
本章内容包含 python 读取 excel表格内容 成 字典组成的列表,之后根据必修课,选修课等信息使用回溯法输出所有可能的课程表,并将所有课程表放入excel中。
系列文章目录
第一章 python模拟登录中国海洋大学教务系统(青果)第二章 爬取学期所有专业课至excel 第三章 课表排课
上一章已经把下学期所有专业课爬到excel里了,现在根据需求分析编写算法进行排课。
文章目录
- 系列文章目录
- 前言
- 一、需求分析
- 二、具体思路
- 1.手动在excel里标记type
- 2.数据结构:python 读取 Excel 形成 list(字典组成的列表)。
- 3.算法:回溯法
- 4.将课程表写入excel
- 三、完整代码及运行结果
- 四、遇到的问题
- 总结
前言
我们学校的所有课程,包括专业课、公共课、通识课,都是自己选的。
因为我转专业太晚了,大四需要修完大三大四的所有课,所以需要一个排课工具,以保证能够选上所有课。(选上的意思是能放在一个课表里,上课时间不冲突)
在网上找不到和我需求差不多的文章,只能自己造一个了,因为数据量也不大,所以就暴力破解吧,回溯就完事了。
ORZ 这个回溯好难,写了三天,本程序只实现了将所有标记为1的课排出课表,基本满足我的需求
一、需求分析
1.能够选上所有必修专业课
2.应该只差一门专业选修了,需要判断选修的类别,在该类别里任选一门,指定学分的课程
3.直接排除其他已修和不必修的课程
二、具体思路
1.手动在excel里标记type
"type":"1", # 0-不修 1-必修 2-选修二 3-可修可不修-0是之前修过的或模块学分已够的选修课
-1是必修课或者你一定想上的课
-2是选修二模块的课
-3是感兴趣的课,排不上也没啥

2.数据结构:python 读取 Excel 形成 list(字典组成的列表)。
问题一:从教务网站扒下来的表格,同一课程的上课时间不在一个表格内。
解决方法一:将 只有上课时间数据的行 合并到上一行中,再通过pandas读取。
import pandas as pd
df = pd.read_excel("排课.xlsx")
print(df)
res = df.to_dict(orient = "records")
print(res)解决方法二:通过按行一个一个读,若是前面都是空格,说明是时间行,直接将该行上课时间添加到上一字典中。
代码如下:
from openpyxl import load_workbook
import pandas as pd
wb = load_workbook('E:/a/排课.xlsx')
table = wb['a']
# 获取总行数总列数
row_num = table.max_row #总行数
col_num = table.max_column #总列数
xlsx_list = []
key = []
excel_data = pd.read_excel("排课.xlsx") #默认读取第一个sheet的内容
key = list(excel_data.columns) # 获取第一行所有值
for i in range(2,row_num-1): # 有多少行,读多少次 i = 2 - 96
xlsx_dict = {}
flag = 0 #0 有效行,1 无效行是标题行或时间行
#按行读,读一个赋一个值
for j in range(1, col_num + 1): #列 j = 1 - 8
if table.cell(i, j).value == '选课号': # 标题行 跳过
flag = 1 #置1,不追加到list里
break
#一进入就判为空的话,说明是时间行,直接将时间追加
if table.cell(i, 1).value == '' or table.cell(i, 1).value == None:
flag = 1
xlsx_list[-1][key[7]] = xlsx_list[-1][key[7]] + " " + table.cell(i, 8).value #该上课时间要添加到上一字典中
break
else:
xlsx_dict[key[j-1]] = table.cell(i, j).value #字典[列名] = 行值
# 把字典添加到列表中
if flag == 0:
xlsx_list.append(xlsx_dict)
print(xlsx_list)效果如图:

问题二:上课时间如何处理
例: ‘上课时间’: ‘1-17周 二(5-6节) 1-17周 五(3-4节)单’
处理方法:
1.初始化kcb_list[周几0-6][节数 1 - 12] = 0 # 0-无课 1-每周有课 21-双周有课 11-单周有课
kcb_list:
[{1: 0, 2: 0, 3: 1, 4: 1, 5: 0, 6: 0, 7: 0, 8: 0, 9: 0, 10: 0, 11: 0, 12: 0},
{1: 1, 2: 1, 3: 1, 4: 1, 5: 1, 6: 1, 7: 0, 8: 0, 9: 0, 10: 0, 11: 0, 12: 0},
