
本文主要参考沈剑大佬的多篇缓存相关博文和博文的精彩评论,以及数位网友的优秀分享,文末是完整参考,其中第二章节直接节选自沈剑大佬的文章。
1、单体数据库,缓存不一致问题
1.1 Cache Aside Pattern(旁路缓存模式)
- 读:从 cache 中读取数据,读取到就直接返回,读取不到的话,就从 DB 中取数据返回,然后再把数据放到 cache 中。
- 写:更新 DB,然后直接删除 cache 。
1.2 问题一:为什么建议写操作采用淘汰缓存,而不是更新缓存?
如果缓存里存的是序列化后的对象、json或者html数据,需要先get数据,反序列化成对象或者解析成dom树对象,修改其中的成员属性后,重新序列化成文本或者二进制,set 回缓存,修改成本较高。
如果更新缓存,在并发写时,可能出现数据不一致。先更新 db 的写操作1后更新缓存,后更新 db 的写操作 2 先更新缓存,这样缓存里保存的就是写操作1的数据,而 db 里是写操作 2 的数据,导致缓存不一致。
先删除缓存的话再更新 db ,如果 db 更新失败,则缓存中的数据就是错误数据。
1.3 问题二:为什么建议写操作先操作数据库,再操作缓存?
淘汰缓存后数据库还没修改完,但是因为修改操作数据库会加锁,所以无法加载数据到缓存,这个时间段的热点数据容易造成缓存击穿。先操作数据库,再淘汰缓存,时间更短,缓存击穿的概率更小。
2、主从集群架构,缓存不一致问题
2.1 数据库主从,为什么会不一致?
先回顾下,无缓存时,数据库主从不一致问题。db-M 表示主库,db-S 表示从库。
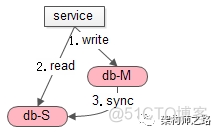
如上图,发生的场景是,写后立刻读:
(1)主库一个写请求(主从没同步完成);
(2)从库接着一个读请求,读到了旧数据;
(3)最后,主从同步完成;
导致的结果是:主动同步完成之前,会读取到旧数据。
可以看到,主从不一致的影响时间很短,在主从同步完成后,就会读到新数据。
2.2 缓存与数据库,什么时候会不一致?
再看,引入缓存后,缓存和数据库不一致问题。
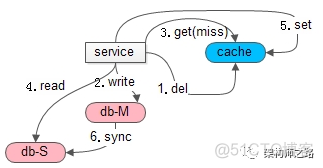
如上图,发生的场景也是,写后立刻读:
(1+2)先一个写请求,淘汰缓存,写数据库;
(3+4+5)接着立刻一个读请求,读缓存,cache 没命中,读从库,写缓存放入数据,以便后续的读能够cache hit(主从同步没有完成,缓存中放入了旧数据);
(6)最后,主从同步完成;
导致的结果是:旧数据放入缓存,即使主从同步完成,后续仍然会从缓存一直读取到旧数据。
可以看到,加入缓存后,导致的不一致影响时间会很长,并且最终也不会达到一致,这就是长期缓存不一致问题。(致命问题)
2.3 为什么会出现这类不一致?
可以看到,这里提到的缓存与数据库数据不一致,根本上是由数据库主从不一致引起的。当主库上发生写操作之后,从库binlog同步的时间间隔内,读请求,可能导致有旧数据入缓存。
2.4 解决方案
2.4.1 方案一:釜底抽薪,解决主从不一致问题
2.4.2 方案二:治标不治本,容忍短期缓存不一致,解决长期缓存不一致问题(双删法)
假如主从不一致没法彻底解决,引入缓存之后,binlog同步时间间隔内,也无法避免读旧数据。那么短期缓存不一致是必定存在的。
但是,有没有办法做到,即使无法解决短期缓存不一致问题,能不能解决长期缓存不一致问题呢?这是更为实际的优化目标。
有,思路为:在从库同步完成之后,再次淘汰缓存中的旧数据。
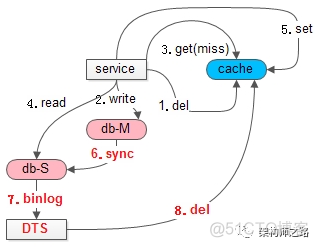
如上图所述,在并发读写导致缓存中读入了脏数据之后:
(6)主从同步;
(7)通过工具订阅从库的binlog,这里能够最准确的知道,从库数据同步完成的时间;
画外音:本图画的订阅工具是DTS,可以是cannal 或者 databus,也可以自己订阅和分析binlog。
(8)从库执行完写操作,向缓存再次发起删除,淘汰这段时间内可能写入缓存的旧数据;这样缓存长期不一致问题就解决了
