
一、概述
1.1 配置
系统:win11
excel:office2019
1.2 PQ个人看法
Power Query 简称PQ
Power Pivot 简称PP
可以做到读取数据并合并、清理格式、行操作、列操作者、行列操作、透视逆透视、数字计算等;
优于Excel函数,但是清理格式、行操作、列操作、行列操作等有SQL可以完成;
透视逆透视、数字计算等有PP可以实现;
独特的优势读取数据并合并;还有可以实现SQL或者PP难以实现的极端情况;
定位:PP的准备工作,连接数据库与PP的桥梁;无数据库或者数据简单的不二选择,数据复杂用Python;
1.3 知识导图

二、重要函数
PQ是 M函数 ,区分大小写,不建议花大量时间学习。了解即可。
2.1 Excel.Workbook

2.2 Text.Combine

2.3 try

三、读取数据
PQ智能读取表格,不能读取区域
3.1 汇总同一文件夹的数据
3.1.1 原始文件路径
文件夹路径:E:\PowerBI学习\素材
Excel工作簿:1001组.xlsx;1002组.xlsx
要求:所有工作表的表头、格式完全一致
具体入下图

3.1.2 PQ操作
步骤解释:
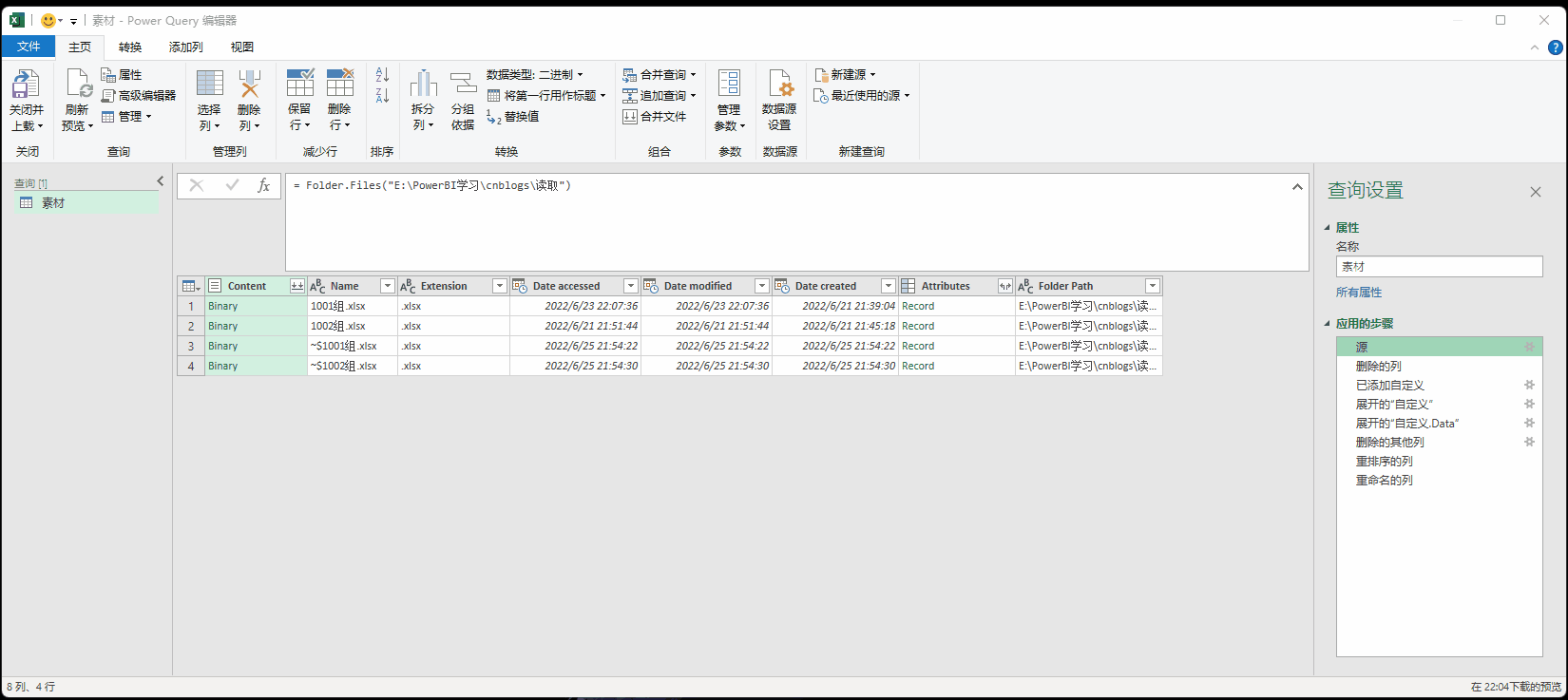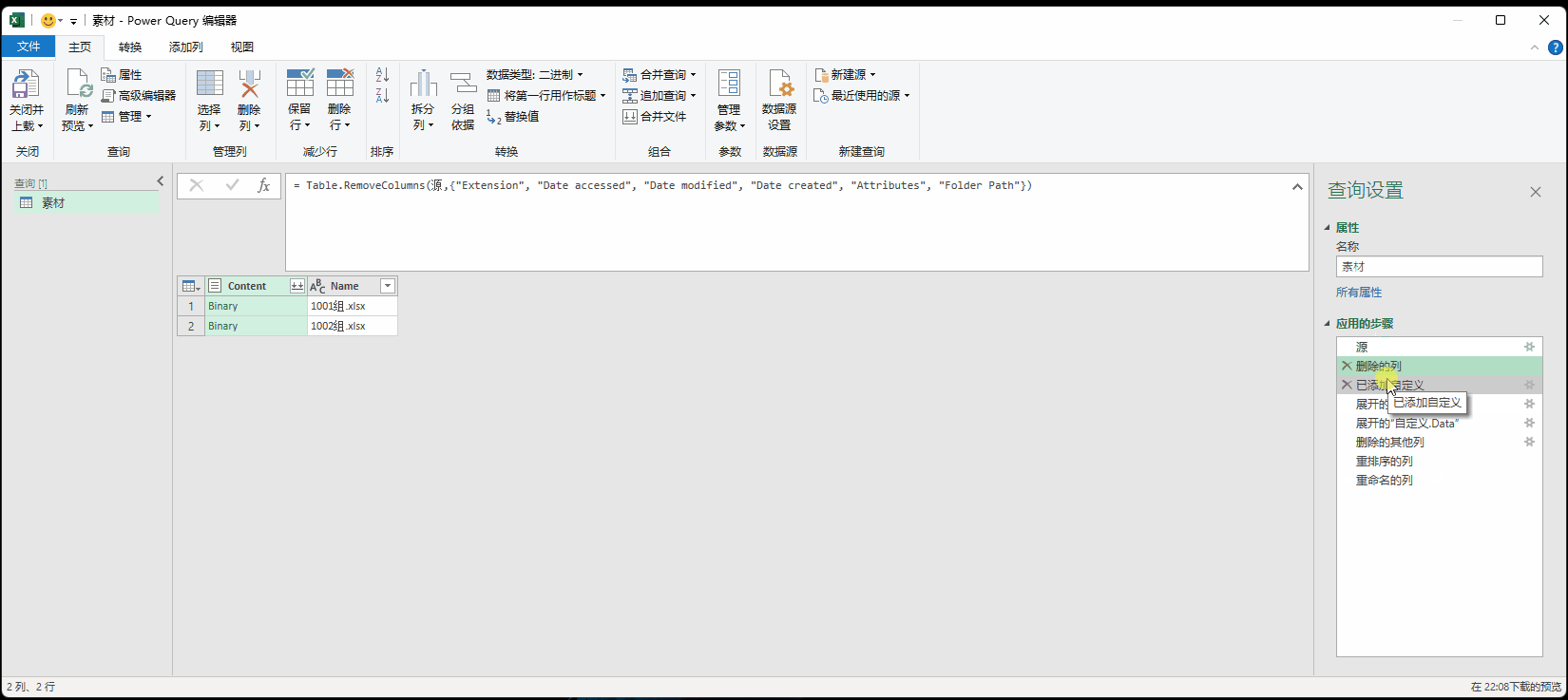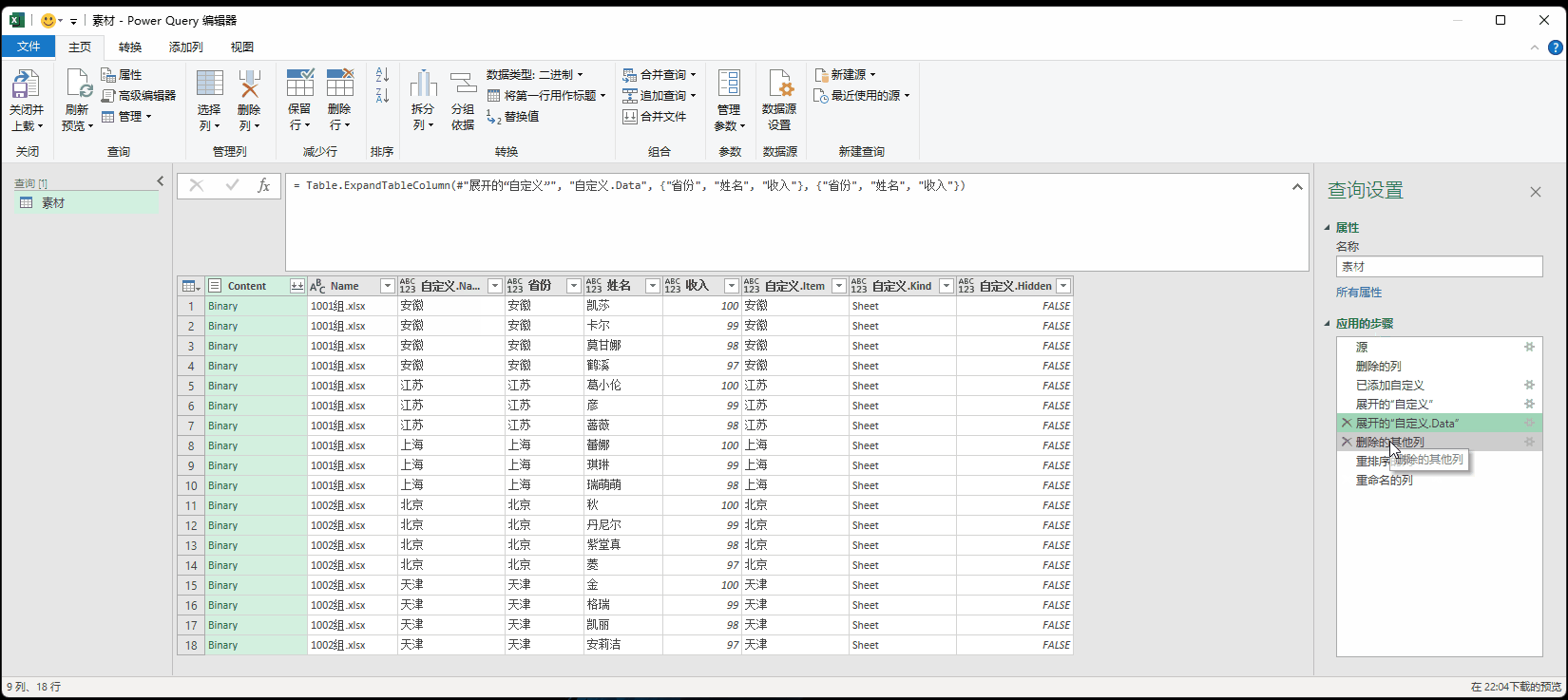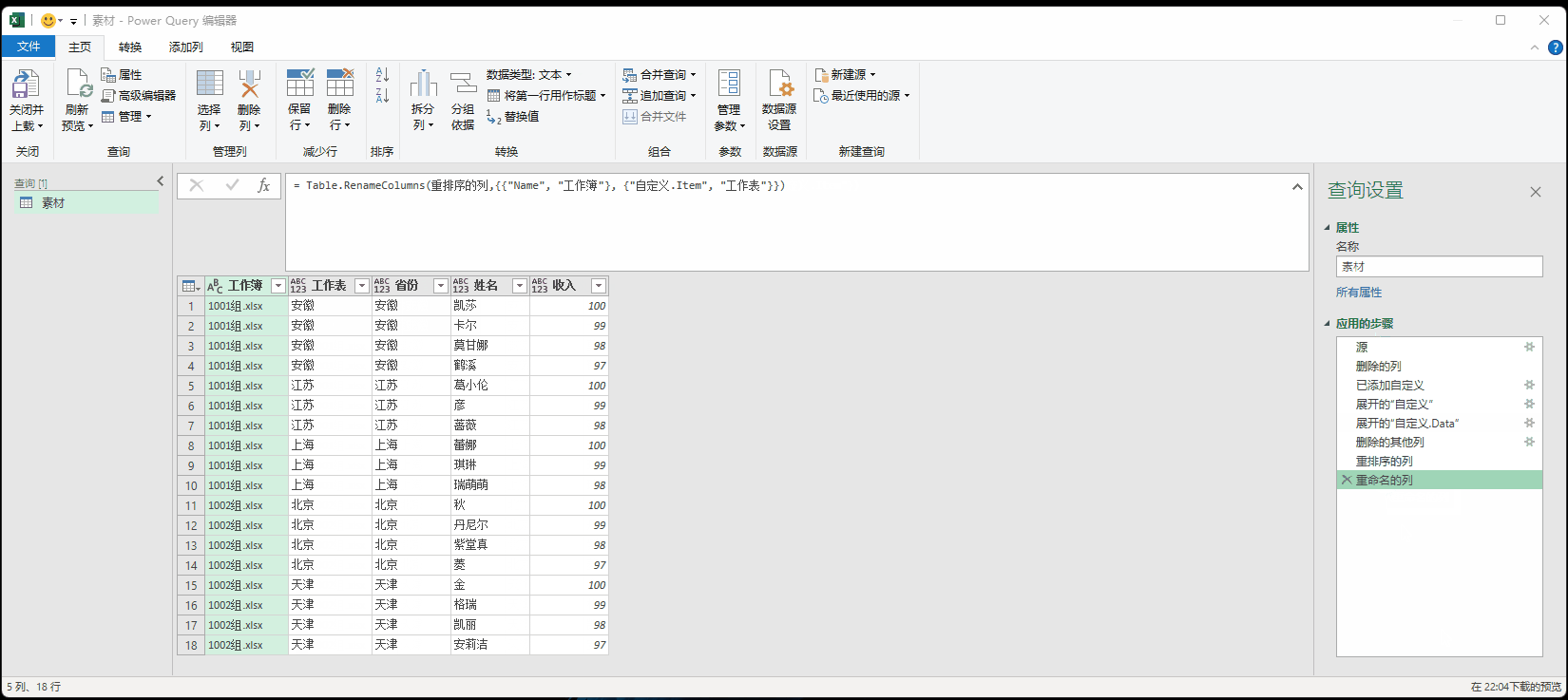
1. 源:= Folder.Files("E:\PowerBI学习\cnblogs\读取")
获取文件夹下得所有工作表
2. 删除的列:= Table.RemoveColumns(源,{"Extension", "Date accessed", "Date modified", "Date created", "Attributes", "Folder Path
非必要操作,个人行为,列太多看着难受
3. 已添加自定义:= Table.AddColumn(删除的列, "自定义", each Excel.Workbook([Content],true))
核心操作,这一步必须自己写;无法通过点击而完成;其他步骤都可以通过点击完成。核心是 Excel.Workbook([Content],true)。

