
工厂模式解决的是如何不通过 new建立实例对象的方法
工厂模式是一种类,它具有为你创建对象的某些方法,你可以使用工厂类创建对象而不使用 new。这样,如果你想要更改所创建的对象类型只需要更改工厂即可,使用该工厂的所有代码会自动更改。
工厂模式往往配合接口一起使用,这样应用程序就不必要知道这些被实例化的类的具体细节,只要知道工厂返回的是支持某个接口的类就可以方便的使用了。
简单举例:
-
/**
-
* 抽象出一个人的接口
-
* Interface Person
-
*/
-
interface Person
-
{
-
public function showInfo();
-
}
-
-
/**
-
* 一个继承于抽象人接口的学生类
-
* Class Student
-
*/
-
class Student implements Person
-
{
-
public function showInfo()
-
{
-
echo "这是一个学生 \n";
-
}
-
}
-
-
/**
-
* 一个继承于抽象人接口的老师类
-
* Class Teacher
-
*/
-
class Teacher implements Person
-
{
-
public function showInfo()
-
{
-
echo "这是一个老师 \n";
-
}
-
}
-
-
/**
-
* 人类工厂
-
* Class PersonFactory
-
*/
-
class PersonFactory
-
{
-
public static function factory($person_type)
-
{
-
// 将传入的类型首字母大写
-
$class_name = ucfirst($person_type);
-
-
if(class_exists($class_name)){
-
return new $class_name;
-
}else{
-
throw new Exception("类:$class_name 不存在",1);
-
}
-
}
-
}
-
-
// 需要一个学生
-
$student = PersonFactory::factory('student');
-
echo $student->showInfo();
-
-
// 需要一个老师的时候
-
$teacher = PersonFactory::factory('teacher');
-
echo $teacher->showInfo();
缓存相关
Redis和Memcached的区别
-
Redis和Memcache都是将数据存放在内存中,都是内存数据库。但是Memcache还可以缓存其他东西,比如图片、视频
-
Redis不只支持简单的k/v类型的数据,同时还提供list、set、hash等数据结构的存储
-
虚拟内存,当物理内存用完时Redis可以将一些很久没有用到的value交换到磁盘
-
过期策略,memcache在set时就指定,例如 setkey1008即永不过期,redis可以通过expire设定,例如: expire name10
-
分布式,设定memcache集群,利用magent做一主多从;redis也可以做一主多从。
-
存储安全,memcache挂掉后,数据没了;redis可以定期保存在磁盘(持久化)
-
灾难恢复,memcache挂掉后数据不可恢复;redis数据丢失后可以通过aof恢复
-
redis支持数据的备份,即master-slave模式的数据备份
-
应用场景不同:redis除了可以做nosql数据库之外,还能做消息队列、数据堆栈和数据缓存等。memcache适合于缓存sql语句、数据集、用户临时性数据、延迟查询数据和session等
redis有哪些数据结构
String
字符串类型是redis最基础的数据结构,首先键是字符串类型,而且其他几种结构都是在字符串类型基础上构建的。
字符串类型实际上可以是字符串、数字、二进制(图片、音频),单最大不能超过512M。
使用场景:
1.缓存
字符串最经典的使用场景,redis作为缓存层,mysql作为存储层,绝大部分请求数据都是redis中获取,由于redis具有支撑高并发特性,所以缓存通常能起到加速读写和降低后端压力的作用。
2.计数器
许多应用都会使用redis作为技术的基础工具,它可以实现快速技术、查询缓存的功能。
3.共享session
处于负载均衡的考虑,分布式服务会将用户信息的访问均衡到不同服务器,用户刷新一次访问可讷讷个会需要重新登录,为了避免这个问题可以使用redis将用户session集中管理,在这种模式下只要保证redis的高可用和扩展性,每次获取用户更新或查询登录信息都直接从redis中集中获取。
4.限速
出于安全考虑,每次进行登录时让用户输入手机验证码,为了短信接口不被频繁访问,会限制用户每分钟获取验证码的频率。
Hash
在redis中哈希类型是指键本身又是一种键值对结构,如 value={{field1,value1}...{fieldn,valuen}}
使用场景:
哈希结构相对于字符串序列化缓存信息更加直观,并且在更新操作上更加便捷。
list
列表类型是用来存储多个有序的字符串,列表的每个字符串成为一个元素,一个列表最多可以存储2的32次方减1个元素。在redis中,可以对列表插入(push)和弹出(pop),还可以获取指定范围的元素列表。列表是一种比较灵活的数据结构,它可以充当栈和队列的角色。
使用场景:
1.消息队列
redis的 lpush+brpop命令组合就可以实现阻塞队列,生产者客户端是用 lpush从列表左侧插入元素,多个消费者客户端使用 brpop命令阻塞式的抢列表尾部的元素,多个客户端保证了消费的负载均衡的高可用性。
2.使用技巧列表
-
lpush+lpop=Stack(栈)
-
lpush+rpop=Queue(队列)
-
lpush+ltrim=Capped Collection(有限集合)
-
lpush+brpop=Message Queue(消息队列)
set
sortedset
redis是单线程的么,为什么?
