
目录

 View Code
View Code
View Code
View Code
View Code
- 思路
- 详细步骤
- 代码演示
- 多页操作详细
- 代码演示
思路
1.先在空白处右键点击查看网页源代码 2.发现页面上的视频信息在网页中,该网站的视频链接、名称等是直接加载的 3.模拟向梨视频汽车板块网址发送get请求 4.分析返回结果发现视频链接是一个个li标签下的a标签的href值 5.由于同类li只用于存放视频,从这些li标签定位a标签即可 6.补全a标签中的链接,点击,是视频详情页,查询该网页源代码 7.视频详情页中视频不是直接加载的,无需向该网页发送请求 8.通过network找到二次加载的地址,并向其发送get请求,返回错误信息,说明该网站有防爬措施 9.在请求头中添加referer字段说明请求来源 10.向该视频链接发送请求并反序列化 11.拿到的视频链接无法访问 12.分析可知中间有一段被系统时间替换 13.利用视频编号将其替换回来从而获取真实连接 14.向该链接发送请求并将返回的视频保存至本地
详细步骤
1、先分析网页的加载模式,在空白处点击右键查看网页源代码,随便复制某个视频标题在源代码页面按Ctrl+F搜索,能够搜索到,说明这个网站是直接加载的
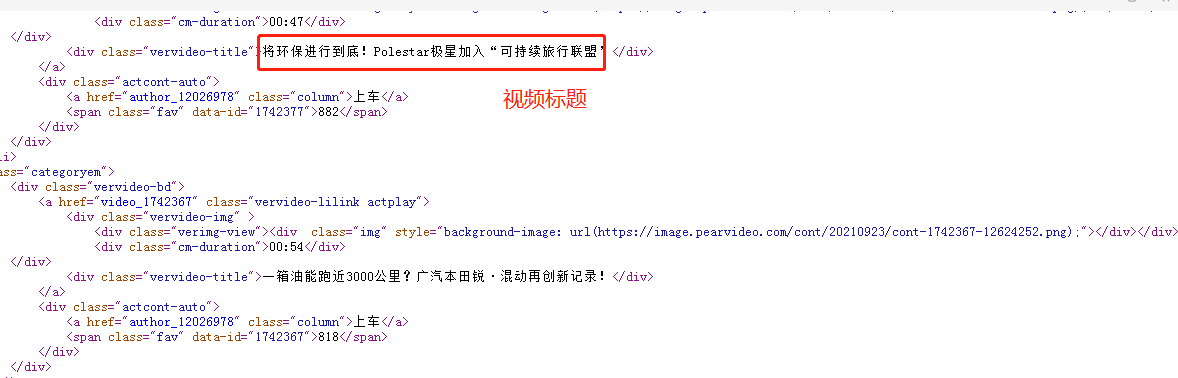
2、回到页面,在空白处右键点击检查,选择Elements栏,再点击最右边的箭头符号,把鼠标移到某个视频,下栏会定位到其所在的标签,寻找规律后发现这些标签都是在一个个<li class="categoryem">标签下