4. 展开的“自定义”:= Table.ExpandTableColumn(已添加自定义, "自定义", {"Name", "Data", "Item", "Kind", "Hidden"}, {"自定义.Name", "自定义.Data", "自定义.Item", "自定义.Kind", "自定义.Hidden"})
将新增的列[自定义]展开:也就是读取工作簿中的工作表
5. 展开的“自定义.Data”:= Table.ExpandTableColumn(#"展开的“自定义”", "自定义.Data", {"省份", "姓名", "收入"}, {"自定义.Data.省份", "自定义.Data.姓名", "自定义.Data.收入"})
读取工作表中的内容
6. 删除的其他列:= Table.SelectColumns(#"展开的“自定义.Data”",{"Name", "省份", "姓名", "收入", "自定义.Item"})
选取需要列
7.重排序的列:= Table.ReorderColumns(删除的其他列,{"Name", "自定义.Item", "省份", "姓名", "收入"})
个人习惯
8.重命名的列= Table.RenameColumns(重排序的列,{{"Name", "工作簿"}, {"自定义.Item", "工作表"}})
个人习惯
3.2 复制
没什么大用,将查询复制一份
3.3 注意csv文件
主要是注意编码:如果出现乱码;选择encoding=936
另外csv的Content是可以直接展开的;无需新增列。
office2019好像可以智能识别编码;
友情提示:在Python、Navicat读取csv和同样要注意编码

四、清理格式
4.1 修改数据类型
极其重要的一个操作,主要是PP无法像SQL可以隐形对数据进行转换,如果是文本格式,则无法对其进行数学运算

4.2 检测数据类型
对数据类型进行检测并更改;建议还是使用修改数据类型,毕竟工作量不大
4.3 格式
选中要做的步骤,上面有解释;不多解释

4.4 替换
类似于replace

4.5 填充
如果本行缺失数据,向下填充,则下面的空值会以上面的数据填充,例如下图中的null值会填充为"江苏";向上填充同理

五、行操作
5.1 将第一行用作标题
有时PQ无法识别行,或者其他行才是标题,需要将其他行调整到第一行,在将第一行用作标题。

5.2 删除行

5.3 保留行
5.4 筛选

5.5 排序

5.6 反转行
将行的顺序颠倒,最后一行变为第一行。

六、列操作
6.1 删除列

6.2 选择列

6.3 移动列
调整列的位置上,选中列移动即可
6.4 条件列

6.5 索引列
如果担心排序之后原来的顺序忘记了,可以提前建一个索引列;索引列的顺序即为原始数据

6.6 重复列
将某列进行复制
6.7 示例中的列
PQ根据某种规则智能提取数据;只对文本和日期格式有效

6.8 自定义列
辅助列的终极大招,对函数要求比较高;

6.9 拆分列

6.10 提取
可以通过先分列在删除非目标列来实现。

6.11 合并列
将两列合并为一列,拆分列的逆操作

6.12 重命名列
对列进行重命名

七、行列操作
7.1 追加查询
在现有表的下方填写新的行数据,相同字段的内容进行合并;如果字段不一样,则会新增字段。

7.2 合并查询
类似SQL中的JOIN;Excel中的VLOOKUP
- 左外部(第一个中的所有行,第二个中的匹配行):ABCDE
- 右外部(第二个中的所有行,第一个中的匹配行):DEFG
- 完全外部(两者中的所有行):ABCDEFG
- 内部(仅限匹配行):DE
- 左反(仅限第一个中的行):ABC
- 右反(仅限第二个中的行):FG

