
一、场景之一:


当我们查看一个页面的数据时,它返回的数据是加密后的效果,可以用selenium解决把程序与浏览器连接,让浏览器帮我们解读这段加密的数据。
二、安装selenium和浏览器驱动
使用selenium要安装selenium模块pip install selenium和浏览器驱动,谷歌浏览器的安装网址:ChromeDriver Mirror
- 浏览器驱动的安装方法:

1.查看自己的谷歌浏览器的版本号。


2. 选择相应的版本下载。

3.把下载解压好的chromedriver,复制到python解释器所在的文件夹里面。
4.我们可以运行下面这段代码,如果程序打开了谷歌浏览器并访问了我们设定的网页,那么我们就安装成功了。
from selenium.webdriver import Chrome
web = Chrome()
web.get("http://www.baidu.com")三、selenium基本操作
1.打开拉钩网,并点击全国这个按钮

打开检查,选定“全国”这个按钮,复制它的xpath路径。

from selenium.webdriver import Chrome
web = Chrome()
web.get("https://www.lagou.com/")
el = web.find_element_by_xpath("/html/body/div[10]/div[1]/div[2]/div[2]/div[1]/div/p[1]/a") #找到元素
el.click() #点击事件
- find_element_by_xpath()和find_elements_by_xpath()的区别是前者只能定位路径中一个元素,后者能定位路径中多个元素。
2.选择搜索框并输入python然后按回车

from selenium.webdriver import Chrome
from selenium.webdriver.common.keys import Keys #导入按键类
web = Chrome()
web.get("https://www.lagou.com/")
el = web.find_element_by_xpath("/html/body/div[10]/div[1]/div[2]/div[2]/div[1]/div/p[1]/a") #找到元素
el.click() #点击事件
web.find_element_by_xpath('/html/body/div[7]/div[1]/div[1]/div[1]/form/input[1]').send_keys("python", Keys.ENTER)#回车3.拿到页面上的职位名和薪水

先定位总表的xpath路径。然后再定位职位名和薪水的xpath路径。
import time
from selenium.webdriver import Chrome
from selenium.webdriver.common.keys import Keys
web = Chrome()
web.get("https://www.lagou.com/")
el = web.find_element_by_xpath("/html/body/div[10]/div[1]/div[2]/div[2]/div[1]/div/p[1]/a") #找到元素
el.click() #点击事件
web.find_element_by_xpath('/html/body/div[7]/div[1]/div[1]/div[1]/form/input[1]').send_keys("python", Keys.ENTER)
time.sleep(1)
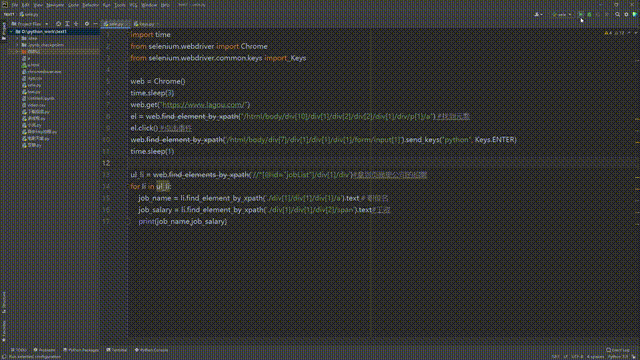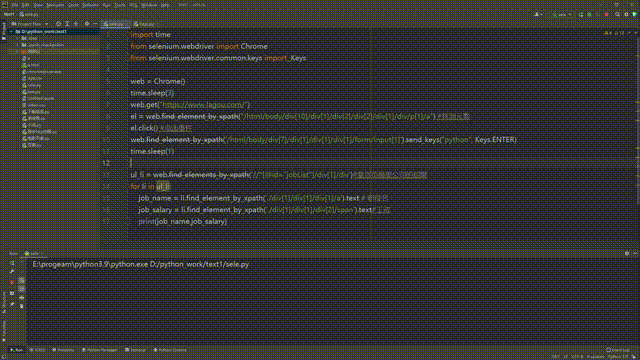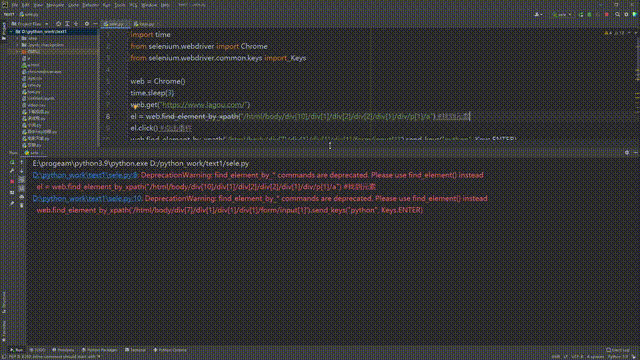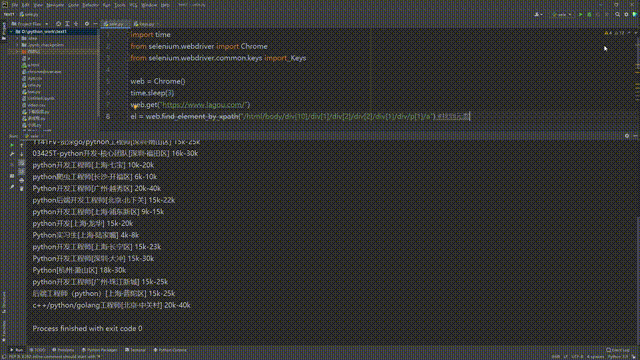
ul_li = web.find_elements_by_xpath('//*[@id="jobList"]/div[1]/div')#拿到页面里公司的招聘
for li in ul_li:
job_name = li.find_element_by_xpath('./div[1]/div[1]/div[1]/a').text # 职位名
job_salary = li.find_element_by_xpath('./div[1]/div[1]/div[2]/span').text#工资
print(job_name,job_salary)