{1: 0, 2: 0, 3: 0, 4: 0, 5: 1, 6: 1, 7: 0, 8: 0, 9: 0, 10: 0, 11: 0, 12: 0},
{1: 0, 2: 0, 3: 21, 4: 21, 5: 0, 6: 0, 7: 0, 8: 0, 9: 0, 10: 0, 11: 0, 12: 0},
{1: 0, 2: 0, 3: 0, 4: 0, 5: 1, 6: 1, 7: 0, 8: 0, 9: 0, 10: 0, 11: 0, 12: 0},
{1: 0, 2: 0, 3: 0, 4: 0, 5: 0, 6: 0, 7: 0, 8: 0, 9: 0, 10: 0, 11: 0, 12: 0},
{1: 0, 2: 0, 3: 0, 4: 0, 5: 0, 6: 0, 7: 0, 8: 0, 9: 0, 10: 0, 11: 0, 12: 0}]2.先在‘周 一’ 到 ‘周 日’里找,找到后判断节数,然后根据节数后是否有单双周,进行赋值
3.中间需要进行是否有课判断
代码如下:
weekStr="一二三四五六日"
jieStr=['1-2','3-4','5-6','7-8','9-10','11-12','7-9','10-11','10-12']
def is_ok(kc_dict, kcb_list):
#如果找不到该值,则 find() 方法将返回 -1。
print("is_ok:",kc_dict['课程'])
yuan_list = copy.deepcopy(kcb_list)#还是地址的问题 #深拷贝
for i in range(7): #先在周里找
if not kc_dict['上课时间'].find("周 "+weekStr[i]) == -1: #如果有周几
for j in range(9): #在周几里找节数
if not kc_dict['上课时间'].find("周 "+weekStr[i]+"("+jieStr[j]+"节)") == -1: #找到几节后,赋值占位
danshuang = 1 #kcb_list[周几0-6][节数 1 - 12] = 1 # 0-无课 1-每周有课 21-双周有课 11-单周有课
if not kc_dict['上课时间'].find("周 "+weekStr[i]+"("+jieStr[j]+"节)单") == -1:
danshuang = 11
elif not kc_dict['上课时间'].find("周 "+weekStr[i]+"("+jieStr[j]+"节)双") == -1:
danshuang = 21
if j <= 5:
kcb_list[i][(j+1)*2-1] = kcb_list[i][(j+1)*2-1] + danshuang #赋值占位
kcb_list[i][(j+1)*2] = kcb_list[i][(j+1)*2] + danshuang #赋值占位
elif j == 6:
kcb_list[i][7] = kcb_list[i][7] + danshuang
kcb_list[i][8] = kcb_list[i][8] + danshuang
kcb_list[i][9] = kcb_list[i][9] + danshuang
elif j == 7:
kcb_list[i][10] = kcb_list[i][10] + danshuang
kcb_list[i][11] = kcb_list[i][11] + danshuang
else:
kcb_list[i][10] = kcb_list[i][10] + danshuang
kcb_list[i][11] = kcb_list[i][11] + danshuang
kcb_list[i][12] = kcb_list[i][12] + danshuang
for j in range(1,13):
if kcb_list[i][j] == 2 or kcb_list[i][j] == 12 or kcb_list[i][j] == 22 :#有课,排下一个同名课程,若无同名课程,则排下一个type
print("有课:")
#循环 重新赋值 #取消占位
for i in range(7):
for j in range(1,13):
kcb_list[i][j] = yuan_list[i][j]
return False
#排下一个时间 或下一个课
#print("无课:")
#print("该课插入课程表后,课程表:",kcb_list)
return True3.算法:回溯法
解决一个回溯问题,实际上就是一个决策树的遍历过程。你只需要思考 3 个问题:
1、路径:也就是已经做出的选择。 已选课程
2、选择列表:也就是你当前可以做的选择。 下一个课程的所有情况
3、结束条件:也就是到达决策树底层,无法再做选择的条件。 课程表里包含所有目标课程
本程序需要把 kcb 和 kcb_list 区分开
print("【result】:", kcb) #这个是 排好的课程表里包含的课
【result】: [{'选课号': '02003...'课程': '[080502101213]操作系统', ... '上课时间': '1-17周 一(5-6节) ...)'},
...