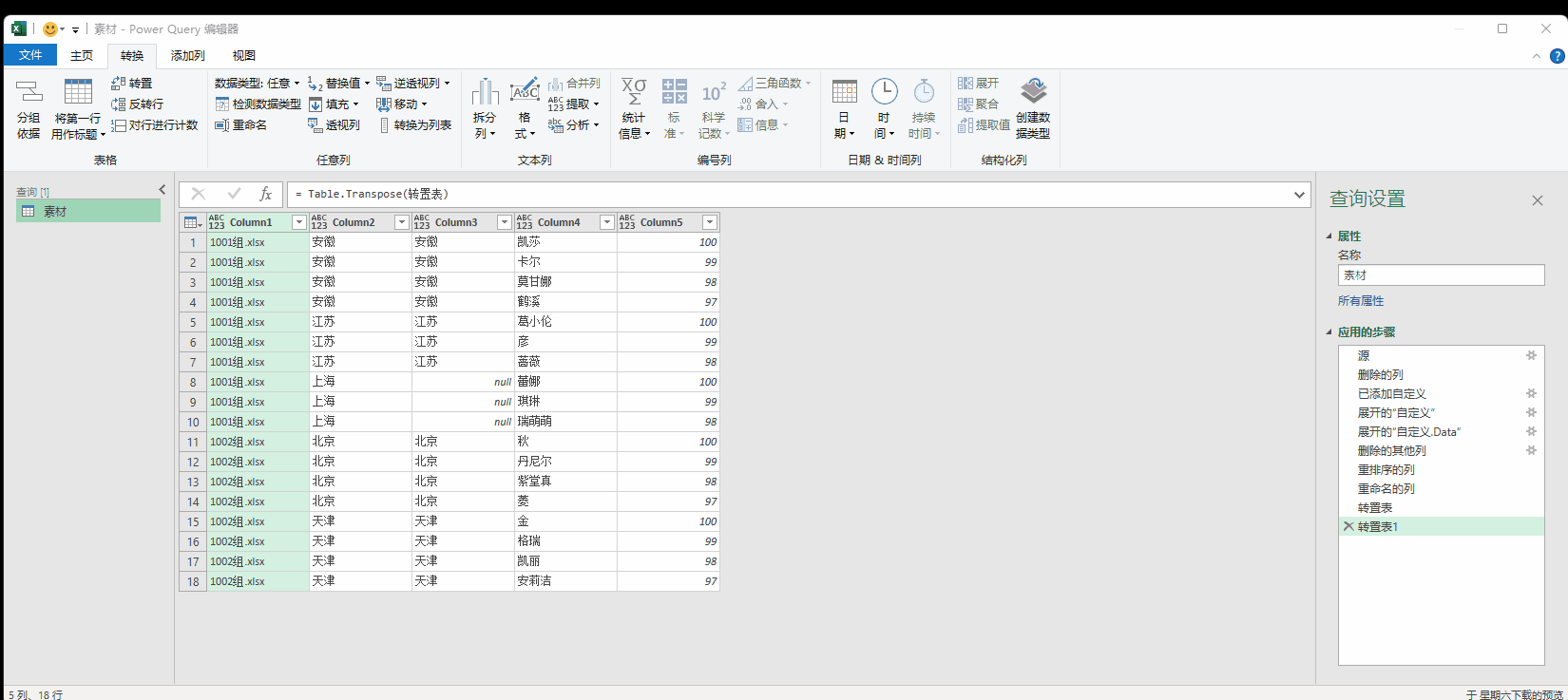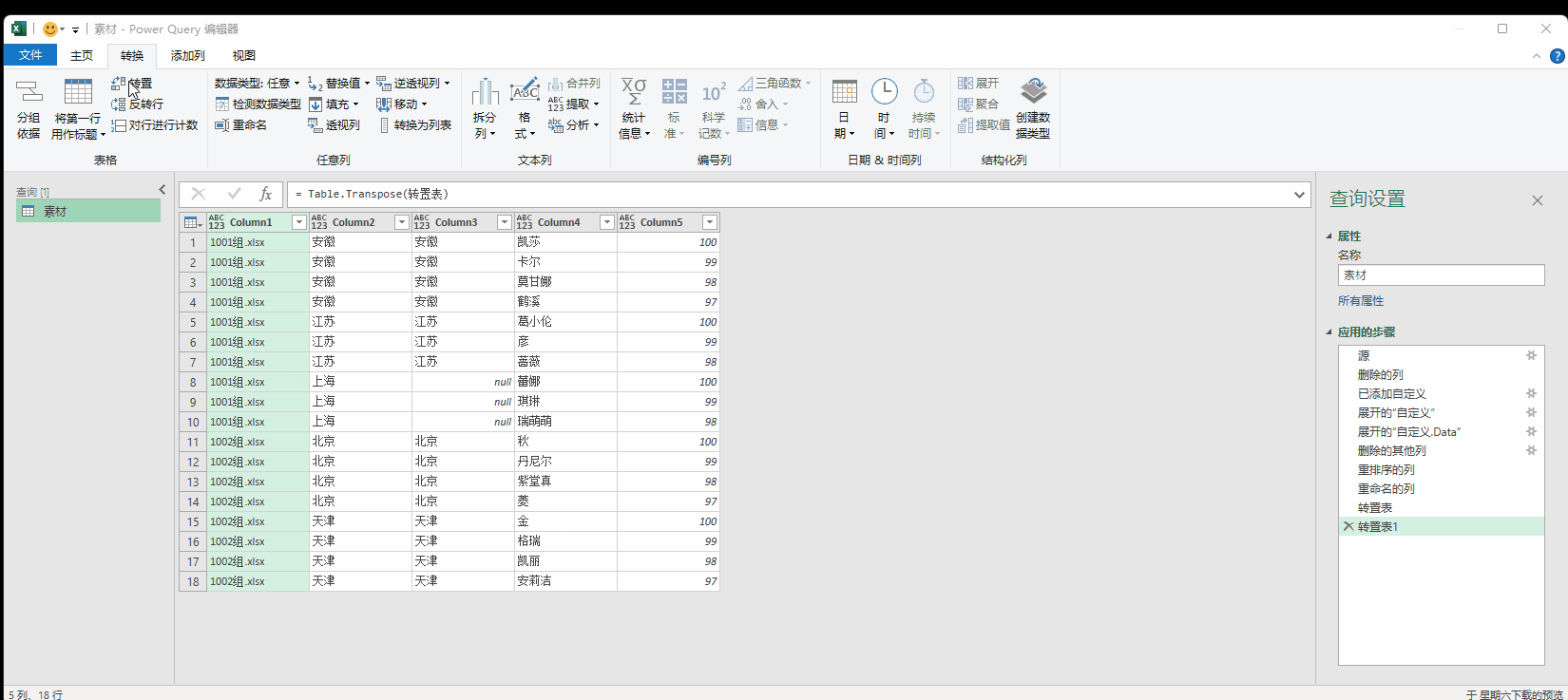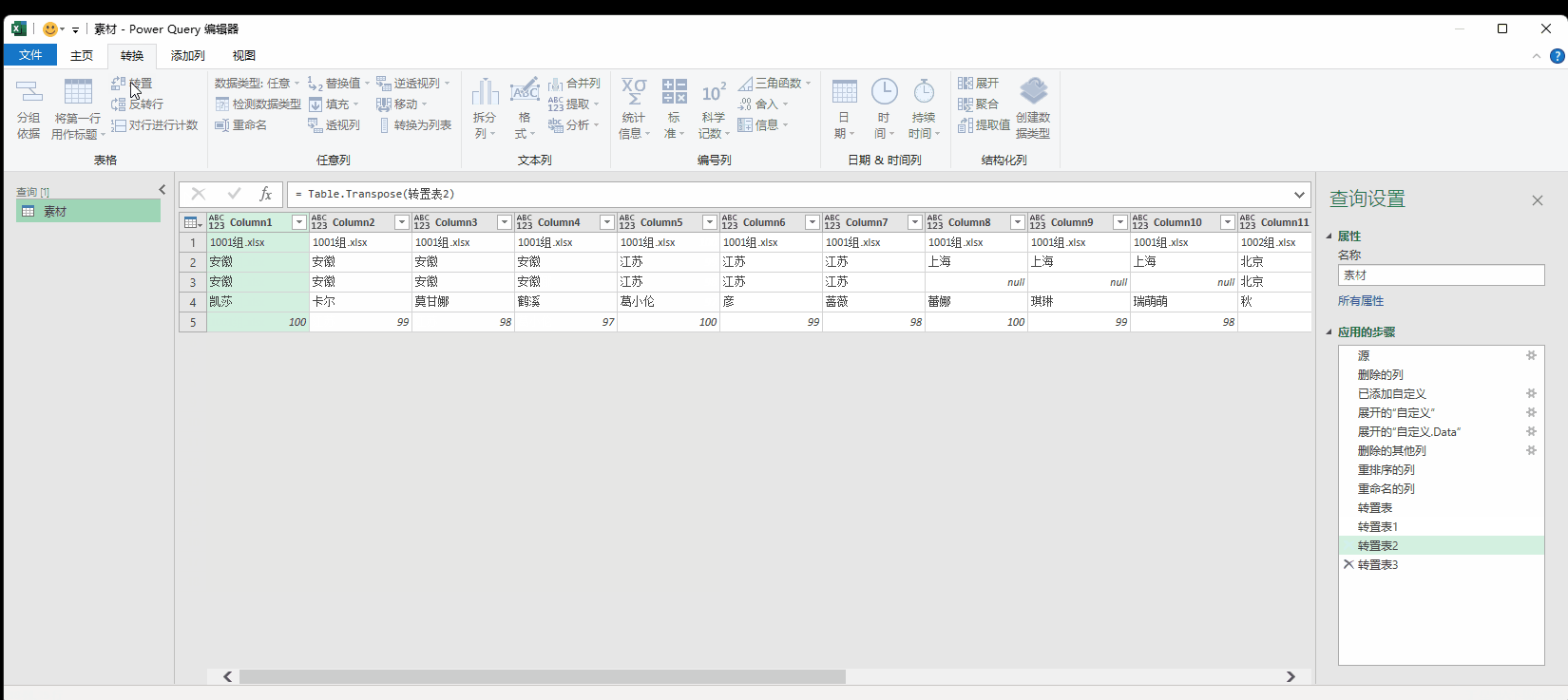