
1. super的作用
super()函数可以隐式的将子类里的method和父类里的method进行关联,这样就不需要再子类里显式的重新创建父类method里的属性
说人话就是继承父类需要对用到的父类的属性进行初始化,super()帮你处理完了

定义网络结构时的super用于初始化继承的nn.Module中的参数
2. pytorch模型的保存和加载
# 两种保存形式,一种为整个网络加参数,另一种为参数
torch.save(model, path) # 占内存多,慢
troch.save(model.state_dict(), path) # 占内存少,快
# 对应的两种加载方式
model = torch.load(path)
model.load_state_dict(torch.load(path))保存的文件可以是 .pkl 或 .pth
可以自定义要保存的信息,以字典的形式存储,如epoch、batch_size等
checkpoint = {
'model' : Classnet(),
'model_state_dict': model.state_dict(),
'epoch' : epoch,
'optimize_statr_dict' : optimizer.state_dict()
}
torch.save(checkpoint, path)加载的时候分别加载即可
checkpoint = torch.load(path)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']3. 卷积相关
很好的一张gif
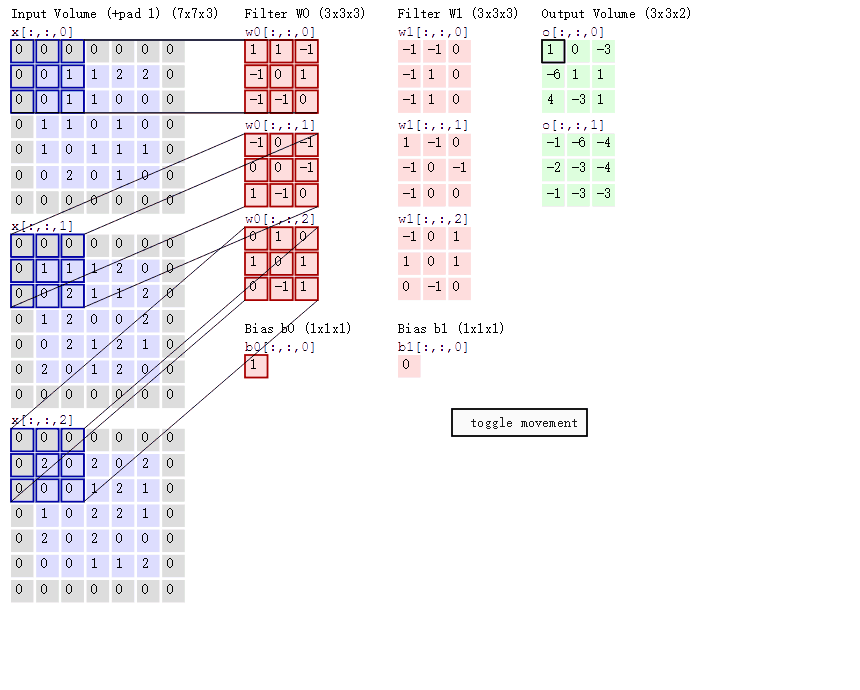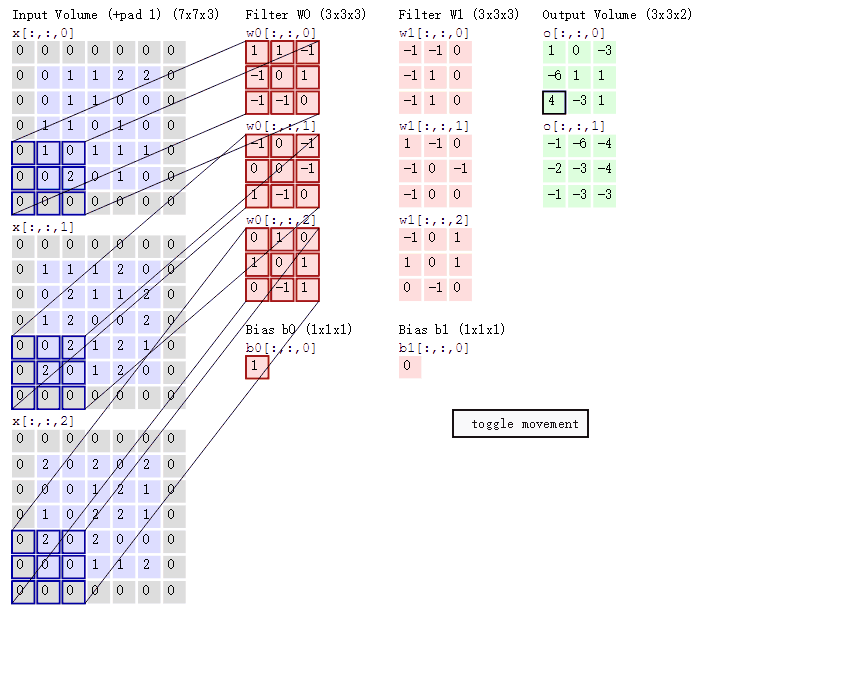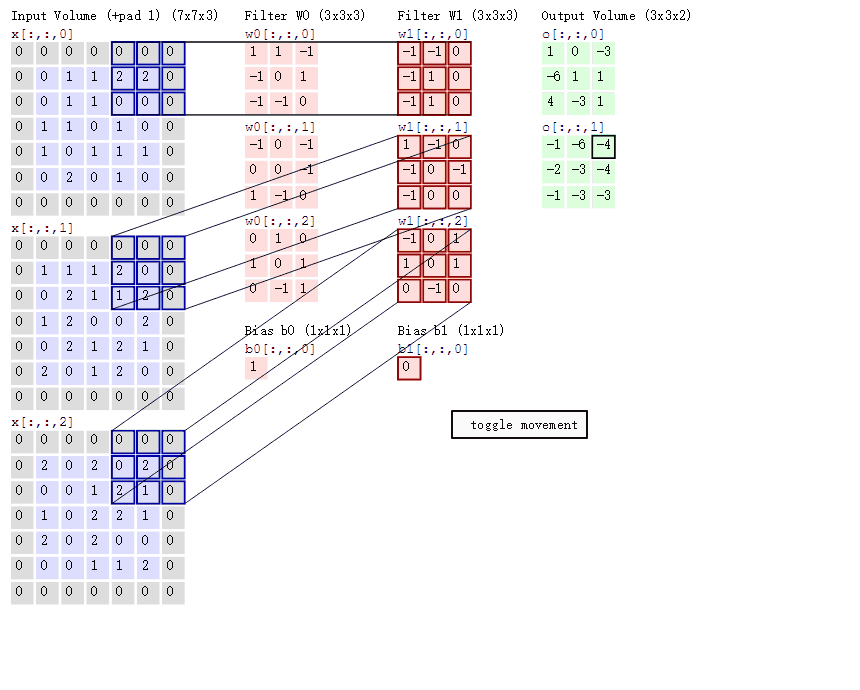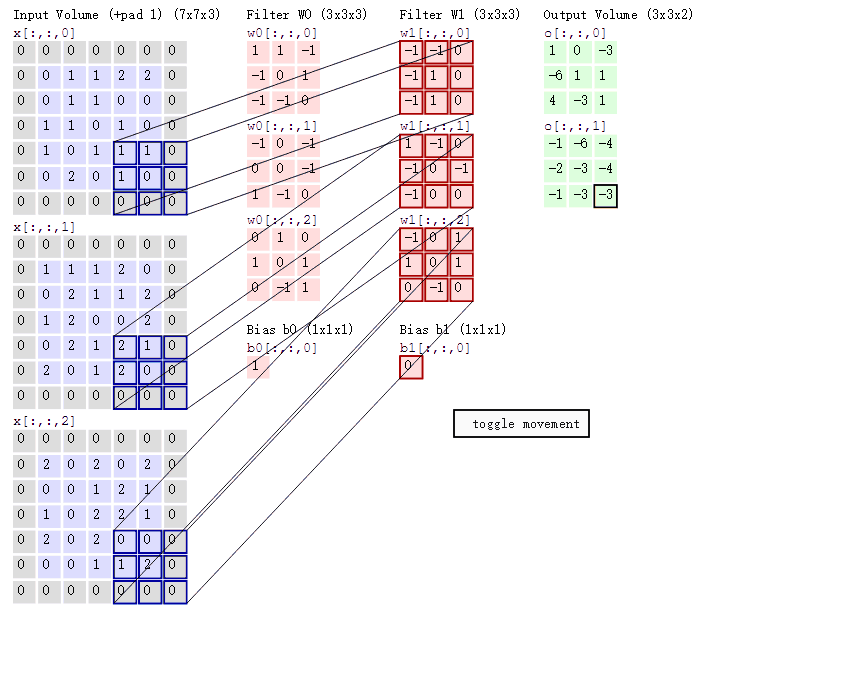
- 每一层卷积的参数量为 in_channel * out_channel * KH * KW
- 卷积核多为奇数,因为奇数的卷积核有中心像素点,且便于padding
- padding时的计算 上下左右各扩充 (n - 1)/ 2
- 卷积后的尺寸为 (M - N + 2*P)/ S + 1
- 卷积神经网络的两大核心思想:
卷积核参数共享 :指的是每一层卷积操作的卷积核对于图像上的每个位置来说共用一个参数