因为CPU并不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那么久顺理成章的采用了单线程的方案。
当然单个Redis进程是没办法使用多核的 ,但是它来就不是非常计算密集型的服务。如果单核性能不够用,可以多开几个进程。
redis的部署方式,主从、集群
redis的哨兵模式
redis的持久化策略
RDB(快照持久化)
AOF(只追加文件持久化)
PHP基础
1.双引号单引号区别
-
双引号解释变量,单引号不解释变量
-
双引号里插入单引号,其中单引号里如果有变量的话,变量解释
-
双引号的变量名后面必须要有一个非数字、字母、下划线的特殊字符,或者用{}讲变量括起来,否则会将变量名后面的部分当做一个整体,引起语法错误
-
能使单引号字符尽量使用单引号,单引号的效率比双引号要高
2.GET和POST提交方式的区别
-
GET产生一个TCP数据包;POST产生两个TCP数据包;
-
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据)
-
对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
-
-
GET在浏览器回退时是无害的,而POST会再次提交请求
-
GET请求会被浏览器主动cache,而POST不会,除非手动设置
-
GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留
-
GET请求只能进行url编码,而POST支持多种编码方式
-
GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息
3.如何获取客户端的真实ip
$_SERVER['REMOTE_ADDR']或getenv('REMOTE_ADDR')可以使用 ip2long()转成数字。
4.include和require的区别
require是无条件包含,也就是如果一个流程里加入require,无论条件成立与否都会先执行require,当文件不存在或者无法打开的时候,会提示错误,并且会终止程序执行。
include有返回值,而require没有(可能因为如此require的速度比include快),如果被包含的文件不存在的化,那么会提示一个错误,但是程序会继续执行下去。
注意:包含文件不存在或者语法错误的时候require是致命的,而include不是。
5.AJAX的优势是什么
ajax是异步传输技术,可以通过javascript实现,也可以通过JQuery框架实现,实现局部刷新,减轻了服务器的压力,也提高了用户体验。
6.在程序的开发中,如何提高程序的运行效率
-
优化SQL语句,查询语句中尽量不使用select *,用哪个字段查哪个字段;
-
少用子查询可用表连接代替;
-
少用模糊查询;
-
数据表中创建索引;
-
对程序中经常用到的数据生成缓存;
7.SESSION与COOKIE的区别
-
存储位置:session存储在服务器,cookie存储在浏览器
-
安全性:session安全性高于cookie
参考链接:https://www.zhihu.com/question/19786827
8.isset和empty的区别
isset()函数 一般用来检测变量是否设置
-
若变量不存在则返回 FALSE
-
若变量存在且其值为NULL,也返回 FALSE
-
若变量存在且值不为NULL,则返回 TURE
empty()函数是检查变量是否为空
-
若变量不存在则返回 TRUE
-
若变量存在且其值为""、0、"0"、NULL、、FALSE、array()、var $var; 以及没有任何属性的对象,则返回 TURE
-
若变量存在且值不为""、0、"0"、NULL、、FALSE、array()、var $var; 以及没有任何属性的对象,则返回 FALSE
9.数据库三范式
-
第一范式:1NF是对属性的原子性约束,要求属性具有原子性,不可再分解;