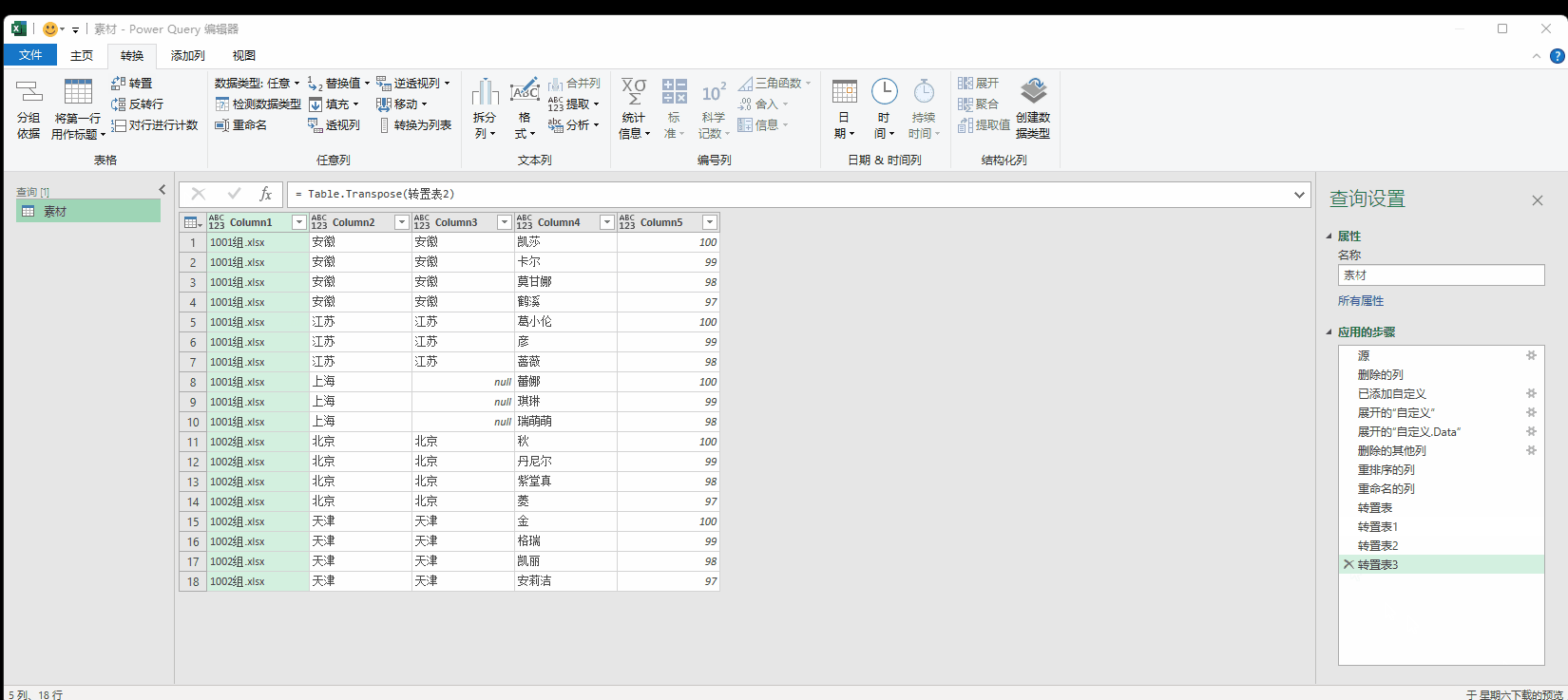
7.3 转置
就是把行变成列,列变成行,进行行列转换。
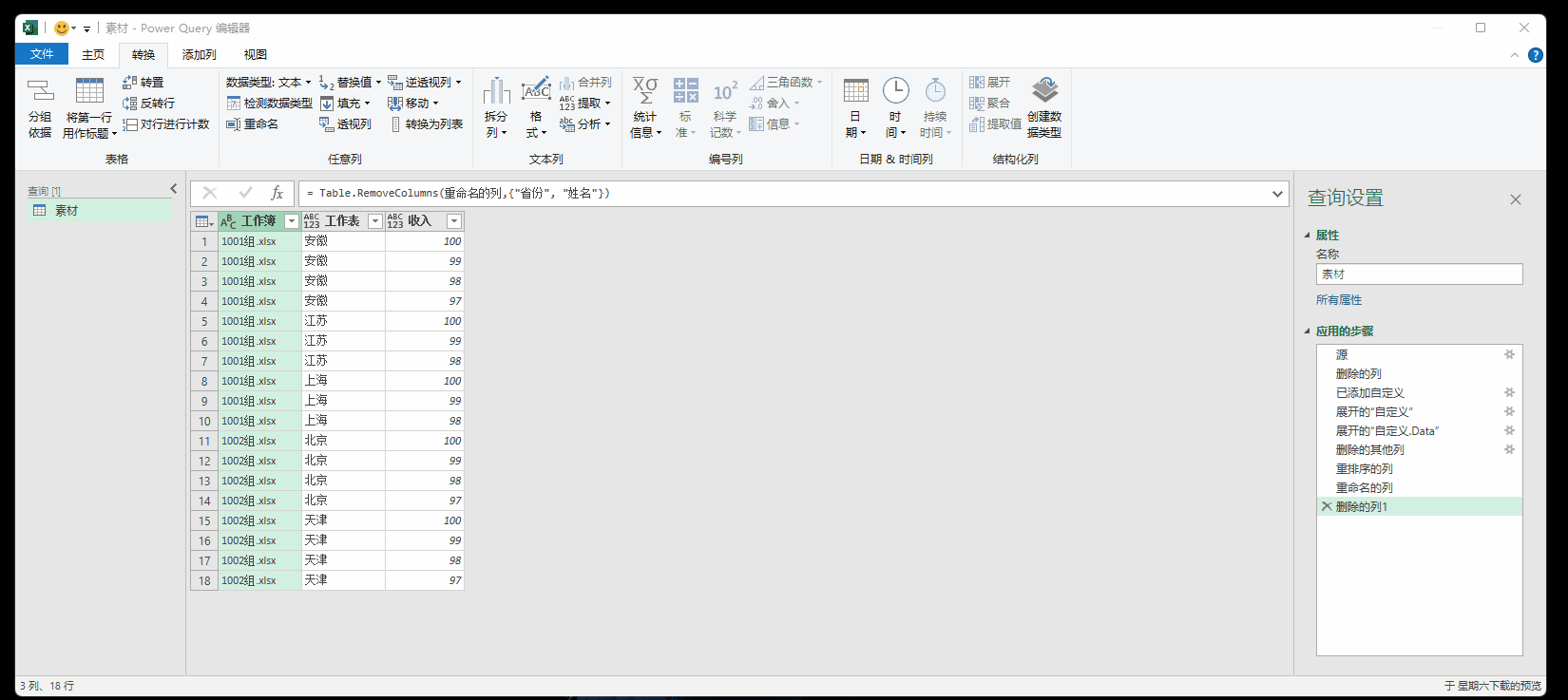