3、问题
问:单体数据库中,如果先淘汰缓存,再更新数据库,会不会出现在数据更新完成之前,有旧数据被加载到缓存的可能
不会,因为写操作会锁表,所以会阻塞其他读操作,从而避免了旧数据加载缓存。
问:在主从架构里,如果先淘汰缓存,再更新数据库会有什么其他的问题
除了缓存击穿的问题,在主从架构里,如果先操作缓存,在读写并发时,还有会增加缓存不一致的概率。
删完缓存到主库更新完且主库把数据同步到从库的时间范围较长;而先更新 db 再更删除缓存,删除缓存后距离数据同步到从库的时间范围较小;这样在缓存失效后且数据未同步到从库之前,新的读请求访问从库旧数据,并把旧数据写到缓存里的概率就更大,从而加大了缓存不一致的概率。
问:先淘汰缓存,再更新数据库,如果缓存淘汰失败,不更新数据库,满足了原子性,但是会有什么问题
写缓存失败就不再写数据库,虽然保证了原子性,但这种做法对业务的影响太大。
问:先淘汰缓存,再更新数据库,如果数据库更新成功,就一定能保证缓存一致性吗
单体数据库架构可以,更新数据库有锁,阻塞了读,但是主从架构不行,如果更新过程中,缓存加了从库的数据,那么就会导致缓存不一致。通过失效时间或者更新完数据库后再次淘汰缓存来兜底这种情况,。
无论先db还是先cache都不能百分百消除不一致,区别只是两种顺序引入不一致问题的概率大小不一样罢了
问:KV缓存都缓存了一些什么数据?
(1)朴素类型的数据,例如:int
(2)序列化后的对象,例如:User实体,本质是binary
(3)文本数据,例如:json字符串或者html
问:淘汰缓存中的这些数据,修改缓存中的这些数据,最大的差别是什么?
淘汰某个key,下一次该 key 的访问会 cache miss;修改某个key的内容,但下一次该 key 的访问仍可以命中缓存
问:缓存中的 value 数据一般是怎么修改的?
(1)朴素类型的数据,直接 set 修改后的值即可
(2)序列化后的对象:一般需要先 get 数据,反序列化成对象,修改其中的成员,再序列化为 binary,再 set 数据
(3)json或者html数据:一般也需要先get文本,parse成doom树对象,修改相关元素,序列化为文本,再set数据
问:淘汰缓存怎么避免缓存击穿
热点,不应该是1个key,而是一批key,这一批key小概率同时淘汰。
问:Cache Aside Pattern(旁路缓存模式)会有什么问题?如何解决?
如果先操作数据库,再淘汰缓存,在原子性被破坏时:
如果修改数据库成功了,但是淘汰缓存失败了,可能导致,数据库与缓存的数据不一致。设置key的过期时间,通过失效时间来兜底写缓存失败的情况,如果业务上确实无法忍受数据短时间内的不一致,那就不是先写什么再写什么的问题了,应该从业务加技术两个层面来重新设计,比如用同步写来满足一致性。
问:能不能给写操作加上分布式事务,保证数据库更新和缓存淘汰是原子性的,要么都成功,要么都失败
不要把远程操作放在事务里,网络 IO 会极大降低事务的性能。
问:缓存集群的主从切换回丢数据吗,如果会,怎么避免
哨兵模式下数据丢失主要有两种情况:
- 因为主从复制是异步操作,可能主从复制还没成功,主节点宕机了。这时候还没成功复制的数据就会丢失了。
- 脑裂问题导致,如果主节点脱离网络无法与其他从节点连接,但是实际上还在运行。这时候哨兵会将一个从节点切换成新的主节点,但是在这个过程中实际上主节点还在运行,所以继续向这个主节点写入的数据会被丢失。
解决数据丢失方案
增加配置控制同步事件
- min-slaves-to-write 1
- min-slaves-max-lag 10
使用这组命令可以设置至少有一个从节点数据复制延迟不能超过10S,也就是说如果所有从节点数据复制延迟都超过10S,则停止主节点继续接收处理新的请求。这样可以保证数据丢失最多只会丢失10S内的数据。
参考:Redis主从切换
2、发生主从切换时业务上进行限流
4、完整参考
依旧强推沈剑大佬的公众号“架构师之路”




