{'选课号': ...., 'type': 1, '课程': '[080503101221]计算机网络',...'上课时间': ...}]print("【result】:", kcb_list) #这个是 一周是否有课 记录表
【result】: [{1: 0, 2: 0, 3: 1, 4: 1, 5: 1, 6: 1, 7: 0, 8: 0, 9: 0, 10: 1, 11: 1, 12: 1},
{1: 1, 2: 1, 3: 1, 4: 1, 5: 1, 6: 1, 7: 0, 8: 0, 9: 0, 10: 0, 11: 0, 12: 0},
...
{1: 0, 2: 0, 3: 0, 4: 0, 5: 0, 6: 0, 7: 0, 8: 0, 9: 0, 10: 0, 11: 0, 12: 0}]回溯法代码如下:
def back_tracking(kcb, one_list): #def backtrack(路径, 选择列表):
global count
if len(kcb) == len(Next): # 结束条件:课程表里已排的课程 == 需要排的课程总数
count = count+1
result.append(kcb)
if count <= 20: #打印前20个课程表
print("【result】:", kcb) #这个是 排好的课程表里包含的课
print("【result】:", kcb_list) #这个是 一周是否有课 记录表
print_kcb(kcb,kcb_list) #这个是将以上信息可视化,打印在excel里
return
next_kc = Next[len(kcb)]
print("next_kc",next_kc)
for kc_dict in one_list:
if kc_dict['课程'] == next_kc: #选择列表只有很少的几个下个课程
print("next_kc===",kc_dict['任课教师'],kc_dict['课程'])
if is_ok(kc_dict, kcb_list):
kcb.append(kc_dict)
#print("课程表里的课程",kcb)
#print("课程表",kcb_list)
back_tracking(kcb, one_list)# backtrack(路径, 选择列表)
temp = kcb.pop()
#pop上一门课的时候也要把课程表时间给删了
kcb_list_pop(temp)
print("pop:",temp['课程'])
#print("pop后的课程表:", kcb_list)
if temp['课程'] == Next[0]:
print("有课程冲突,无法排课")4.将课程表写入excel
from openpyxl.styles import PatternFill
Color = ['C0C0C0', 'E3CF57', '87CEEB', 'FF69B4', 'EE82EE', '008B8B', 'FFE4E1', 'FFDAB9','BDB76B','D2B48C'] # 背景色
def print_kcb(kcb,kcb_list):
global count
