
在Oracle Data Science的notebook里面带有21个让大家快速上手的例子,可以通过下面的操作获取。
在做数据探索之前,我们将后续要使用的module和相关内容先import进来,如下图所示,这个操作不会有结果输出,仅仅是将这些module和method或function加载到内存当中。关于这些module的载入,如果大家不想每次都写这么多内容,而且也担心载入的内容没用到而浪费了资源,或者后面想用的module,在前面没有载入而报错,那么可以使用一个叫做pyforest的module,只要使用pip install pyforest进行安装,然后在notebook的第一行写入from pyforest import * ,在后续的代码中,直接使用您要用到的函数或者方法就可以了。但这真的是最好的选择吗?如果有函数在不同的module当中同名,但是表达不同的含义,怎么办呢?所以这个东西,不建议初学者使用,但即便是数据科学的老专家,也应该谨慎使用才是。
import warningsimport loggingwarnings.filterwarnings('ignore')logging.basicConfig(format='%(levelname)s:%(message)s', level=logging.ERROR)import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom ads.dataset.factory import DatasetFactoryfrom ads.dataset.dataset_browser import DatasetBrowser
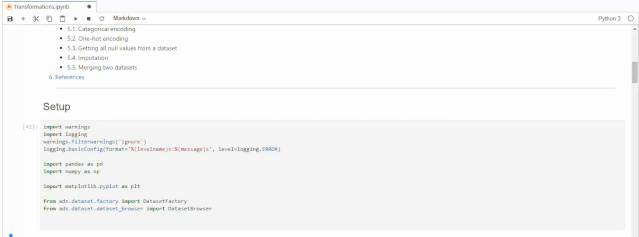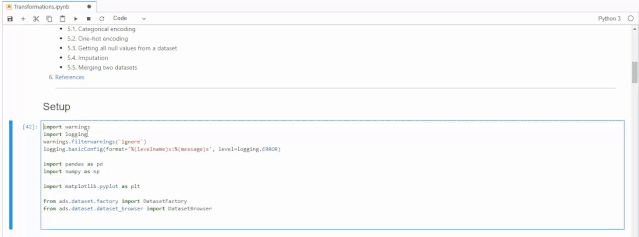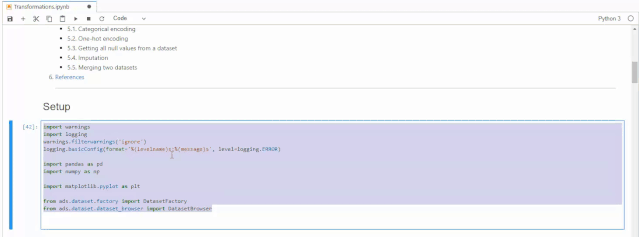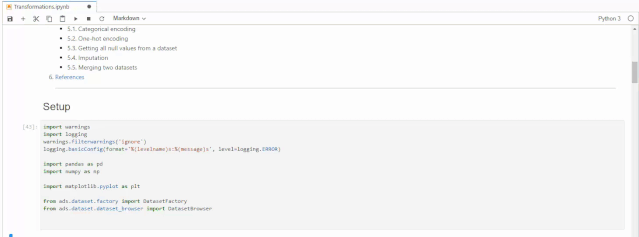
接下来我们载入数据,本次使用的是sklearn自带的经典数据集Iris,这个数据集是常用的分类实验数据集,由Fisher, 在1936收集整理。这个数据集也叫做鸢尾花卉数据集,它是一类多重变量分析的数据集。数据集当中包含150个数据样本,分为个3类,每类50个数据,每个数据包含4个特征。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个特征预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一种。执行下面代码之后,系统会给出建议,建议我们使用show_in_notebook()来了解数据的基本情况,以及使用suggest_recommendations()对数据中的缺失值进行处理。
sklearn = DatasetBrowser.sklearn()iris_ds = sklearn.open('iris').set_target("target")
接下来我们使用show_in_notebook()查看一下数据的基本情况。
iris_ds.show_in_notebook()
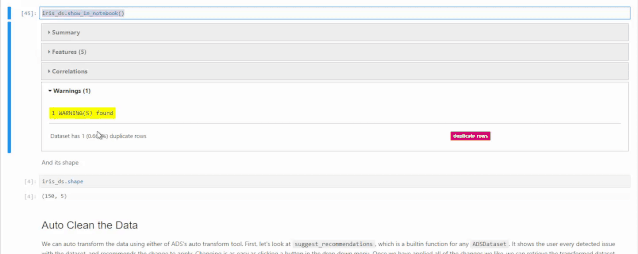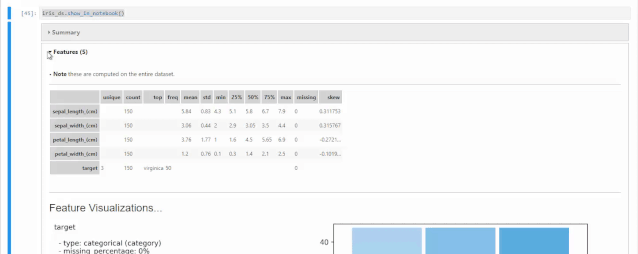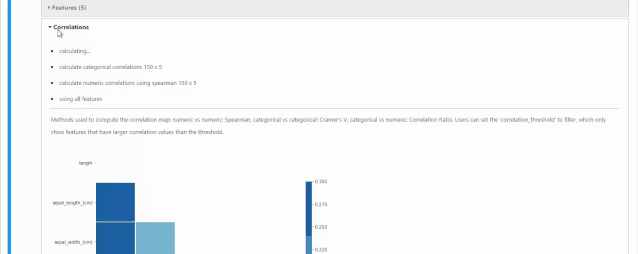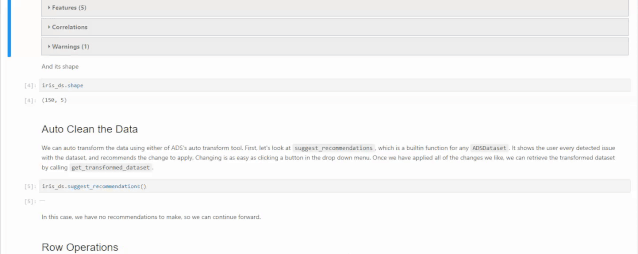
可以通过shape属性,查看数据集的row数量和column数量,与我们之前描述的一样,150行5个columns,其中4个特征,一个target。
iris_ds.shape
 我们在项目中的数据,一般质量都不会达到100%满足数据分析与预测的需求,或多或少都会出现缺失值,比如在之前教程当中我们提到的seaborn当中的经典数据集titanic,里面就有好多columns包含缺失值。对于缺失值的处理,我们不能简单粗暴地使用dropna()将它删除,或者使用fillna()对他们做统一的填充,因为dropna()会导致重要属性缺失,对后面模型的训练及值的预测都造成负面影响。而简单的fillna()也会导致训练集的数据与分布出现失真,导致模型训练失败出现overfitting的情况。在通常的情况下,我们会使用sklearn当中的imputer对象对于缺失值进行处理,但是imputer对象使用起来稍微有一点点复杂,并且随着sklearn版本的变更,之前使用的imputer代码很可能出现无法复用的情况。而在Oracle Data Science当中,可以使用DataFactory的suggest_recommendations()方法,对数据集进行impute操作。我们在之前的课程中,在处理titanic数据集的时候,已经讲过,在这里不再赘述。因为本次iris数据集没有缺失值,所以对这个数据集使用suggest_recommendations()方法,不会得到建议。
我们在项目中的数据,一般质量都不会达到100%满足数据分析与预测的需求,或多或少都会出现缺失值,比如在之前教程当中我们提到的seaborn当中的经典数据集titanic,里面就有好多columns包含缺失值。对于缺失值的处理,我们不能简单粗暴地使用dropna()将它删除,或者使用fillna()对他们做统一的填充,因为dropna()会导致重要属性缺失,对后面模型的训练及值的预测都造成负面影响。而简单的fillna()也会导致训练集的数据与分布出现失真,导致模型训练失败出现overfitting的情况。在通常的情况下,我们会使用sklearn当中的imputer对象对于缺失值进行处理,但是imputer对象使用起来稍微有一点点复杂,并且随着sklearn版本的变更,之前使用的imputer代码很可能出现无法复用的情况。而在Oracle Data Science当中,可以使用DataFactory的suggest_recommendations()方法,对数据集进行impute操作。我们在之前的课程中,在处理titanic数据集的时候,已经讲过,在这里不再赘述。因为本次iris数据集没有缺失值,所以对这个数据集使用suggest_recommendations()方法,不会得到建议。
iris_ds.suggest_recommendations()