4.seleniun切换浏览器的页面
当我们操作seleniun从第一个页面中打开了一个新的页面,浏览器的窗口会自动跳到新的页面,但是对于selenium来说可操作的范围还是在第一个页面里。那么我们需要输入切换‘视角’的代码:
web.switch_to.window(web.window_handles[-1]) #-1是最后一个窗口的意思,窗口顺序从0开始还有一种写法是切换为原页面:
web.switch_to.default_content()当我们要关闭窗口时写:
web.close()5.对iframe的处理
处理iframe,先拿到iframe然后切换视角到iframe,再然后拿数据。

iframe = web.find_element_by_xpath('//*[@id="player_iframe"]')
web.switch_to.frame(iframe) #把视角切换到iframe
tx = web.find_element_by_xpath('//*[@id = "main"]/h3[1]').text #在iframe里面找东西
print(tx)6.对下拉框选项的处理和配置无头浏览器启动参数(无头就是不显示浏览器)

选择标签有三个函数:
- select_by_index():根据索引进行选择。
- select_by_value():根据value值进行选择。
- select_by_visible_text():根据选项文本进行选择。
下面的代码可以实现,选择选项框里的选项并抓取每次加载的数据:
import time
from selenium.webdriver import Chrome
from selenium.webdriver.support.select import Select
web = Chrome()
web.get("https://www.endata.com.cn/BoxOffice/BO/Global/global.html")
#定位到下拉列表
sel_el = web.find_element_by_xpath('//*[@id="OW_Week"]')
# 对元素进行包装,包装成下拉菜单
sel = Select(sel_el)
