[root@localhost test]# cat awk
1a 9,100.34
1b 1,999.00
1c 5,656.55
[root@localhost test]# awk '{sub(/1/,"test")}{print "\n",$1,$2}' awk
testa 9,100.34
testb 1,999.00
testc 5,656.55
[root@localhost test]# awk '{gsub(/1/,"test")}{print "\n",$1,$2}' awk
testa 9,test00.34
testb test,999.00
testc 5,656.55
[root@localhost test]# awk '{sub(/[0-9]+/,"")}{print "\n",$1,$2}' awk
a 9,100.34
b 1,999.00
c 5,656.55
打印出$1只包含4个字符的 awk '$1~/^....$/{print $1}' file
http://bbs.linuxtone.org/thread-17620-1-1.html 看到的学习一下记录一下 效果是有了 但时间和我系统时间对不上
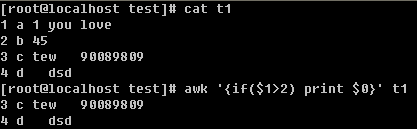
[root@localhost test]# cat awk
1a 9,100.34 dkjfjkdkjf 45 lopo
1b 1,999.00 dgfg 456 ll
1c 5,656.55 fghgf 465 df
[root@localhost test]# awk '{$2=strftime("%F %T",$2);print $1,$2,$3 >"bbb.txt";print $1,$2,$4 >"ccc.txt"}' awk
[root@localhost test]# cat bbb.txt
1a 1969-12-31 16:00:09 dkjfjkdkjf
1b 1969-12-31 16:00:01 dgfg
1c 1969-12-31 16:00:05 fghgf
[root@localhost test]# date
Wed Dec 14 22:49:28 PST 2011
[root@localhost test]# cat ccc.txt
1a 1969-12-31 16:00:09 45
1b 1969-12-31 16:00:01 456
1c 1969-12-31 16:00:05 465
[root@localhost test]# date
Wed Dec 14 23:07:09 PST 2011
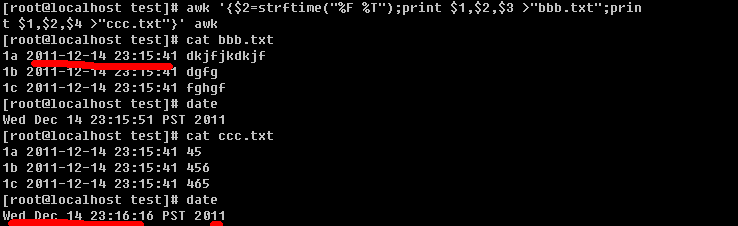
问题已解决 把{$2=strftime("%F %T",$2)中的$2去掉就可得到正确的格式了 见下图
一个文件,列数是不一样的,如果有5列,就取前4列,如果有6列,就取前5列
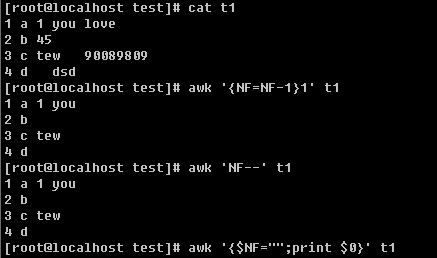
当第一列大于2的时候 打印