
最近听到一个很高大上的职位叫做“数据科学家”,这个职位中的“数据”和“科学家”两个关键词一个比一个厉害,我们当前处于“数据”时代,而“科学家”则是从小进学校就崇拜的一个职业。
那数据科学是什么,数据科学家这个职业做些什么事情?本文给大家分享下我的总结。
什么是数据科学
来自维基百科:
数据科学(英语:data science)是一门利用数据学习知识的学科,其目标是通过从数据中提取出有价值的部分来生产数据产品。
它结合了诸多领域中的理论和技术,包括应用数学、统计、模式识别、机器学习、数据可视化、数据仓库以及高性能计算。
数据科学通过运用各种相关的数据来帮助非专业人士理解问题。
其中有几个要点可以抽取出来:
- 利用数据学习知识,生产数据产品
- 结合统计、机器学习、数据可视化等技术
- 帮助非专业人士理解问题
从中可以看出,“数据科学”是一个非常综合的学科,数据科学家不仅要具备数据相关技术,也要求有产品意识和与非专业人士的沟通能力。
数据科学的相关职位
数据科学是一个综合型学科,以下的职位其实都和数据科学有关:
- 数据分析师
- 机器学习工程师
- 深度学习工程师
- 数据工程师
- 数据科学家
可以看到,除了正牌的“数据科学家”,现在非常火热的“数据分析师”、“机器学习工程师”等,都可以是“数据科学”的职业角色。
数据科学家的工作
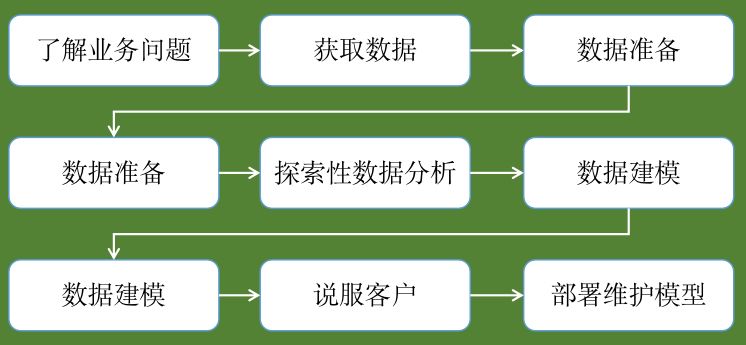
以下会介绍一个“全栈数据科学家”所做的工作,很多数据科学职位很可能只会涉及其中的一部分。
1、了解业务问题
数据科学家工作的第一步,是需要了解业务问题,这一步很重要。
沟通的对象是客户(合作方、你的老板等),客户会提出相关问题,你需要多问很多“为什么”,真正的了解并确定目标。
2、获取数据
这一步需要从各种来源收集数据:
- web server
- 日志
- 数据
- 在线API
- 在线数据仓库
收集正确的数据需要花费不少时间和精力
3、数据准备
这一步指的是对数据做清理和数据转换:
- 检测缺失值、重复值、数据类型不一致问题并修复
- 使用自定义的规则,做数据的转换
最终形成干净正确、结构化的数据。
4、探索性数据分析
Exploratory Data Analysis,简称EDA
这一步会使用数据分析工具做数据探索,发现数据变量之间的关系,挑选出用于优化目标的特征变量。
如果挑选的特征变量有偏差,那么后续构建的模型将不准确,这是非常重要的一步。
5、数据建模
该步骤一般使用Python训练一个预估模型,可以使用KNN/决策树/贝叶斯等传统算法,也可以是DNN/CNN等深度学习算法。
一般来说不会训练一个模型,而是很多个模型同时训练和对比,最终挑选一个最优表现的模型或者融合多个模型。
6、说服客户
这一步对技术人员是很难的,那就是拿着你的数据分析和建模结果去说服你的客户以及“利益相关方”。
使用的方法,就是可视化的展示、良好的沟通口才。
7、部署维护模型
该步骤会将数据获取>数据清理>特征提取>数据建模全链路自动化,部署线上服务,先进行小流量测试,如果指标没问题就全流量推送全部,同时也会附带数据指标后台进行实时的效果观测和预警。
以上就是一个数据科学家工作的流程总结。
薪资
在“拉勾网”搜索“数据科学家”职位:
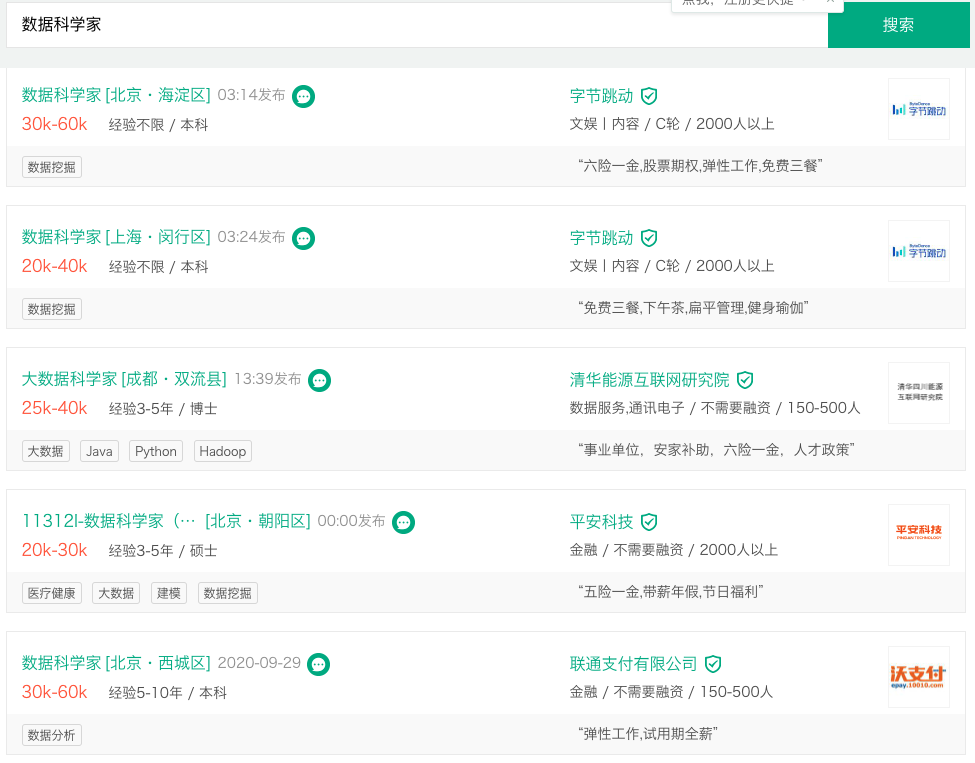
会发现这是一个高薪职位,薪资有一个特点就是波动空间很大,比如字节跳动的第一个职位,30~60K。
这也对应了该学科的特点,那就是能力要求的范围也很大:
- 能力低的也能工作,取数据、查数据、实现分析系统等;
- 能力高的负责一个数据产品,洞察数据宝藏,极大助力公司发展。
后记
近些年有几个职位非常的火:Python工程师、数据分析师、机器学习工程师,如果从本文“数据科学”领域的角度看,他们都是“数据科学”的一个分支,希望本文能带你了解整个数据科学的全部,有一个全局的视野。


