 数据行的操作
数据行的操作
1、数据过滤
在处理pandas当中的DataFrame有好多种数据过滤的方法,Oracle Data Science当中的DataFactory我们暂且将它看出pandas当中DataFrame的一个升级,我们可以使用DataFrame的函数与方法对DataFactory对象进行处理。我们知道在DataFrame当中,有一个“看不见”的column,叫做index。一般情况下,index是从0开始的一个整数。当然,您完全可以按照自己的想法,将DataFrame当中的column(s)作为index使用,关于这个index,我们可以单独拿出一期来讲,介绍单层index,分层index及index的转换等等操作。今天我们先不展开介绍。
对数据行进行过滤的一种方式就是通过index,我们可以通过对index进行slicing,来取得DataFrame的部分数据。比如下方的操作:我们将原始数据中index为2及其以后的数据行拿出来,创建出一个新的DataFactory对象叫做iris_minus_2,通过观察,发现新的数据集的index是从2开始的。这里需要注意的是,如果对新的iris_minus_2对象使用type()查看它的数据类型,会是什么?虽然也是DataFrame,但是我们所熟悉的那个pandas当中的DataFrame吗?不是吧。如果你强制将iris_minus_2转换为我们熟悉的pandas当中的DataFrame,那么下面代码执行的结果也许会大不相同了。会是什么?感兴趣的小伙伴,自己动手做一下吧。
iris_minus_2 = iris_ds.loc[2:]iris_minus_2.head()