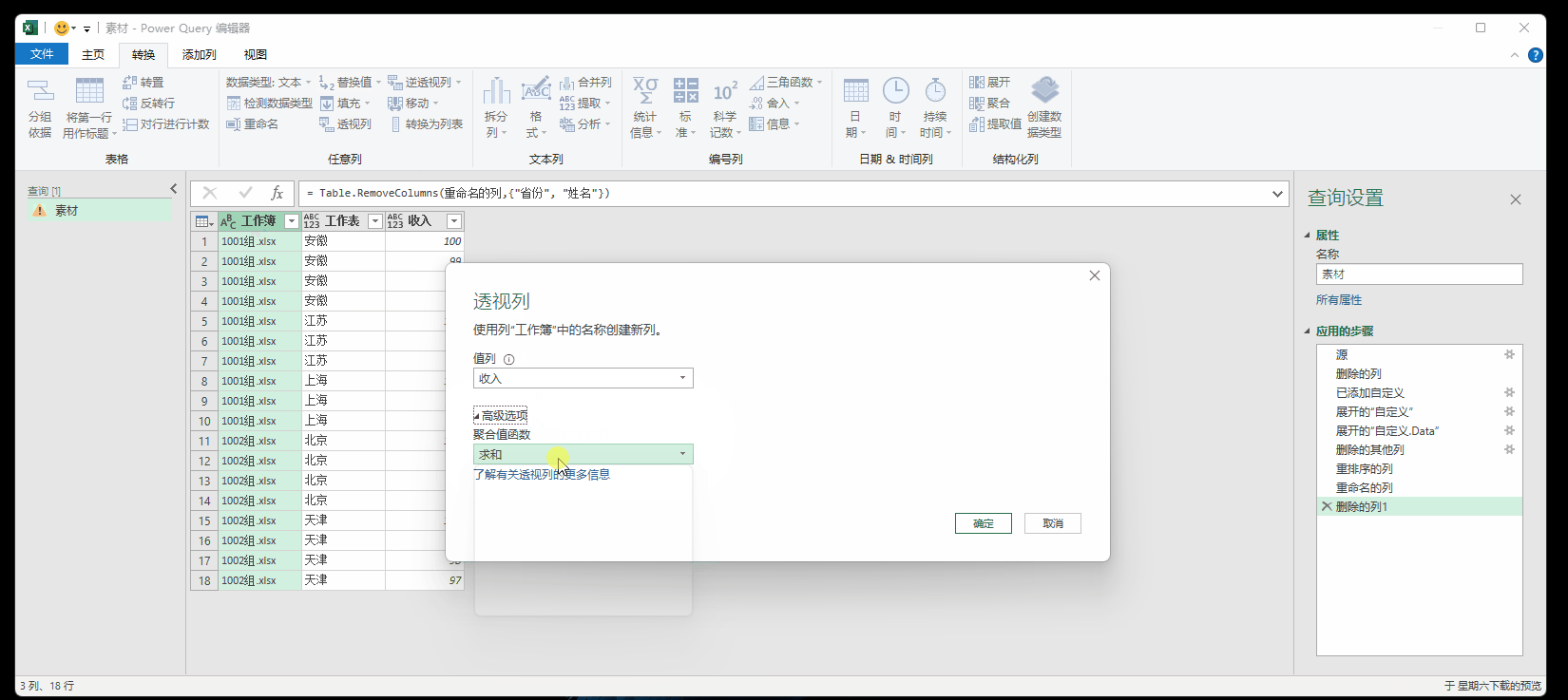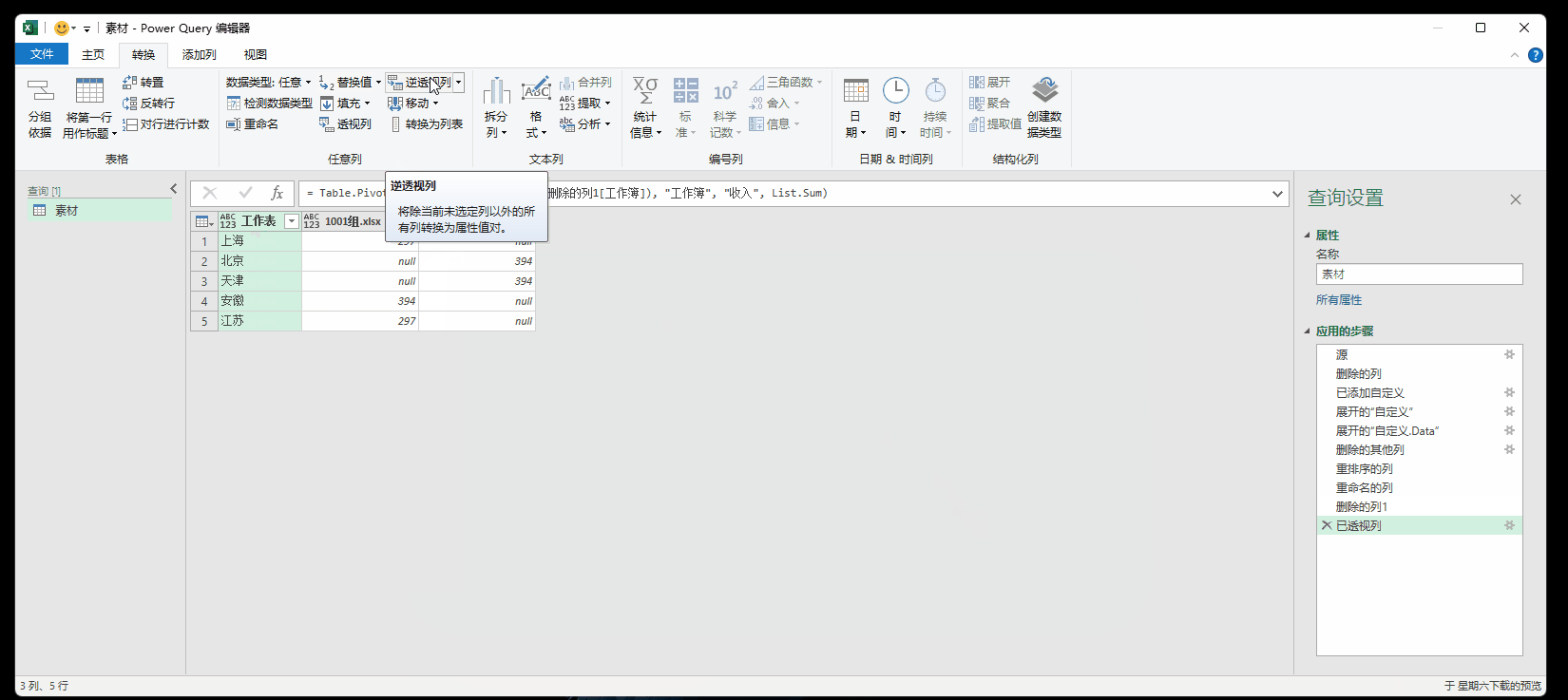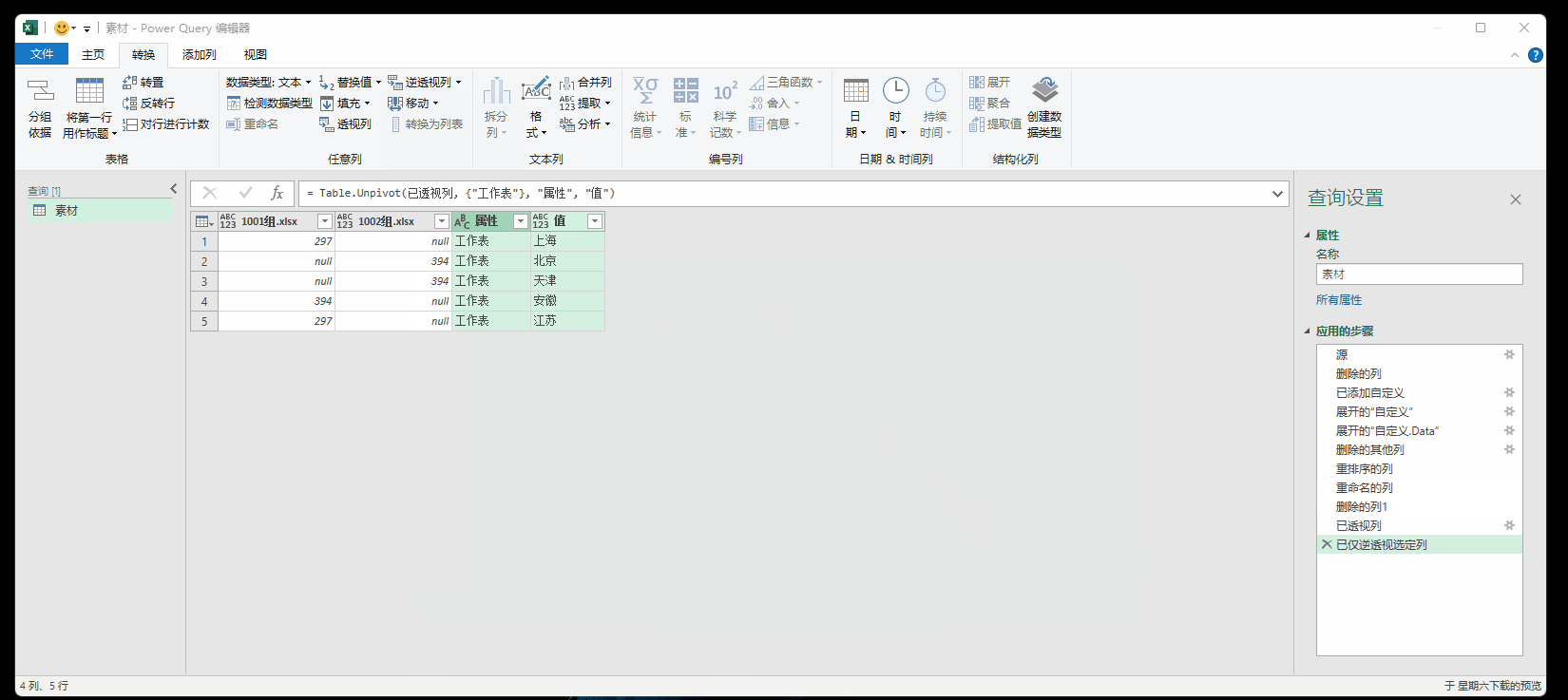
7.4 透视与逆透视
透视可以参考透视表,重点是逆透视,可以看成是PQ的一个大招。
逆透视参考博客:
八、其他
8.1 对行进行计数
任一选择一列,查看有多少行;
该功能更适合PP来操作
8.2 分组依据
也类似于透视表。
该功能更适合PP来操作

