
分布式训练

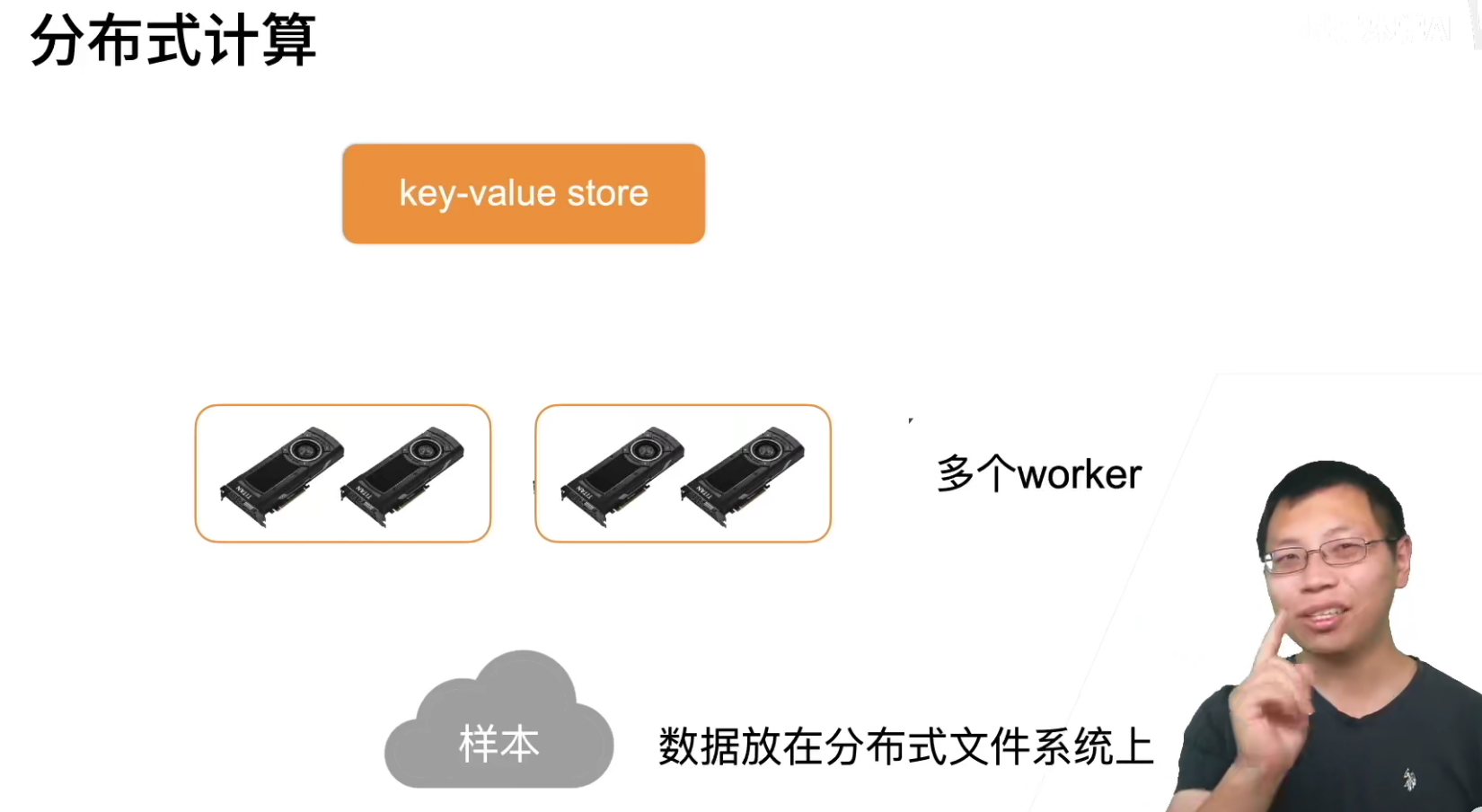

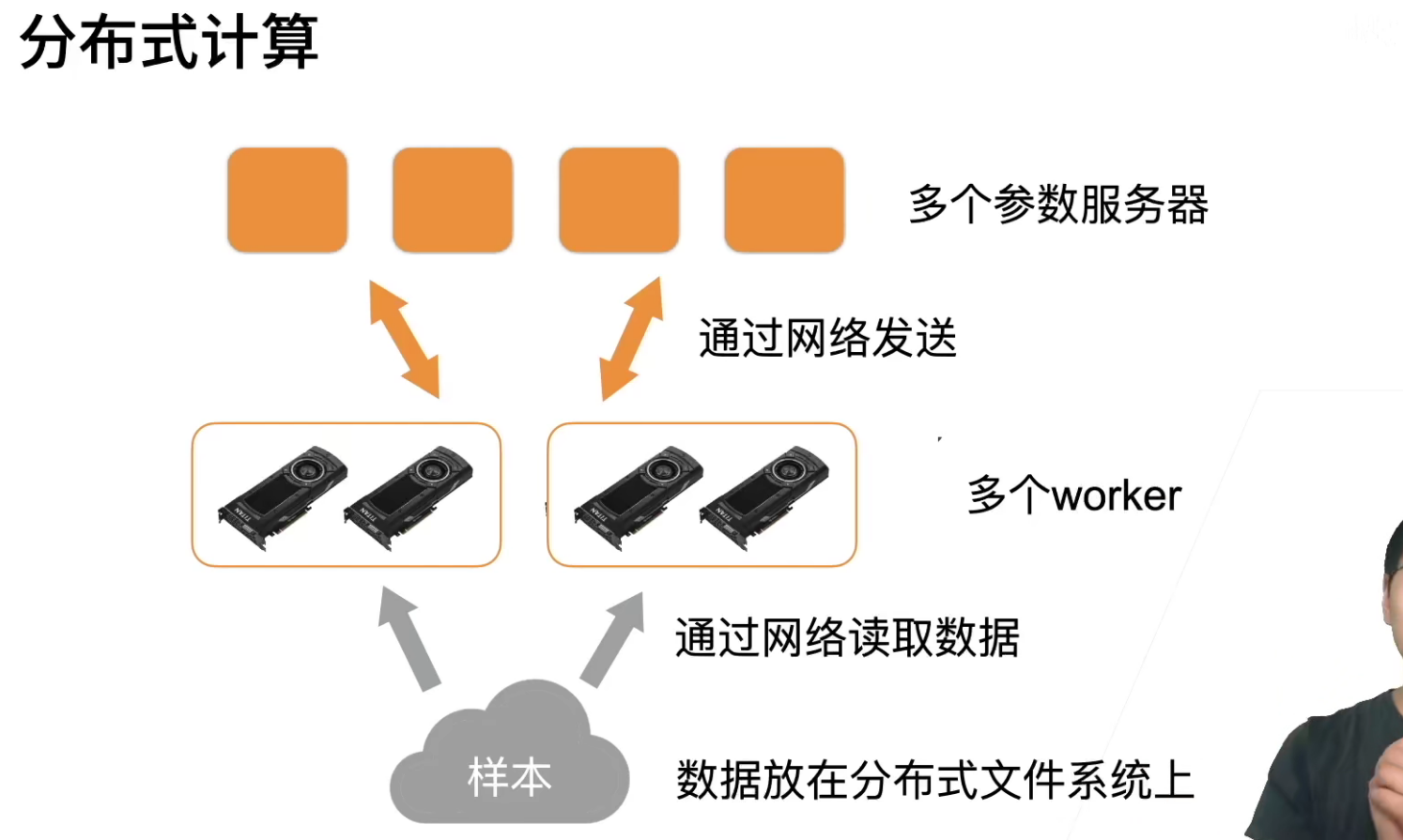
其实分布式和单机多卡在逻辑上没有什么区别,只不过读数据之前从磁盘读取,现在换成了从网络读取;交换梯度之前通过内存处理,现在通过网络交换梯度。

下面是一个具体样例,看看分布式如何减少跨机器的通讯。






现在本机将梯度加起来,在进行发送。





这个就是epoch和batch_size有一个权衡....


QA
- 为什么batch_size变大,训练的有效性是下降的?
沐神说直观上解释一下,一个极端情况,就是所有数据集的样本都是一个样本,就一张图片,然后复制一万份,那么不管batch_size取多大,所有的梯度都是一样的。
也就是说,如果这个数据集不够大,数据多样性不够多,那么其实batch_size再大也是浪费计算。
如果batch_size=128和batch_size=512训练出来的精度是差不多的,那么当然batch_size越小越好了,因为可以更加参数更新的次数,减少计算量,加速收敛。
一个直观的做法,如果有n个类,那么batch_size最好不要超过10n。比如fashion-mnist有10个类,那么batch_size=128是不错的,ImageNet有1000类,那么batch_size取1w,甚至取10w(因为图片类别很多)都是可以的。
本文章为转载内容,我们尊重原作者对文章享有的著作权。如有内容错误或侵权问题,欢迎原作者联系我们进行内容更正或删除文章。




