如上图所示,如果不参数共享,回导致参数量极大
网络局部连接 :对于图像信息来说,距离较近的像素相关性较强,较远的相对较弱,所以每个神经元没必要与所有神经元连接,仅与部分神经元相连,称为局部链接
- 平移不变性指的是对于某种特征,无论他在图像上的什么位置,卷积操作提取的特征相同
- 深度可分离卷积:包括深度卷积和点卷积,其中深度卷积就是每一个卷积核对应一个输入通道,in = out,点卷积使用1*1卷积核再改变通道
- 空间可分离卷积:将卷积核拆成两个矩阵相乘的形式,减少参数量,但是不是所用卷积核都能拆分
4. 为什么CNN的输入多数都是正方形
并不强制正方形,因为每一个batch的数据要进行拼接,必须保证batch内的数据尺寸一致,如果图像形状各异,resize会导致失真
5. pytorch默认的初始化方式
卷积层和全连接层权重层采用He-Uniform,bias层采用(-1, 1)均匀分布
Embedding层采用的是(-1, 1)均匀分布初始化策略
6. pytorch卷积层中的参数
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)输入通道、输出通道、卷积核尺寸、步长、padding、空洞卷积(卷积之间的间距)、分组卷积(默认不分组,为1组)、偏置(默认为1)
分组卷积:将要进行卷积操作的特征图进行分组,然后每组分别卷积,可显著减少参数量(分成n组,变为原来的1/n),但是分组卷积需要解决不同组之间特征通信的问题

偏执单元:相当于y = kx + b中的b,是一个可学习的参数,可以提升网络的表达能力,拟合更加复杂的函数
7. DataLoader中的参数
train_loader = DataLoader(dataset, batch_size=batch_size, num_workers = 0,shuffle=shuffle, collate_fn=pad_collate,drop_last=False)数据集、批次数量、每次迭代是否随机打乱、如何处理样本、drop_last的作用是如果最后的batch不满,是否舍去
num_workers:通过影响数据加载速度,来影响训练速度;dataloader加载数据时,一次性创建num_workers个工作进程,并用batch_sampler将指定batch分配给指定worker,worker将他负责的batch加载进RAM
一般将num_workers缓慢增加,直到训练速度不再增加
8. ToTensor 和 from_numpy 和 Tensor
Totensor:将一个PIL格式或numpy.ndarray格式的图像转成tensor,具体操作为将通道由 H x W x C 变为 C x H x W,转成float后再除以255到range [0,1]
from_numpy:将ndarray转化为tensor,二者共用内存,且转化后的tensor不论原格式是什么都为torch.float32,没有改变其他
Tensor:转化为tensor,数据格式也不改变
9. 维度的变换用permute
a是一个tensor,交换其维度 b = a.permute(1,2,0)
10. torch中的拼接
result = torch.cat([tensor1,tensor2],dim=dim)按照指定维度进行拼接
11. torch.nn.Sequential
一个序列容器,用于搭建神经网络的模块,相当于把多个模块封装到一个模块里
12. 过拟合欠拟合
过拟合解决:控制模型的复杂度、数据集增加(扩充、降噪)、L1/L2正则化、dropout
欠拟合解决:提升模型的复杂度表达能力
13. k-means聚类算法
k均值聚类算法,是一种迭代求解的聚类分析算法。
其步骤为,欲将数据分为k组,则在原始数据中随机选取k个作为初始聚类中心,计算其他元素距离K个中心的距离,最近的为那一类。
下次迭代时,将在分好的k组中各自求出均值作为新的聚类中心;
终止条件可以是没有或最小数目的对象被分配给不同的类时,或聚类中心不再变化。
14. BCEloss 和 BCEWithLogitsLoss
在使用BCEloss时,需要做sigmoid处理,BECWITHLogistisLoss将sigmoid和bce结合到一起
15. 熵、KL散度、交叉熵
熵:熵用于描述一个系统的不确定性或一个事件的包含的信息量,熵越大,信息量越大,不确定性越大,其公式如下

越不可能发生的事件信息量越大,独立事件的信息量可以叠加。
如一个事情肯定发生,则其熵为 -log(1) * 1 = 0
KL散度:又叫相对熵,KL散度是衡量两个概率分布之间的差异,但KL散度不具有对称性
对于离散事件

对于连续事件,把求和改成积分

如果P(A) = P(B),即两个事件分布完全相同,那么KL散度为0
对于第一个式子,减号左边其实就是事件A的熵。
KL散度由A自己的熵与B在A上的期望共同决定。当使用KL散度来衡量两个事件,上式的意义就是求A与B之间的对数差在A上的期望值
交叉熵:用于描述两个概率分布之间的相互关系,值越小说明这两个分布越相近,也不具备对称性

