
在许多软件工程学科中,生产用例是相当标准化的。以 Web 开发为例:要在 Web 应用中实现身份验证,你无需发明数据库,编写自己的哈希函数,或者设计一个新的身份验证策略。你可以使用某个定义好的方法,并利用标准工具就能在 Web 应用中实现身份验证。
然而,在机器学习中,这种标准化并不存在。为了构建从模型训练到部署的管道,团队不得不构建自己的解决方案,主要的问题是从头开始开始构建解决方案。
这样一来,这一领域对于许多工程师来说成了不可企及的禁区,推而广之,对那些很多请不起专业专家的公司来说也是如此。
但这一情况正在改变。生产模式正变得越来越常规。这些方法正在标准化,工具也正在日益成熟。到最后,软件可以由非专业的机器学习工程师开发了。
将模型投入生产意味着什么?
如果你看看自己每天都使用的软件,如 Gmail、Uber、Netflix 等,无论你喜欢哪种社交媒体平台,都能在里面看到机器学习的身影,比如:自动完成电子邮件、语音转文本、对象检测、预计到达时间等等。

虽然这些模型背后的数学是机器学习研究人员的领域,但用来将它们转化为产品的架构应该是任何开发人员都熟悉的:
从软件工程的角度来看,经过训练的模型只不过是另一个 API,将模型投入生产意味着将其部署为微服务。
注意:还有其他形式的模型部署(例如,未连接到国际互联网的设备),但它们不是本文要讨论的重点。
想要构建类似 Gmail 的智能撰写(Smart Compose)这样的功能吗?将语言模型部署为 Web 服务,用文本 ping 端点,并在前段显示预测。想要实现像 Facebook 建议的标签功能吗?还是同样的过程,部署一个图像识别模型,并像使用其他 Web 服务一样使用它。
虽然“把你的模型部署成微服务”,这句话听起来很容易,但是要如何做到这一点,却是一个很有挑战性的问题。
部署用于实时推理的模型需要回答几个问题:
- 如何编写一个从模型生成预测的 API?
- 将该 API 部署到生产环境的最佳方式是什么?
- 如何实现生产 Web 服务所需要的所有基础设施特性:自动伸缩、监控、负载平衡、滚动更新等?
根据模型的具体情况(如模型所有的框架、需要多少计算和内存、可以处理的数据种类等等),答案可能会有很大的差异。
这就是为什么大型科技公司有专门的机器学习基础设施团队,也是为什么大多数创业公司无法在生产中使用机器学习的原因。
但现在,这些问题有了标准答案。
要从模型中生成预测,可以使用框架附带的任何服务库(如 TensorFlow/TF serving、PyTorch/TorchServe)。要将你的模型封装在 API 中并进行部署,你就需要使用模型服务平台。
现在,任何软件工程师都可以采用一个模型(无论该模型是由他们的数据科学团队训练的模型,还是经过他们调优的开源模型,或者只是一个普通的预训练模型),并将其转换为生产 Web 服务,而不必成为机器学习或 Kubernetes 方面的专家。
示例:文本生成不仅仅是 Gmail 的智能撰写
如果你在过去的几年里使用过 Gmail,那么你一定很熟悉它的智能撰写功能。当你在写电子邮件时,Gmail 会抛出一些建议回复:
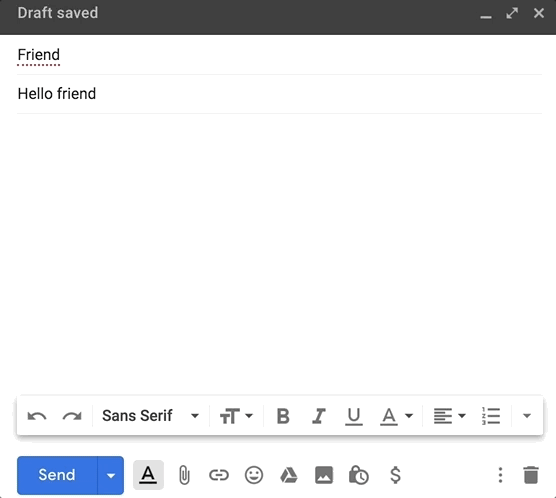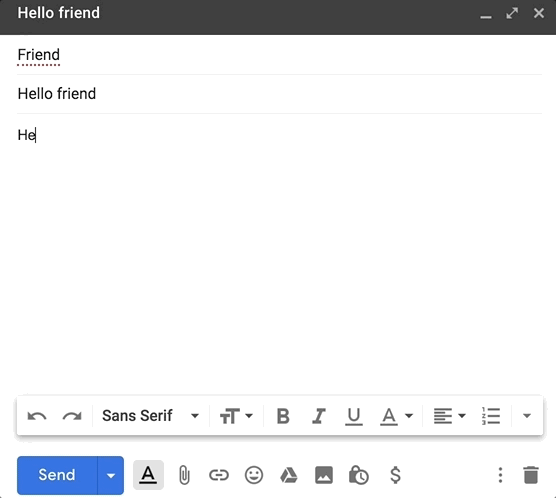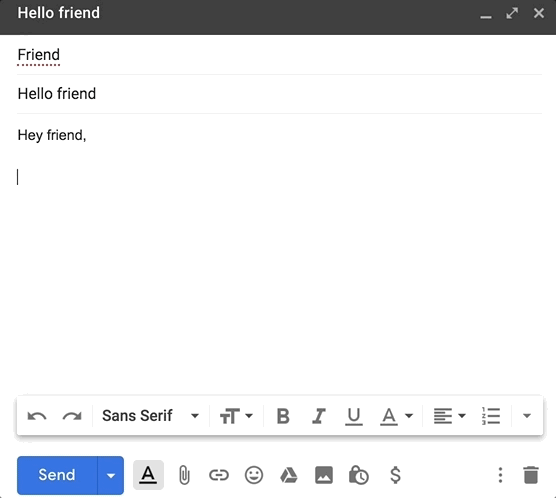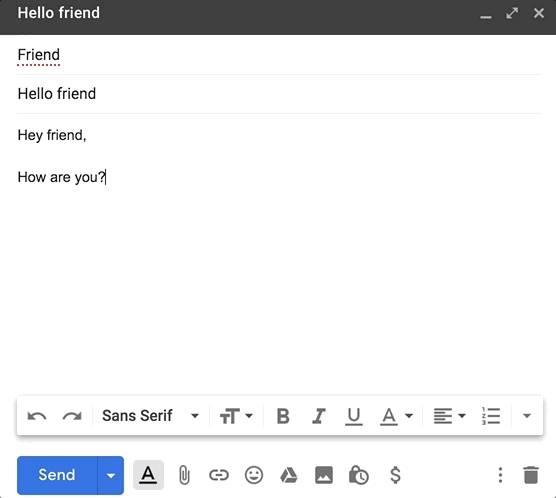