我们可以使用reset_index()对iris_minus_2进行index重置,让它变成从0开始的整数。
iris_minus_2 = iris_minus_2.reset_index()iris_minus_2.head()

很显然,上面的数据“过滤”方式不是我们经常使用的,我们更常使用的是类似SQL当中的where语句,将满足条件的记录检索出来。在下面的代码中,第一行,我们将iris这个数据集当中target的值为setosa的记录检索出来,并将值赋给iris_setosa这个对象。并在第二行当中,分别取得iris_setosa各个column的平均值、方差和标准差。
iris_setosa = iris_ds[iris_ds['target']=='setosa']pd.DataFrame([iris_setosa.mean(), iris_setosa.var(),iris_setosa.std()], index=['mean', 'var','std'])

2、删除重复记录
我们在项目当中,经常会将多种数据汇集在一起形成一个新的数据集,在这个过程中很难避免出现重复记录,一般情况下,我们会将重复的记录删除。那么我们先说一下什么是重复的记录,所有的columns的值都相同的记录,被认为是重复记录。在我们今天的数据集当中,有两条记录是相同的,我们使用drop_duplicates()将重复记录删除,只保留1条。在下面的代码中,第一行,首先将DataFactory对象使用to_pandas_dataframe()将它变成一个pandas的DataFrame对象,然后使用duplicated()方法,统计重复的记录。之后使用drop_duplicates()将重复记录删除。通过查看结果,发现原来150条记录,变成149条了。
print(sum(iris_ds.to_pandas_dataframe().duplicated()))iris_without_dup = iris_ds.drop_duplicates()iris_without_dup.shape