-
第二范式:2NF是对记录的惟一性约束,要求记录有惟一标识,即实体的惟一性;
-
第三范式:3NF是对字段冗余性的约束,即任何字段不能由其他字段派生出来,它要求字段没有冗余。
10.主键、外键和索引的区别
定义
-
主键--唯一标识一条记录,不能有重复的,不允许为空
-
外键--表的外键是另一表的主键, 外键可以有重复的, 可以是空值
-
索引--该字段没有重复值,但可以有一个空值
作用
-
主键--用来保证数据完整性
-
外键--用来和其他表建立联系用的
-
索引--是提高查询排序的速度
个数
-
主键--主键只能有一个
-
外键--一个表可以有多个外键
-
索引--一个表可以有多个唯一索引
11.堆和栈的区别
栈是编译期间就分配好的内存空间,因此你的代码中必须就栈的大小有明确的定义。
堆是程序运行期间动态分配的内存空间,你可以根据程序的运行情况确定要分配的堆内存的大小。
PHP包管理器Composer与自动加载规范
composer学习地址:http://docs.phpcomposer.com/00-intro.html
composer.json中的自动加载映射
目前 PSR-0自动加载、 PSR-4自动加载、 classmap生成和 files引入都是被支持的, PSR-4是首推的方法,因为它提供了更大的易用性。
PSR-4
PSR-4规范了如何指定文件路径从而自动加载类,同时规范了自动加载文件的位置。乍一看这是和PSR-0重复了,实际上,在功能上确实有一部分重复。区别在于,PSR-4的规范比较干净,去除了兼容PHP5.3以前版本的内容。
PSR-4和PSR-0最大的区别是对下划线的定义不同,PSR-4中,在类名中使用下划线是没有特殊含义的,而在PSR-0的规则中,下划线或被转化为目录分隔符。
在PSR-4的键下,你可以定义命名空间和路径的映射关系,当自动加载类如 Foo\\Bar\\Baz时,命名空间 Foo指向一个名为 src/的目录意味着自动加载器将查找名为 src/Bar/Baz.php文件并引用它。
命名空间的前缀必须以 \\结尾,以避免类似前缀之间的冲突。在安装和更新期间,PSR-4引用全部组合到一个 key=>value数组中,该数组可以在生成的文件 vendor/composer/autoload_psr4.php中找到。
例子:
-
{
-
"autoload": {
-
"psr-4": {
-
"App\\": "App/" // 命名空间App映射到目录App
-
}
-
}
-
}
classmap
classmap引用的所有组合,都会在安装、更新的过程中生成并存储到 vendor/composer/autoload_classmap.php文件中。
你可以使用classmap生成支持自定义加载的不遵循 PSR-4规范的类库,要配置它指向的目录,以便能够准确的搜索到类文件
例子:
-
{
-
"autoload": {
-
"classmap": ["src/", "lib/", "Something.php"]
-
}
-
}
Files
如果你想要明确指定,在每次请求时都要载入某些文件,那么你可以使用 files字段加载。通常作为函数库的载入方式。
例子:
-
{
-
"autoload": {
-
"files": ["src/MyLibrary/functions"]
-
}
-
}
PHP框架
-
Laravel相关
前端相关
-
JavaScript
-
VueJS
-
VueJs双向数据绑定原理。
-
Linux
Cors跨域
CORS的基本原理是通过设置HTTP请求和返回中header,告知浏览器该请求是合法的。这涉及到服务器端和浏览器端双方的设置:请求的发起(Http Request Header)和服务器对请求正确的响应(Http response header)。
参考文章:https://zhuanlan.zhihu.com/p/24411090



