根据以上公式可以发现,Dkl(A || B) = H(A,B) - H(A)
如果H(A)是一个常量,则KL散度与交叉熵等价,且二者都非负
KL散度和交叉熵之所以能作为损失函数,是因为用他们来衡量模型的数据分布和训练数据之间的数据分布,而对于训练数据来说,其熵是给定的,即信息量是确定的,所以在训练的时候二者等价,且交叉熵好算,所以用交叉熵
16. 常见的初始化方式
全零或等值初始化:由于初始化的值全部相同,会导致每个神经元学到的东西也相同,出现对称性问题
正态初始化(normal initialization):均值为0,标准差设置一个小值,这样的好处是有相同的偏差,权重有正有负,比较合理
均匀初始化(uniform initialization):均匀分布的区间通常为 [ -1/sqrt(fan_in) , 1/sqrt(fan_in)]
Xaiver Initialization :针对sigmoid激活函数的特性,在初始化权重时考虑网络的输入输出单元数量

xaiver normal : 正态分布的均值为0,方差为sqrt(2/(fin_in + fan_out))
xaiver uniform : 均匀分布的区间为 [ -sqrt( 6/(fan_in + fan_out )) , sqrt( 6/(fan_in + fan_out)) ]
xaiver适合使用tanh、sigmoid为激活函数的网络
He initialization :大神针对relu提出的初始化方法
he normal :正态分布的均值为0、方差为sqrt(2/fan_in)
he uniform:均匀分布的区间为 [ -sqrt(6/fan_in) , sqrt(6/fan_in) ]
Pre-trained : 使用预训练权重作为初始化
17. 深度学习为什么要将数据零均值化
因为如果数据不是0均值的,且没有bn层,那么就会导致每一层结构输出都是大于零的,各层权重都是同号的,梯度下降方向只能在第一或三象限,如果局部极小值相对初始位置在第二或四象限,就会导致梯度下降以zigzag方式靠近极小值,收敛速度慢
18. 评估分类模型的方法
混淆矩阵

精确率accuracy : ( TN + TP ) / ( N + P )
错误率error_rate : ( FP + FN ) / ( N + P )
准确率precision : TP / (TP + FP) TPR FP / ( FP + TN ) FPR
召回率recall : TP / ( TP + FN )
ROC特性曲线:横轴FPR,纵轴TPR,在类别失衡的情况下也不会有不好的表现
AUC : ROC特性曲线下方的面积,表示预测的准确率,越大越好,计算方法为 找出正样本M个,负样本N个,分母 M * N,对于每个正样本与负样本进行比较,概率大记1,等于记.5,小于记0,求和作为分子
在样本比例失衡的情况下,准确率精确率等不能很好的反应模型,需使用AUC
F1score:统计学中用来衡量二分类模型精确度的一种指标,同时兼顾了分类模型的精确率和召回率

通式是

β还可取 2、0.5 等
19. 稠密矩阵
非0元素占比较大的叫稠密矩阵
稠密矩阵计算的代价相关:数值乘法的代价远高于数值加法,故使用乘法来衡量矩阵乘法的代价,对于A(m*n) * B(n*p) 的代价为 mnp
20. 聚类的一些评估指标
纯度 : 用聚类正确样本数除以样本总数
兰德系数 :就是精确率 ( TP + TN ) / ( N + P )
21. 优化器
SGD:梯度下降的方向是随机的,会产生无关方向的震荡
SGDM:引入上一次更新的权值最为动量,加速相关方向的更新,弱化无关方向的震荡
NAG:用上一次的动量,预测本次可能到的位置,来反向更新本次的权值
Adagrad:通过计算对过去梯度进行记录,对学习率进行衰减,前期激励收敛,后期惩罚收敛,缺点是到后面学习率消失
RMSprop:解决学习率消失的问题,用一个窗口,只记录近期的梯度,并加上β和1-β
Adam:引入过去梯度的一阶矩估计和二阶矩估计,来对每一次的学习率进行指导
22. focal loss

相较于交叉熵损失函数,多了两个系数,一个是带γ的(1 - y') 和 y',是为了平衡难易样本,由于简单样本的预测概率一定很高或很低(正或负),所以用1-y'来削弱,同样的对难样本是一种增强
同时,对正例多了一个α,负例多了一个1 - α,是因为focal loss是针对one-stage的目标检测的,这类目标检测会有相当多的负例,故削弱负例的影响
γ取2 α取0.25


