column操作
在Oracle Data Science中的ADSDatasets(可以认为是我们之前创建的DataFactory对象)与pandas中的DataFrame几乎有相同的操作方法,所以对于DataFrame所使用的方法与函数,一般也适用于ADSDatasets。
1、column的删除
我们在处理原始数据的时候,有些columns是干扰项或者对于数据分析与预测没有帮助,甚至会存在Data Leakage的情况,所以这些columns需要被删除。
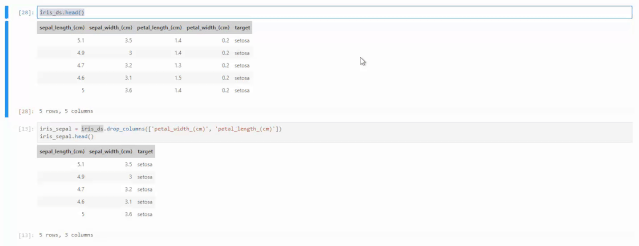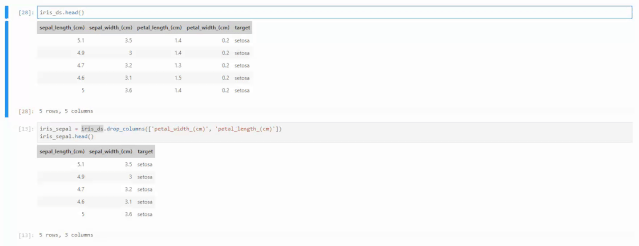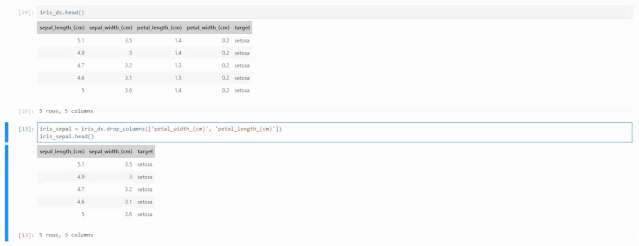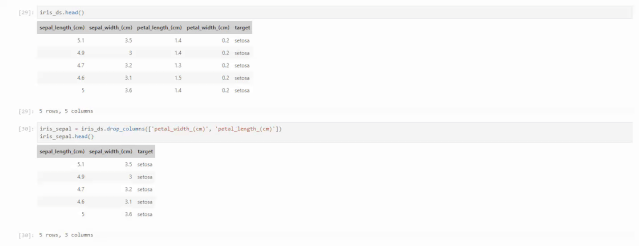
删除columns的方法很简单,只需要对数据集使用drop_columns()方法,在参数部分,使用list的形式将被删除的column name提供出来即可。在下方的例子当中,在删除之前有5个columns,删除两个columns之后,再使用head()方法查询记录的情况,发现只有3个了。
iris_sepal = iris_ds.drop_columns(['petal_width_(cm)', 'petal_length_(cm)'])iris_sepal.head()
2、添加columns
在Oracle Data Science当中的数据集添加columns,将使用assign_column()方法,与我们在pandas中对DataFrame有一点不同,在pandas当中我们直接给出新的column就可以,比如之前在DataFrame当中没有一个column叫做‘test’,我们只要直接给出就可以了,比如ds['test']='xxxxx'。在Oracle Data Science当中可以这样来实现,比如下方的代码,我们创建了一个新的column叫做petal_minus_sepal_col,里面的值来自iris_ds数据集中的两个字段相减之后的结果。然后对iris_ds数据集使用assign_column(),提供两个参数,第一个参数是column name,第二个参数是value,需要注意的是,在第二个参数中,使用了compute()方法启动计算功能。这个写法与pandas不同,我们在使用的时候需要注意。
petal_minus_sepal_col = (iris_ds['petal_length_(cm)'] - iris_ds['sepal_length_(cm)'])iris_petal_minus_sepal = iris_ds.assign_column('petal_minus_sepal', petal_minus_sepal_col.compute())iris_petal_minus_sepal.head()每个人的使用习惯不同,我更喜欢使用pandas,所以为了实现上面的效果,可以使用如下代码,首先
df=iris_ds.to_pandas_dataframe()df['petal_minus_sepal_col']=df['petal_length_(cm)']-df['sepal_length_(cm)']df.head()
通过观察下面运行的结果,发现效果相同,至于使用哪一种,完全由编程者来决定。

3、过滤column
就和SQL当中的column list一样,在数据处理的过程中,也不会将所有的columns或者叫做features都拿出来进行计算,可以根据情况,选择特定的features。在Oracle Data Science当中的具体的方法和pandas对DataFrame的处理方法是一样的,只要在数据集后面使用list的方式给出columns list就可以了。比如下方的例子,选取petal_length_(cm)和sepal_length_(cm)两个columns中的所有记录。
iris_filtered = iris_ds[['petal_length_(cm)', 'sepal_length_(cm)']]iris_filtered.head()
也可以像下面的代码中的写法,对特定的column进行条件设定,检索出满足条件的记录。
iris_filtered = iris_filtered[iris_ds['petal_length_(cm)'] > 6][iris_ds['sepal_length_(cm)'] < 7.5]iris_filtered.head()