虽然 Google 有一个复杂的机器学习管道,需要大量投资,但如果你想构建一些模仿 Gmail 的智能撰写的功能,不需要 Google 的资源你也能做到这一点。
举个例子:AI Dungeon。这是一款基于机器学习的文字冒险游戏。
从本质上说,AI Dungeon 是 OpenAI 的 GPT-2(一种最先进的语言模型)的微调版本,以 Web 服务的形式部署。用户将他们的提示提交到模型 - 微服务中,它就会用一个故事来回应。
就上下文而言,GPT-2 非常庞大。经过训练的模型超过了 5GB,完全可以利用 GPU 来服务于一个预测。在不久之前,要想知道如何将其作为微服务进行规模化部署,是一个重大的基础设施项目。你需要:
- 将其托管在具有足够空间 / GPU 的实例上,已提供预测服务。
- 配置自动缩放以处理任意数量的并发用户。
- 实现各种成本优化,让你的云账单处于可控状态。
在这些任务中,有许多子问题需要解决。比如,你是否应该根据内存使用情况或对垒中的请求数量进行自动缩放?你是否能够平稳地处理故障转移,从而能够轻松地使用 Spot 实例来节省成本?
译注:Spot 实例,是一种未使用的 EC2 实例,以低于按需价格提供。由于 Spot 实例允许用户以极低的折扣请求未使用的 EC2 实例,这可能会显著降低你的 Amazon EC2 成本。Spot 实例的每小时价格称为 Spot 价格。每个可用区中的每种实例类型的 Spot 实例的价格是由 Amazon EC2 设置的,并根据 Spot 实例的长期供求趋势逐步调整价格。只要容量可用,并且请求的每小时最高价超过 Spot 价格,Spot 实例就会运行。如果能灵活控制应用程序的运行时间并且应用程序可以中断,Spot 实例就是经济实惠之选。例如,Spot 实例非常适合数据分析、批处理作业、后台处理和可选的任务。
正如 AI Dungeon 背后的工程师 Nick Walton 在他的文章《我们如何扩展 AI Dungeon 来支持超过 100 万用户》(How we scaled AI Dungeon 2 to support over 1,000,000 users) 中称,他所要做的就是编写他的预测 API,并允许他的模型服务平台(Cortex)实现基础设施的自动化。
注:如果你不熟悉迁移学习,那么看一看 AI Dungeon 是如何用很少的数据就能获得最先进的结果的故事也是很有趣的。
设计模型有挑战,生产化的过程很枯燥
多年前,机器学习产品的瓶颈问题如果不解决,就不会有 AI Dungeon。但现在,它只是众多机器学习原生创业公司之一。
例如,Glisten 将多个模型组合在一起,生成了一个 API,可以用于从图像中提取产品信息:

尽管公司用 Glisten 来处理每月数以千计的产品,但 Glisten 只是一家只有两个人的初创公司。这只是因为他们不需要基础设施团队而已,所以公司只有两个人就够了。
随着机器学习的生产化的问题得到解决,机器学习研究人员和软件工程师之间的障碍也被打破。研究方面的突破更快地体现为产品方面的功能,因此,我们所有人都会受益。




