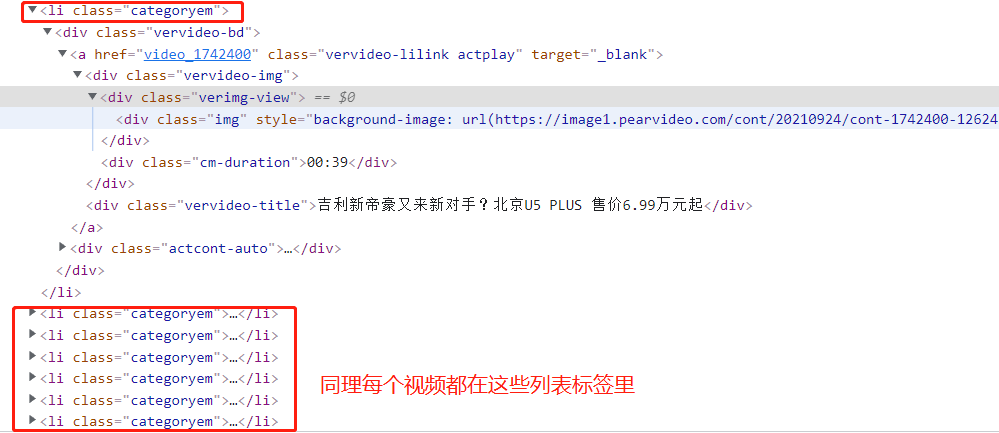
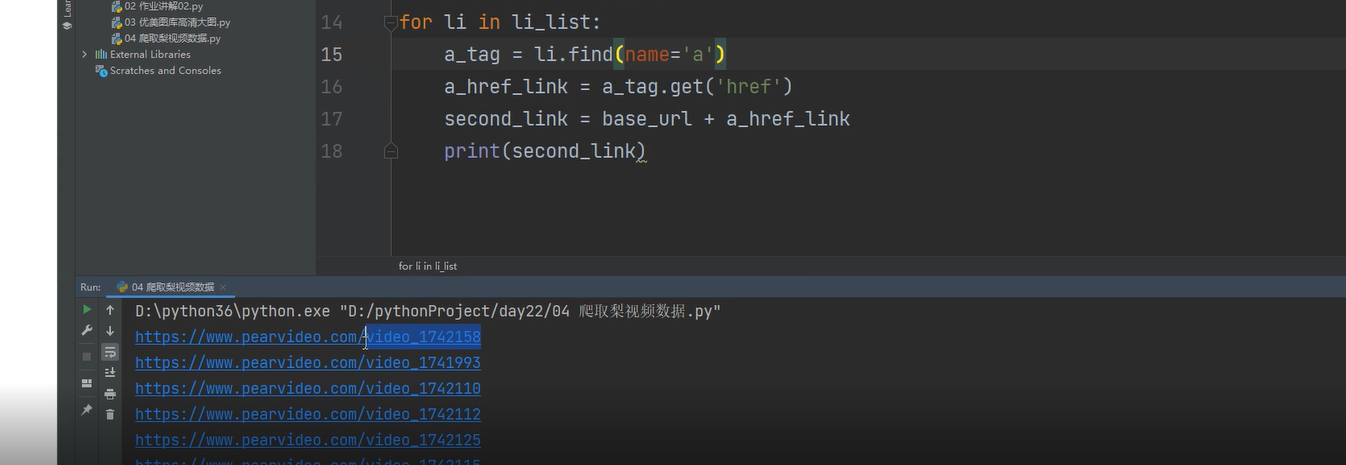
3.在pycharm里循环li标签内的a标签里href的内容,拼接后发现是每个视频的详情页地址
4、在视频详情页上,查看下视频详情页面的加载方式,发现网页源代码中找不到,说明该页面是动态加载的,这样就无需向详情页发送请求了直接向该地址发送即可
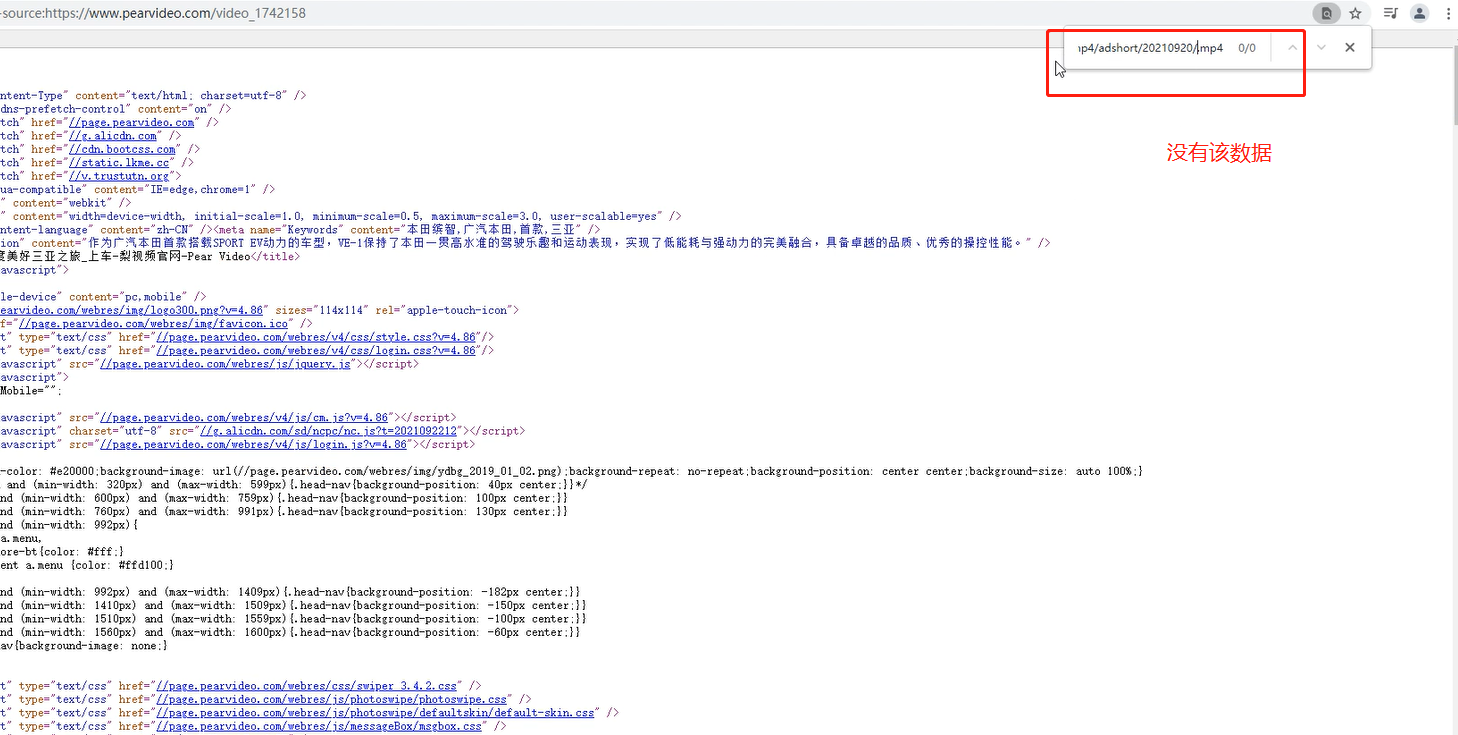
5、通过network查看详情页的请求网址
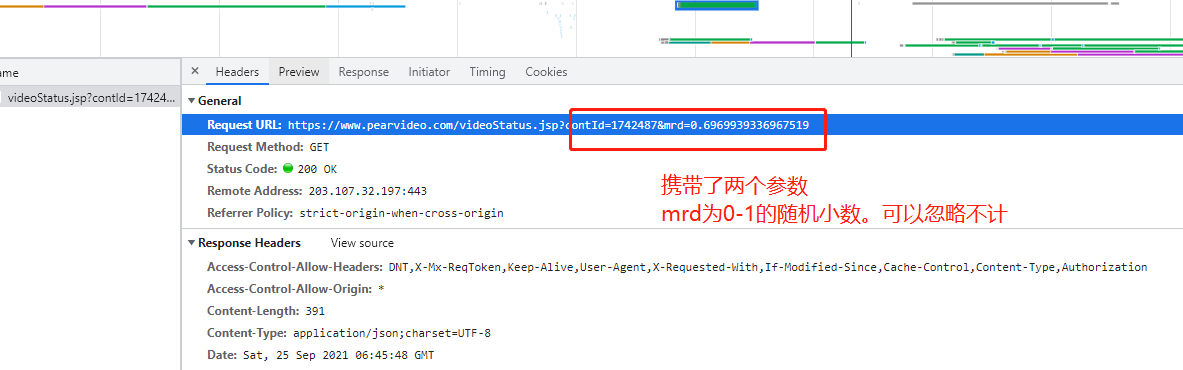
6、朝该详情页发送请求发现获取不到

7、原因是有防爬措施之防盗链,得定义一个请求头加上Refer参数再去请求网站
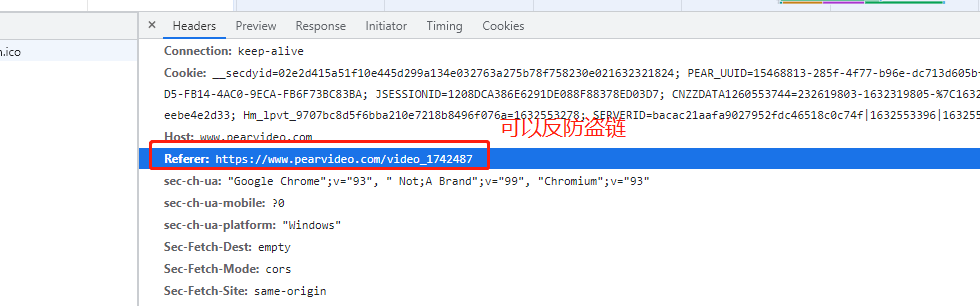
8、在代码中执行下,看看能不能拿到视频真实的链接
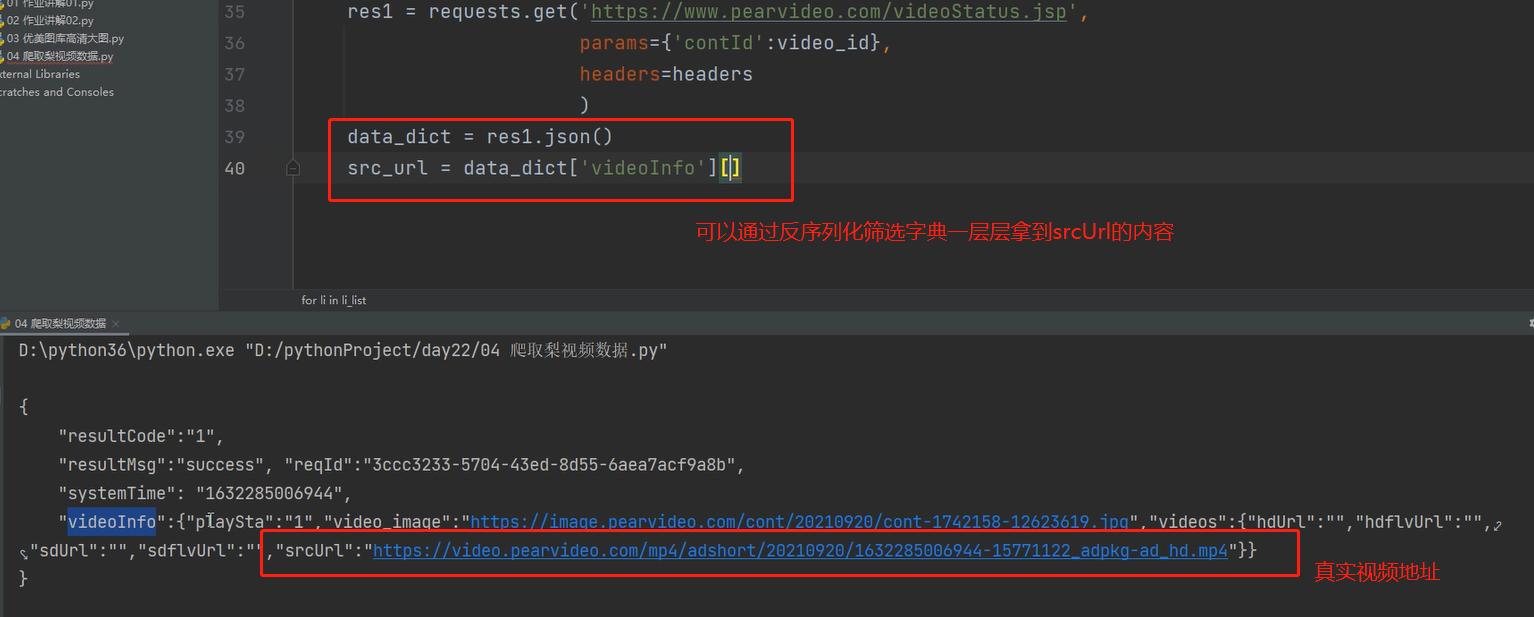
9、去浏览器上复制视频的地址发现与我们拿到的有地方不一样
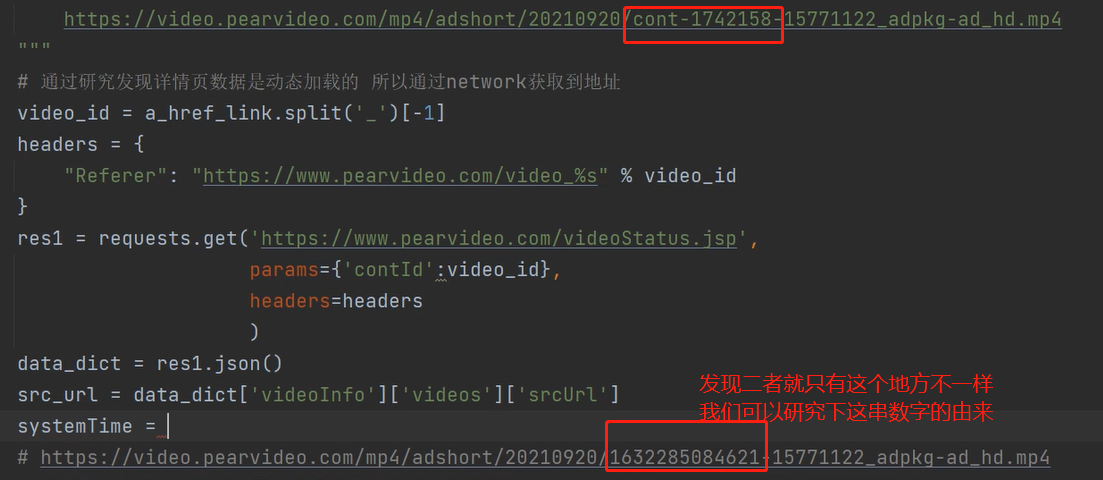
10、接着去想如何去替换核心数据,去拿到真正的视频地址,研究发现通过systemTime即可
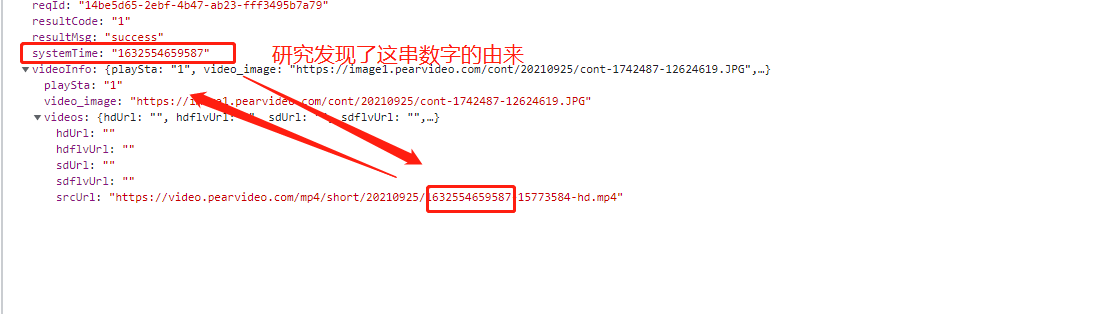
11、在代码里拼接成视频的真实地址

12、利用os模块写入文件并保存单页所有视频数据