4、column重命名
我们从客户那里获取的数据,feature name或者说是column name经常是千奇百怪,不只是名字本身写法奇怪,往往还会遇到将关键字作为column name的情况。为了避免在后续数据处理过程中由于名字不对而出错,或者只是简单地将column name设定为更有意义的名字,我们都要使用column重命名技术。
首先我们可以通过如下代码,查看一下原有的column name,然后对数据集使用rename_columns()进行改名。
iris_ds.columns
iris_renamed = iris_ds.rename_columns({'sepal_length_(cm)': 'sepal_length', 'sepal_width_(cm)': 'sepal_width', 'petal_length_(cm)': 'petal_length', 'petal_width_(cm)': 'petal_width'})然后再使用iris_ds.columns查看改名后的效果。

5、转换column数据类型
这个操作大家一定谨慎使用,就如在数据库中对已经存在数据的表,做字段类型转换一样,存在风险,比如下方的代码,我们将浮点型数据,使用astype()强制转换成datatime类型,然后查询结果的时候,发现字段的数据类型已经被转换成功,但是数据已经面目全非了,这种情况我们应该避免发生。
iris_datetime = iris_ds.astype({'sepal_length_(cm)': 'datetime'})iris_datetime.feature_types['sepal_length_(cm)']['type']
6、String类型的column操作
对于String类型数据的操作ADSDataSets的操作方法,与pandas当中的DataFrame几乎完全一致。比如想按照target进行分组,然后统计每组当中的成员数,类似SQL当中的group by与count(*)
iris_ds['target'].value_counts().compute()

或者我们常用的简化函数lambda与apply。
iris_ds['target'].apply(lambda x: str(x)[:-5]).value_counts().compute()

常规数据集操作
1、特征处理
说到特征工程处理,我们常见的有如下这些编码方式:
Backward Difference Coding
BaseN
Binary
CatBoost Encoder
Hashing
Helmert Coding
James-Stein Encoder
Leave One Out
M-estimate
One Hot
Ordinal
Polynomial Coding
Sum Coding
Target Encoder
Weight of Evidence
Label encoding
而在这些编码方式中,我们常用的是label encoding和one hot encoding。关于label encoding的使用要注意,比如原来的column value是博士、硕士、学士,编码之后变成0,1,2,如果简单地当他们是数值型数据参与模型训练的时候,会出现模型不健康的情况,因为学位这个column当中的值原本没有倍数关系,但是label encoding之后,出现了倍数关系。one hot encoding是另外一个我们常用的用于扩充特征的编码方式,使用的时候也要注意,如果某个column的values种类过多,那么就会出现one hot encoding之后,features过多而导致算力要求激增以及overfitting的情况发生。
下面是一个label encoding的例子,请注意观察下图中红色框所标记的内容。原来具体的花卉种类名称被使用序号代替了。
from ads.dataset.label_encoder import DataFrameLabelEncoderiris_encoded = DataFrameLabelEncoder().fit_transform(iris_ds.to_pandas_dataframe())iris_encoded['target'].value_counts()
iris_encoded.sample(frac=.05)

接下来我们看一个one hot encoding的例子。
我们还是使用之前提到的保险费用的数据文件,在里面有一个region的column,里面有4种值,使用pandas当中的get_dummies()方法处理之后的效果如下面图片中红框所示,是不是和Oracle当中的位图索引比较相似?为什么要做one hot encoding呢?因为机器学习或者神经网络中大多都是数学算法,如果像下例中的region是具体的地区,那么让模型处理这些非数值型的数据比较困难或者无法处理,所以通过one hot encoding或者其他的编码方式,将这些非数值型数据进行数值化,然后方便模型处理。
df = pd.read_csv('insurance.csv')df.head()df1 = pd.get_dummies(df['region'], prefix='Region')df1.head()

