
## 一.节点取余
根据redis的键或者ID,再根据节点数量进行取余。
key:value如下
name:1 zhangsna:18:北京
对name:1 进行hash操作,得出来得值是2423423452,用这个值除3,余1则放到1号节点中进行存储,余2则放到2号节点存储。
## 二.一致性hash
一致性哈希分区(Distributed Hash Table) 实现思路是为系统中每个节
点分配一个token, 范围一般在0~232, 这些token构成一个哈希环。 数据读写
执行节点查找操作时, 先根据key计算hash值, 然后顺时针找到第一个大于
等于该哈希值的token节点, 如图10-3所示
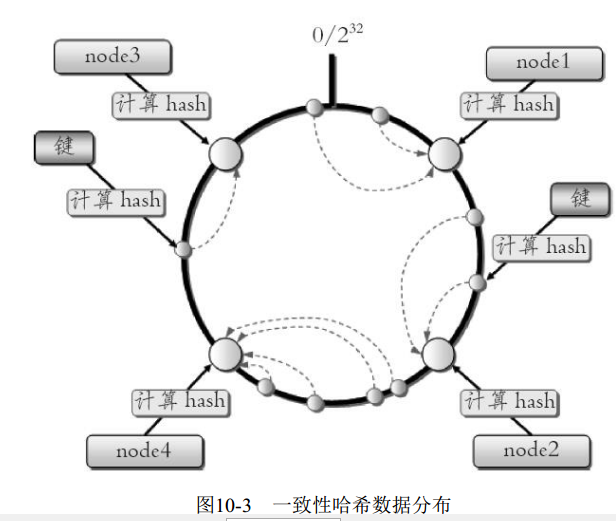
这种方式相比节点取余最大的好处在于加入和删除节点只影响哈希环中
相邻的节点, 对其他节点无影响。 但一致性哈希分区存在几个问题:
·加减节点会造成哈希环中部分数据无法命中, 需要手动处理或者忽略
这部分数据, 因此一致性哈希常用于缓存场景。
当使用少量节点时, 节点变化将大范围影响哈希环中数据映射, 因此
这种方式不适合少量数据节点的分布式方案。
·普通的一致性哈希分区在增减节点时需要增加一倍或减去一半节点才
能保证数据和负载的均衡。
**传统的取模方式**
例如10条数据 0 1 2 3 4 5 6 7 8 9
3个节点node a b c
如果按照取模的方式,那就是
```python
node a: 0,3,6,9
node b: 1,4,7
node c: 2,5,8
```
当增加一个节点的时候,数据分布就变更为
```python
node a:0,4,8
node b:1,5,9
node c: 2,6
node d: 3,7
```
总结:数据3,4,5,6,7,8,9在增加节点的时候,都需要做搬迁,成本太高
而搬迁就是从节点a的机器上把数据移动到节点d上
**一致性哈希方式**
最关键的区别就是,对节点和数据,都做一次哈希运算,然后比较节点和数据的哈希值,数据取和节点最相近的节点做为存放节点。这样就保证当节点增加或者减少的时候,影响的数据最少。
十条数据,算出各自的哈希值,(这里就不变了,实际上要经过一系列计算)
```python
0 : 0
1 : 1
2 : 2
3 : 3
4 : 4
5 : 5
6 : 6
7 : 7
8 : 8
9 : 9
```
有三个节点,算出各自的哈希值
```python
node a: 3
node b: 5
node c: 7
```
这个时候比较两者的哈希值,5等于b,则归属b,4小于b,归属b,3等于a,则归属a,最后所有大于c的,归属于c(这里只是模拟)
相当于整个哈希值就是一个环,对应的映射结果:
```pthon
node a: 0,1,2,3
node b: 4,5
node c: 6,7,8,9
```
这个时候加入node d, 就可以算出node d的哈希值:
node d: 9
这个时候对应的数据就会做迁移:
```python
node a: 0,1,2,3
node b: 4,5
node c: 6,7
node d: 8,9
```
只有最后8,9这2条数据被存储到新的节点,其他不变
## 三.虚拟槽分区
虚拟槽分区巧妙地使用了哈希空间, 使用分散度良好的哈希函数把所有
数据映射到一个固定范围的整数集合中, 整数定义为槽(slot) 。 这个范围
一般远远大于节点数, 比如Redis Cluster槽范围是0~16383。 槽是集群内数据
管理和迁移的基本单位。 采用大范围槽的主要目的是为了方便数据拆分和集
群扩展。 每个节点会负责一定数量的槽, 如图10-4所示。
当前集群有5个节点, 每个节点平均大约负责3276个槽。 由于采用高质
量的哈希算法, 每个槽所映射的数据通常比较均匀, 将数据平均划分到5个
节点进行数据分区。 Redis Cluster就是采用虚拟槽分区, 下面就介绍Redis数
据分区方法。
redis将每个数据放到一个槽中,而很多槽放到节点中。当槽进行扩容,只需要把某些槽迁移到新节点即可。


