print(count)
c=1 #颜色,Color[0]是表头颜色
workbook = load_workbook('排课.xlsx')
sheet = workbook['d']
#这一段是打印kcb
#for i in range(7): #周一到周日 0-6
# for j in range(1,13): #第一小节到第十二小节1-12
# if not kcb_list[i][j] == 0: #有课
# sheet.cell(j+1,i+2,kcb_list[i][j]) #写入表格
hang = (count - 1)*13
lie = 0#(count - 1)*8
for i in range(7): #周一到周日 0-6
for j in range(1,13): #第一小节到第十二小节1-12
#第1-14-27行,1-8列
sheet.cell(1 + hang ,i+2 + lie ,weekStr[i]) #表头,写入表格
sheet.cell(1 + hang ,i+2 + lie).fill = PatternFill(fill_type='solid',fgColor=Color[0])
#第一列,第二行-
sheet.cell(j+1 + hang ,1 + lie,j) #表头,写入表格
sheet.cell(j+1 + hang ,1 + lie).fill = PatternFill(fill_type='solid',fgColor=Color[0])
for kc_dict in kcb:
for i in range(7): #先在周里找
if not kc_dict['上课时间'].find("周 "+ weekStr[i]) == -1: #如果有周几
for j in range(9): #在周几里找节数 #找到几节后,赋值占位#写入表格
raw1 = 0
raw2 = 0
raw3 = 0
if not kc_dict['上课时间'].find("周 "+ weekStr[i] +"("+ jieStr[j] +"节)") == -1:
if j <= 5:
raw1 = (j+1)*2-1 #赋值占位
raw2 = (j+1)*2
elif j == 6:
raw1 = 7
raw2 = 8
raw3 = 9
elif j == 7:
raw1 = 10
raw2 = 11
else:
raw1 = 10
raw2 = 11
raw3 = 12
data1 = kc_dict['选课号'] + kc_dict['课程'] + kc_dict['任课教师']
data2 = kc_dict['上课时间']
sheet.cell(raw1+1 + hang ,i+2 + lie ,data1) #写入表格
sheet.cell(raw2+1 + hang ,i+2 + lie ,data2) #写入表格
#填充
sheet.cell(raw1+1 + hang ,i+2 + lie ).fill = PatternFill(fill_type='solid',fgColor=Color[c])