a.首先为了避免访问次数过多,需要在循环内加入主动延迟
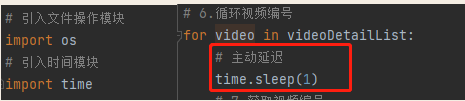
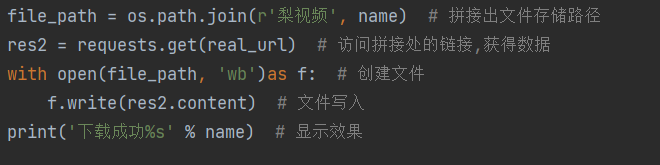
b.接下来创建存放视频的目录

c.拼接文件路径保存数据写入文件
代码演示
import requests from bs4 import BeautifulSoup import os import time if not os.path.exists(r'视频'): os.mkdir(r'视频') # 定义根目录地址 base_url = 'https://www.pearvideo.com/' # 1.发送get请求获取页面数据 res = requests.get('https://www.pearvideo.com/category_31') # 2.使用bs4模块解析 soup = BeautifulSoup(res.text, 'lxml') # 3.研究视频详情链接 li_list = soup.select('li.categoryem') # 4.循环获取每个li里面的a标签 for li in li_list: a_tag = li.find(name='a') a_href_link = a_tag.get('href') # video_1742158 # 通过研究发现详情页数据是动态加载的 所以通过network获取到地址 video_id = a_href_link.split('_')[-1] headers = { "Referer": "https://www.pearvideo.com/video_%s" % video_id } res1 = requests.get('https://www.pearvideo.com/videoStatus.jsp', params={'contId': video_id}, headers=headers ) time.sleep(1) data_dict = res1.json() src_url = data_dict['videoInfo']['videos']['srcUrl'] systemTime = data_dict['systemTime'] real_url = src_url.replace(systemTime, 'cont-%s' % video_id) res2 = requests.get(real_url) file_path = os.path.join('视频', real_url[-12:]) with open(file_path, 'wb')as f: f.write(res2.content) print('%s成功' % file_path)
多页操作详细
1、回到汽车板块的首页,在Network下的Fetch/XHR,将页面滚动条往下拖到底,可以看到浏览器自动发送了个请求

2、再看一下请求的参数,可以看到12个视频id以及页面的起始位置,所以再往下拖滚动条会引起参数的变化

3、进入响应界面查看

4、将代码稍作修改
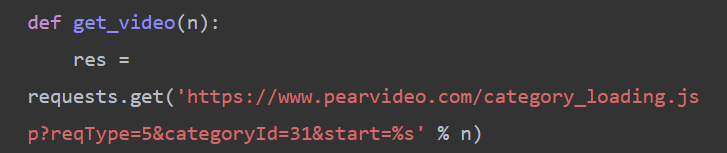
# 在起始位置自定义参数 res=requests.get('https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=31&start=%s' % n)
5、再将整个发送网络请求获取视频数据最后保存的代码段封装成函数以便使用,参数为请求中的起始位置
6、调用此方法即可随意获取页面的视频数据,参数必须是12的倍数
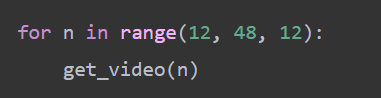
代码演示
梨视频多页数据爬取思路 import requests from bs4 import BeautifulSoup import os import time if not os.path.exists(r'梨视频数据'): os.mkdir(r'梨视频数据') def get_video(n): res = requests.get('https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=31&start=%s' % n) soup = BeautifulSoup(res.text, 'lxml') li_list = soup.select('li.categoryem') # 4.循环获取每个li里面的a标签 for li in li_list: a_tag = li.find(name='a') a_href_link = a_tag.get('href') # video_1742158 video_id = a_href_link.split('_')[-1] # 防盗链 headers = { "Referer": "https://www.pearvideo.com/video_%s" % video_id } res1 = requests.get('https://www.pearvideo.com/videoStatus.jsp', params={'contId': video_id}, headers=headers ) data_dict = res1.json() src_url = data_dict['videoInfo']['videos']['srcUrl'] systemTime = data_dict['systemTime'] real_url = src_url.replace(systemTime, 'cont-%s' % video_id) res2 = requests.get(real_url) file_path = os.path.join(r'梨视频数据', '%s.mp4' % video_id) with open(file_path, 'wb') as f: f.write(res2.content) time.sleep(0.5) for n in range(12, 48, 12): get_video(n)
本文章为转载内容,我们尊重原作者对文章享有的著作权。如有内容错误或侵权问题,欢迎原作者联系我们进行内容更正或删除文章。


















