
XML DOM 树形结构:
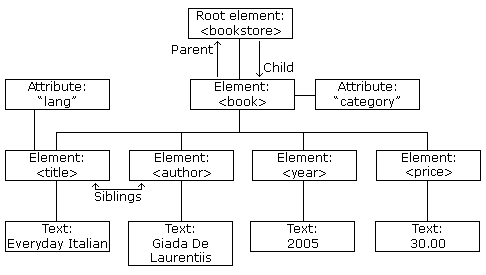
DOM 节点
根据 DOM,XML 文档中的每个成分都是一个节点。
DOM 是这样规定的:
- 整个文档是一个文档节点
- 每个 XML 元素是一个元素节点
- 包含在 XML 元素中的文本是文本节点
- 每一个 XML 属性是一个属性节点
- 注释是注释节点
常用节点类型
| 节点类型 | NodeType | Named Constant | nodeName 的返回值 | nodeValue 的返回值 |
| Element | 1 | ELEMENT_NODE | element name | null |
| Attr | 2 | ATTRIBUTE_NODE | 属性名称 | 属性值 |
| Text | 3 | TEXT_NODE | #text | 节点名称 |
案例:
目标:解析xml文件后,Java程序能够得到xml文件的所有数据
思考:如何在解析之后保留xml的结构信息
xml文档:

实例:
package Test;
/**
* 案例:运用DOM解析xml文件,获得xml文件的所有数据
*/
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class DOMDemo {
public static void main(String[] args) throws Exception {
/** 步骤一:创建一个DocumentBuilderFactory的对象
* 1.定义工厂 API,使应用程序能够从 XML 文档获取生成 DOM 对象树的解析器。
* 2. protected DocumentBuilderFactory()
* 用于阻止实例化的受保护构造方法
* 3. static DocumentBuilderFactory newInstance()
* 获取 DocumentBuilderFactory 的新实例。
*/
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
/** 步骤二:创建一个DocumentBuilder的对象
* 1.protected DocumentBuilder()
* 受保护的构造方法
* 2.使其从 XML 文档获取 DOM 文档实例。使用此类,应用程序员可以从 XML 获取一个 Document。
*/
DocumentBuilder db = dbf.newDocumentBuilder();
/** 步骤三:通过DocumentBuilder对象的parse方法加载book.xml文件到当前目录下
* 1.parse(File f)
* 将给定文件的内容解析为一个 XML 文档,并且返回一个新的 DOM Document 对象。
*/
Document document = db.parse("books.xml");
/** 步骤四:获取所有book节点的集合
* 1.getElementsByTagName():通过节点的名称来获取所有同名节点,
* 因为不只有一个节点,所以就把获取的所有节点都存放在一个节点集合中。
*/
NodeList booklist = document.getElementsByTagName("book");
System.out.println("一共有" + booklist.getLength() + "本书");
/** 步骤五:遍历每一个book节点
* 1.Node item(int index)
* 返回集合中的第 index 个项。
* 2.NamedNodeMap getAttributes()
* 包含此节点的属性的 NamedNodeMap(如果它是 Element);否则为 null。
*/
for(int i = 0; i < booklist.getLength(); i++){
// 前提:不知道book节点的id属性有多少
System.out.println("===========下面开始遍历第" + (i+1) + "本书的内容===========");
// 通过item方法获取一个book节点
Node book = booklist.item(i);
// 获取book节点的所有属性集合
NamedNodeMap attrs = book.getAttributes();
System.out.println("第" + (i+1) + "本书共有" + attrs.getLength() + "个属性");
// 遍历book的属性
for(int j = 0; j < attrs.getLength(); j++){
// 通过item方法获取book节点的某一个属性
Node attr = attrs.item(j);
// 获取属性名
System.out.print("属性名:" + attr.getNodeName());
// 获取属性值
System.out.println("--属性值:" + attr.getNodeValue());
}
/* // 前提:已经知道book节点有且只有一个id属性
// 将book节点进行强制类型转换,转换成Element类型
Element ebook = (Element)booklist.item(i);
// 通过getAttribute("id")方法来获取属性值
String attrValue = ebook.getAttribute("id");
System.out.println("id属性值为:" + attrValue);
*/
/** 步骤六:解析book节点的子节点
* 1.NodeList getChildNodes()
* 包含此节点的所有子节点的 NodeList。
*/
NodeList childNodes = book.getChildNodes();
// 遍历childNodes获取每个节点的节点名和节点值
System.out.println("第" + (i+1) + "本书共有" + childNodes.getLength() + "个子节点");
for(int k = 0; k < childNodes.getLength(); k++){
/* 如果不对节点类型进行判断
* 遍历book节点的子节点后会发现有9个子节点,但是我们只写了4个子节点
* 输出了5个#text节点,这是Text类型的节点。
* 因为空格也属于子节点,所以也会i被遍历出来。
* */
// 区分出text类型的node以及element类型的node
if(childNodes.item(k).getNodeType() == Node.ELEMENT_NODE){
// 获取element类型节点的节点名
System.out.print("第" + (k+1) + "个节点的是" + childNodes.item(k).getNodeName() + ": ");
/* 当我们用childNodes.item(k).getNodeValue()这种方法获取
* element类型的节点的节点值时会返回空,因为他认为
* <name>冰与火之歌</name>中“冰与火之歌”是<name>的子节点,
* 所以返回<name>节点的值当然是null,因为它认为“冰与火之歌”是节点而不是内容。
* 我们这时需要返回<name>节点的第一个子节点,再返回第一个子节点的值就可以了,
* 或者用getTextContent()也可以解决,它会获取所有子节点的节点值
* */
// System.out.println(childNodes.item(k).getFirstChild().getNodeValue());
System.out.println(childNodes.item(k).getTextContent());
}
}
}
}
}
运行结果:
一共有2本书 ===========下面开始遍历第1本书的内容=========== 第1本书共有1个属性 属性名:id--属性值:1 第1本书共有9个子节点 第2个节点的是name: 冰与火之歌 第4个节点的是author: 乔治马丁 第6个节点的是year: 2014 第8个节点的是price: 89 ===========下面开始遍历第2本书的内容=========== 第2本书共有1个属性 属性名:id--属性值:2 第2本书共有9个子节点 第2个节点的是name: 格林童话 第4个节点的是year: 2004 第6个节点的是price: 66 第8个节点的是language: English




