for i in range(len(sel.options)): #i就是每个下拉框的索引位置
sel.select_by_index(i) #选择下拉框选项
time.sleep(2)
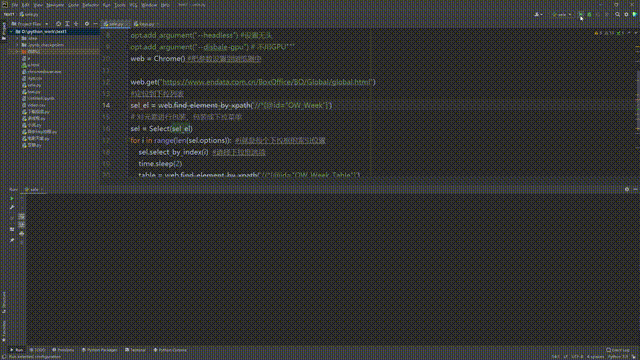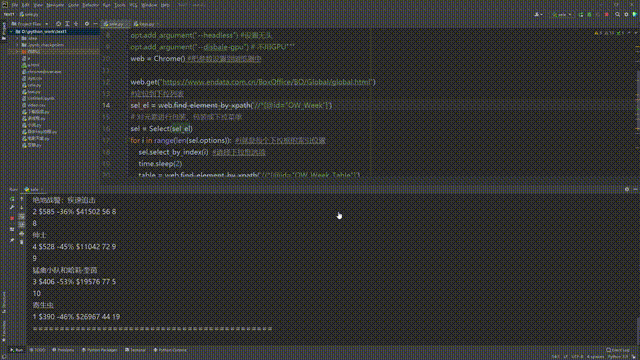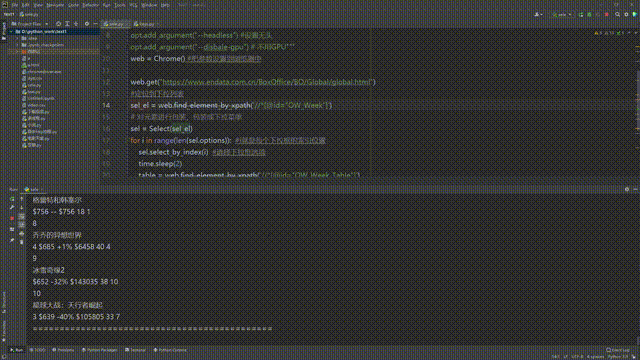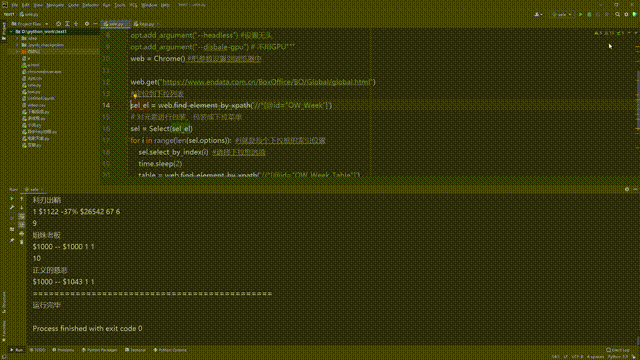
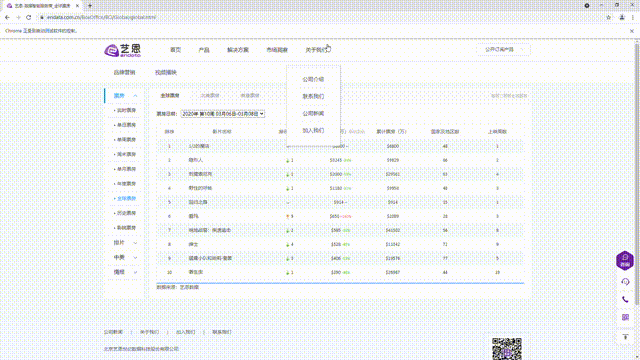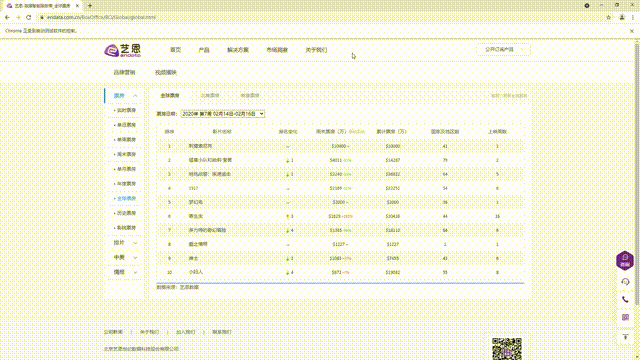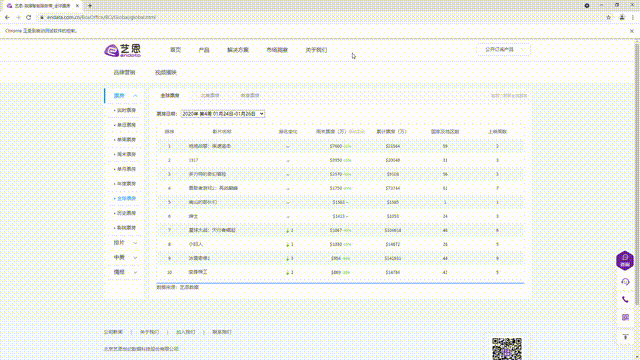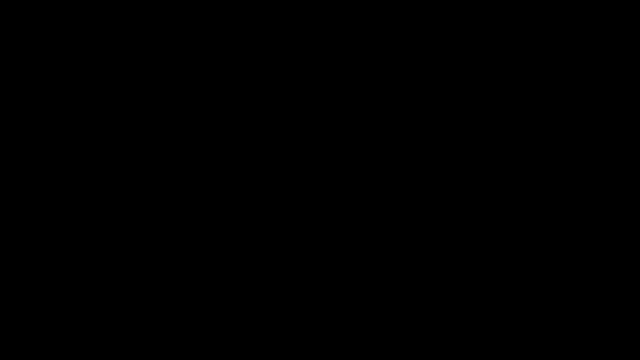
table = web.find_element_by_xpath('//*[@id="OW_Week_Table"]')
print(table.text) #打印所有文本信息
print("=============================================")
print("运行完毕")
web.close()
配置浏览器启动参数:
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
opt = Options()
opt.add_argument("--headless") #设置无头
opt.add_argument("--disbale-gpu") # 不用GPU
web = Chrome(options=opt) #把参数设置到浏览器中7.使用超级鹰🦅处理验证码
先登录超级鹰,然后生成一个软件ID,接着下载Python语言Demo。
把下载好的py文件和测试的验证码图片放到要编译的文件夹里。

打开刚刚复制的py文件按要求填写,运行就🆗了。
本文章为转载内容,我们尊重原作者对文章享有的著作权。如有内容错误或侵权问题,欢迎原作者联系我们进行内容更正或删除文章。


