2、空值处理
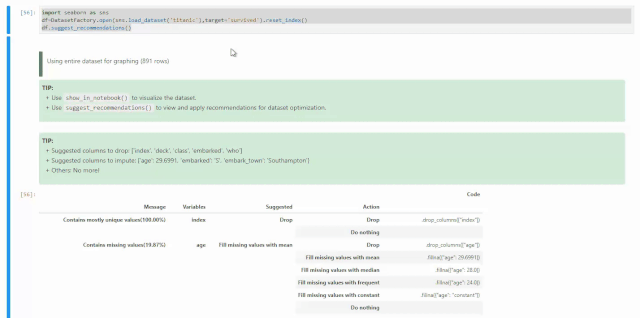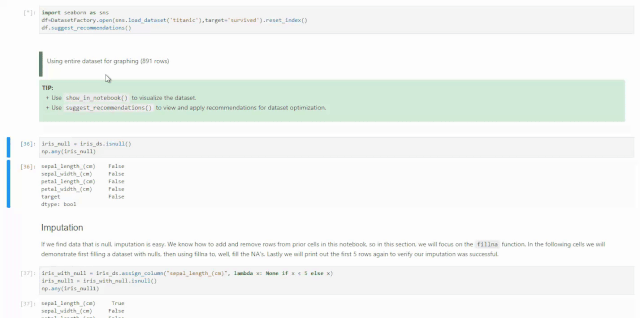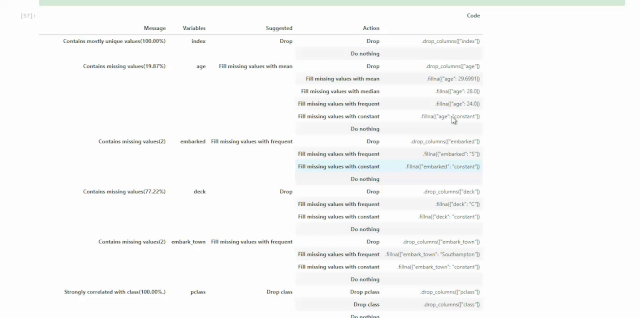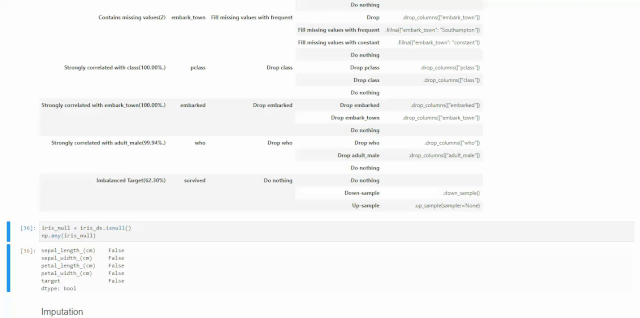
关于空值的处理,我们可以在刚拿到数据的时候,对DataFactory对象使用suggest_recommendations()获取空值处理建议。比如下面我们还是使用seaborn自带的数据集titanic为例,我们知道这个数据集当中很多columns都带有空值。
import seaborn as snsdf=DatasetFactory.open(sns.load_dataset('titanic'),target='survived').reset_index()df.suggest_recommendations()通过下面动图发现,ADS给出的建议与前几天的视频内容有点不一样,因为Oracle Data Science在不断升级,之前使用的是get_recommendations()方法,如果现在还使用这个方法会被提示该方法即将下线,请使用suggest_recommendations()方法。另外,现在是直接将可以进行的动作以及相应的代码打印的屏幕上供使用者调用。
关于数据集的处理还有好多技术,可以讲上几个星期,更多的内容请参考pandas的官方文档以获取更多资讯。
相关链接:
Oracle数据科学公开课(2):OCI Data Science Tenancy Setup
Oracle数据科学公开课(3): Resource Stack
Oracle数据科学公开课(4):Notebook的创建与管理
Oracle数据科学公开课(5):JupyterLab环境详解
Oracle数据科学公开课(6):Notebook Session Enviroment
Oracle数据科学公开课(7):ADS Python SDK
Oracle数据科学公开课(8):ADS Connectivity to Data
Oracle数据科学公开课(10):Data profiling
手把手教你:使用Oracle Data Science分析纽约民宿数据


