sheet.cell(raw2+1 + hang ,i+2 + lie ).fill = PatternFill(fill_type='solid',fgColor=Color[c])
if not raw3 == 0:
sheet.cell(raw3+1 + hang ,i+2 + lie ,"3节课") #写入表格
sheet.cell(raw3+1 + hang ,i+2 + lie ).fill = PatternFill(fill_type='solid',fgColor=Color[c])
#c=c+1#换下个颜色,这里加的话 是每天每个课一种颜色
c=c+1#换下个颜色,这里是每个课一种颜色
workbook.save('排课.xlsx')三、完整代码及运行结果

完整代码太长了,放在gitee里,运行效果如下:
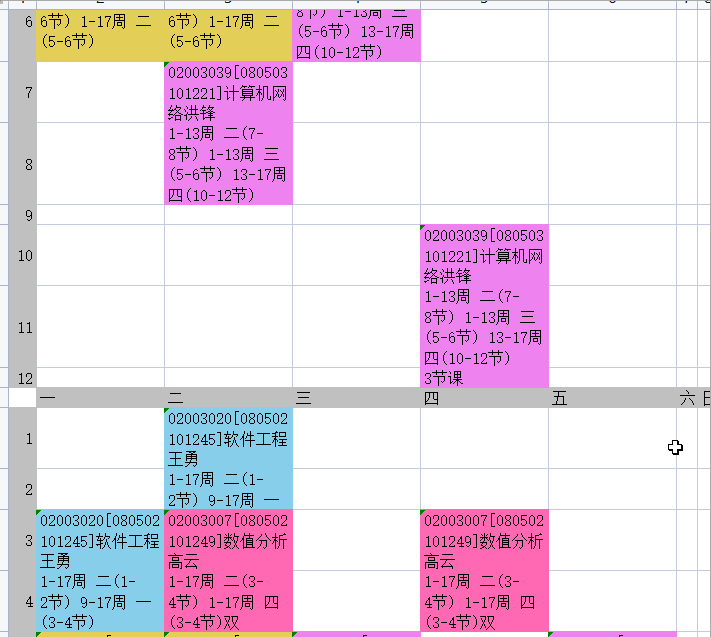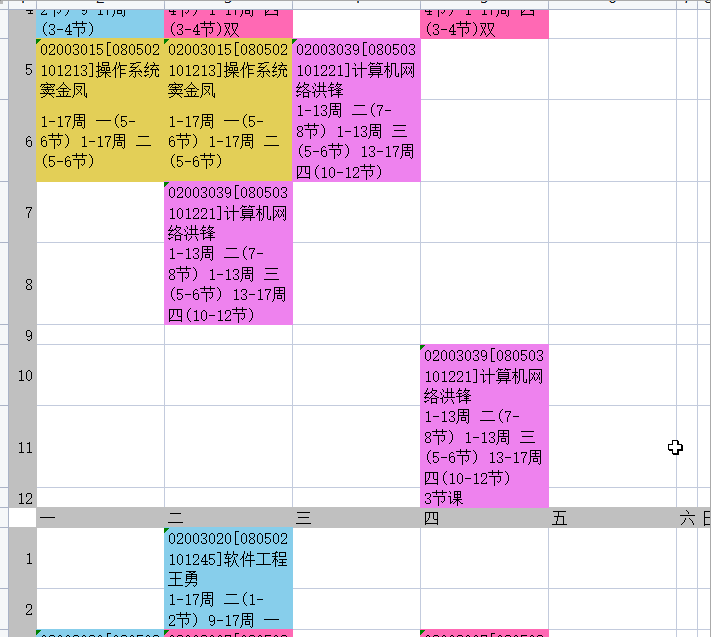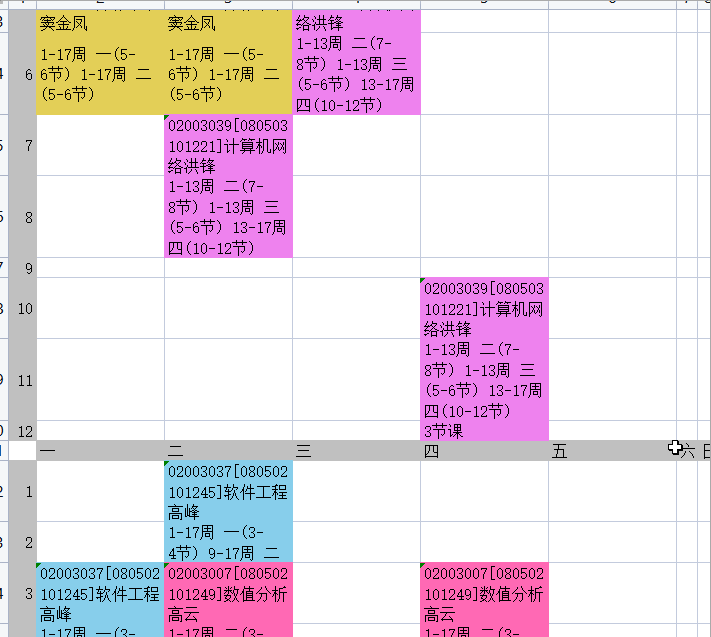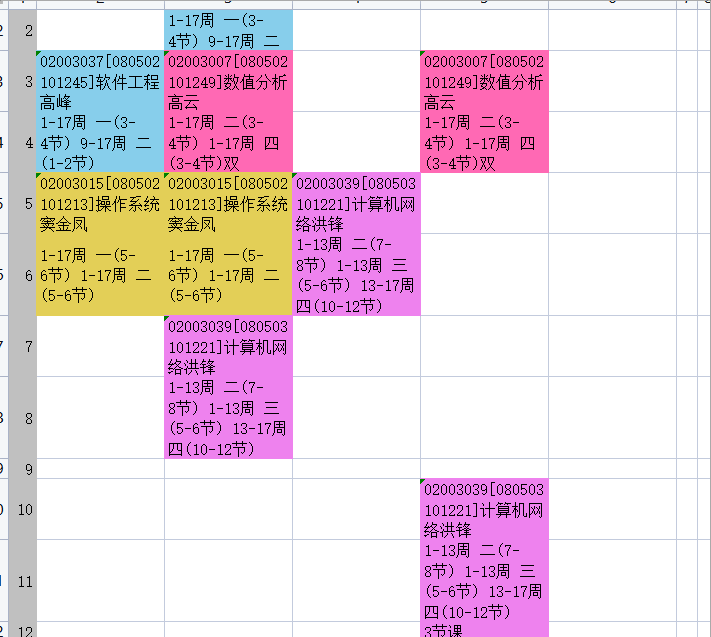
四、遇到的问题
No module named 'pandas'pip install pandas
xlrd.biffh.XLRDError: Excel xlsx file; not supportedxlrd的版本太高
从网上爬的表格 空表格是‘’,但是如果是自己手动新建的列,然后有些输入,有些是空的,则这些空表格是None,在判断的时候是不一样的。
PermissionError: [Errno 13] Permission denied: '排课.xlsx'excel 打开未关闭
总结
1.python列表元素去重:
·list2= list(set(list1))·
去重后保持原来的顺序不变:
·list2.sort(key = list1.index)·
2.如何理解 Python 的赋值逻辑
C 程序更新的是内存单元中存放的值,而 Python 更新的是变量的指向。
C 程序中变量保存了一个值,而 Python 中的变量指向一个值。
如果说 C 程序是通过操纵内存地址而间接操作数据(每个变量固定对应一个内存地址,所以说操纵变量就是操纵内存地址),数据处于被动地位,那么 Python 则是直接操纵数据,数据处于主动地位,变量只是作为一种引用关系而存在,而不再拥有存储功能。
在 Python 中,每一个数据都会占用一个内存空间,如 b + 5 这个新的数据也占用了一个全新的内存空间。
Python 的这种操作让数据成为主体,数据与数据之间直接进行交互。
而数据在 Python 中被称为对象 (Object)。
3.回溯法
【算法】【回溯】回溯算法解题套路框架【转载】
4.excel颜色填充
from openpyxl.styles import PatternFill
cell = sheet['A2']
pattern_fill= PatternFill(fill_type='solid',fgColor='C0C0C0')
cell.fill= pattern_fill


















