
在数据库应用开发中,我们有时会需要将具有层次的分组数据“扁平化”,按顺序拼为一列,通过不同类型的标识来区别分组和明细,如下所示:
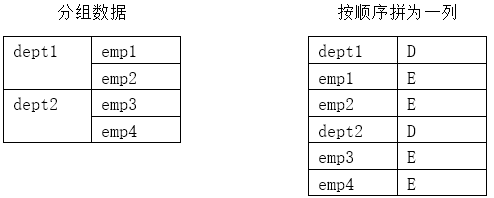
此类需求常见于为报表整理数据,对于SQL来说,属于比较复杂的计算。因为SQL缺少有序集合的机制,需要对分组和明细分别设置用于排序的计算列,再将分组和明细合并,最后做排序。为了实现这种算法,SQL往往要用非ansi标准的特殊函数去实现,代码比较难写,也不易理解。如果需要对层级更多的分组进行拼凑,将更加难以实现。
而借助SPL语言实现此类算法则无需计算列,代码简洁易懂。下面用一个例子来说明。
计算目标:
针对DVDCopy表,将门店及其对应的DVD拷贝拼为一列。
数据结构:
DVD表的前三个字段是:CopyID、DVDID、BID,分别代表DVD拷贝的编号、DVD的编号、门店的编号,其中,DVD拷贝和门店是多对1的关系。部分数据如下:
| CopyID | DVDID | BID | Status | LastDateRented | LastDateReturned | MemberID |
| C000 | D001 | B001 | 7/10/2014 | 7/13/2014 | M001 | |
| C001 | D004 | B001 | 7/10/2014 | 7/13/2014 | M001 | |
| C002 | D001 | B001 | 7/10/2014 | M001 | ||
| C003 | D005 | B001 | 7/10/2014 | 7/13/2014 | M003 | |
| C004 | D006 | B001 | 7/10/2014 | 7/13/2014 | M003 | |
| C005 | D005 | B002 | 7/10/2014 | 7/13/2014 | M003 | |
| C006 | D002 | B002 | 7/10/2014 | 7/13/2014 | M006 |
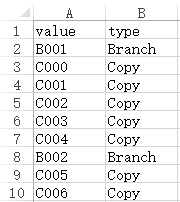
现在需要将DVD编号和门店编号进行汇总,通过类型进行区分,计算结果应该是这样的:
SPL代码:
| A | B | C | |
| 1 | =db.query("select * from DVDCopy order by BID") | ||
| 2 | =create(value,type) | ||
| 3 | for A1 | if A3.BID!=B2 | =A2.insert(0,A3.BID,"Branch") |
| 4 | >B2=A3.BID | =A2.insert(0,A3.COPYID,"Copy") | |
| 5 | >file("DVDCopy.csv").export@ct(A2) |
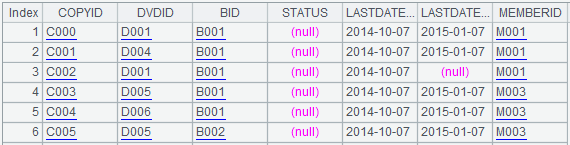
A1:查询表DVDCopy,结果对BID排序,部分结果如下图所示:
A2:=create(value,type)。建立一个空序表A2,有value和type这两个字段。
A3:for A1表示对A1进行循环遍历,每次取A1中的一条记录,在循环体中可以用变量A3来访问当前记录,比如A3.BID。循环语句的作用范围可以直接用单元格缩进来表示,A3的作用范围即B3:C4。
B3:C4:遍历A1中的数据,并向A2追加BID和CopyID。具体算法是:利用网格B2记录当前门店编码BID(初始为空),如果当前记录的BID发生了变化(B3中的代码),则在A2中追加一条门店记录(C3中的代码);修改B2为当前记录的BID(B4中的代码),以便在下一条记录中比较BID是否发生变化;追加一条DVD拷贝记录(C4中的代码)。
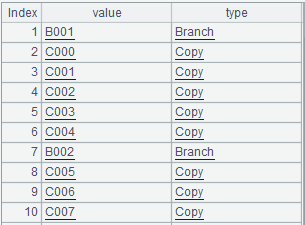
循环遍历后,最终计算结果会存储在A2中,如下图:
延伸:拼合多层分组
前面的案例假设数据只有两层:BID和CopyID,事实上BID、DVDID、CopyID可以组成三层数据。如果需要汇总三类编号,可以依靠类似的办法把三层数据拼成一列,SPL代码如下:
| A | B | C | |
| 1 | =db.query("select * from DVDCopy order by BID,DVDID") | ||
| 2 | =create(value,type) | ||
| 3 | for A1 | if A3.BID!=B2 | =A2.insert(0,A3.BID,"Branch") |
| 4 | >B2=A3.BID | ||
| 5 | if A3.DVDID!=C2 | =A2.insert(0,A3.DVDID,"DVD") | |
| 6 | >C2=A3.DVDID | =A2.insert(0,A3.COPYID,"Copy") | |
| 7 | >file("DVDCopy.csv").export@ct(A2) |
计算结果如下所示:
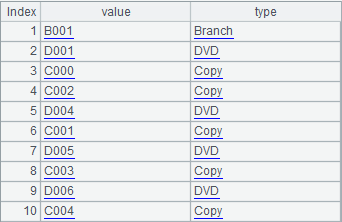
对于计算结果,除了导出数据,SPL还可以直接以被调用的方式向报表工具或java程序提供数据,调用方法和普通数据库相似,使用它提供的JDBC接口即可向java主程序返回ResultSet形式的计算结果,具体方法可参考相关文档。【Java如何调用SPL脚本】




