8.3 数字计算
对数字类型进行的计算

8.4 日期
对日期类型进行的计算;
涉及日期的一般有一个单独的日期维度表

8.5 多行属性合并
参考博客:
核心函数:Test.Combine
九、解决错误
错误的出现必须解决掉,因为错误不会影响到上传到模型和上传到表;所有的错误值会变成空白。
例如下图,处“十五”外,其他都是数字,当把格式设置成小数格式,上传之后会提示1个错误
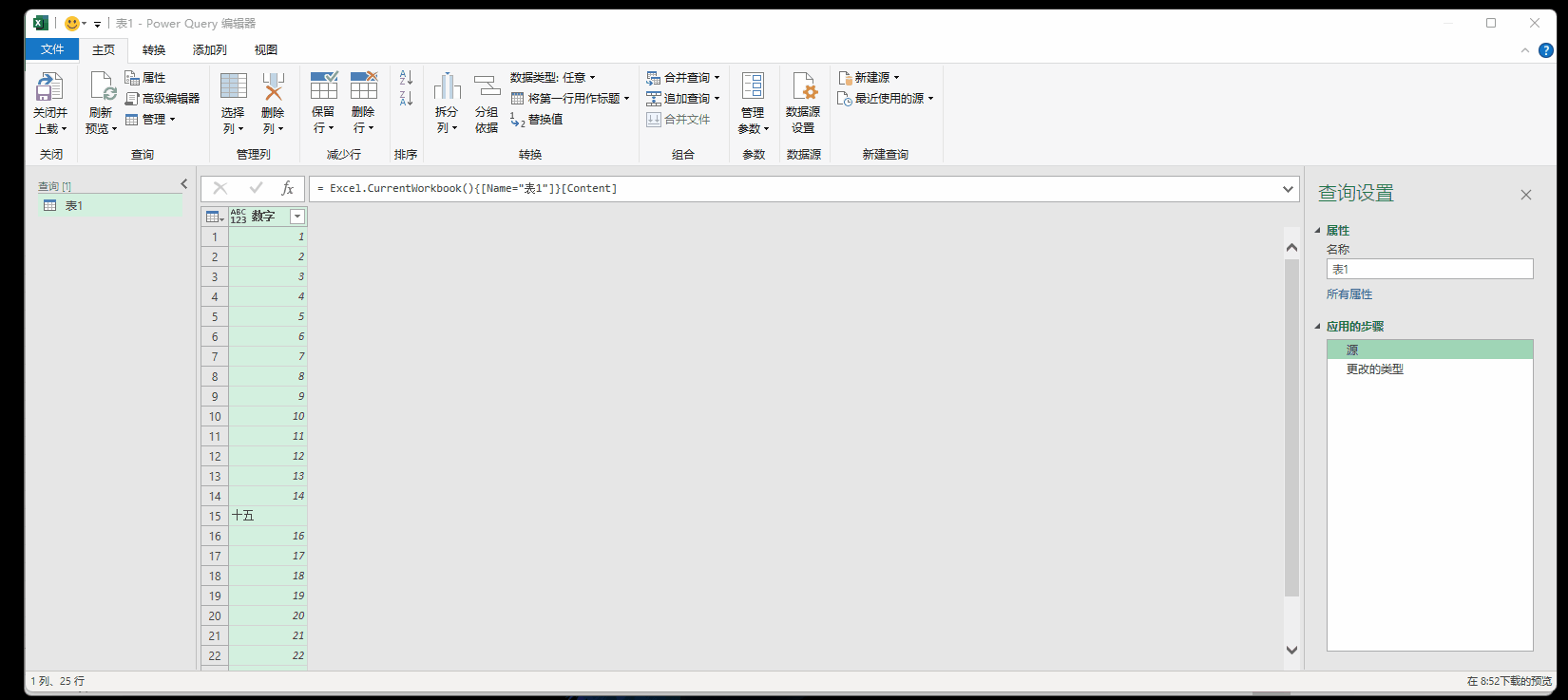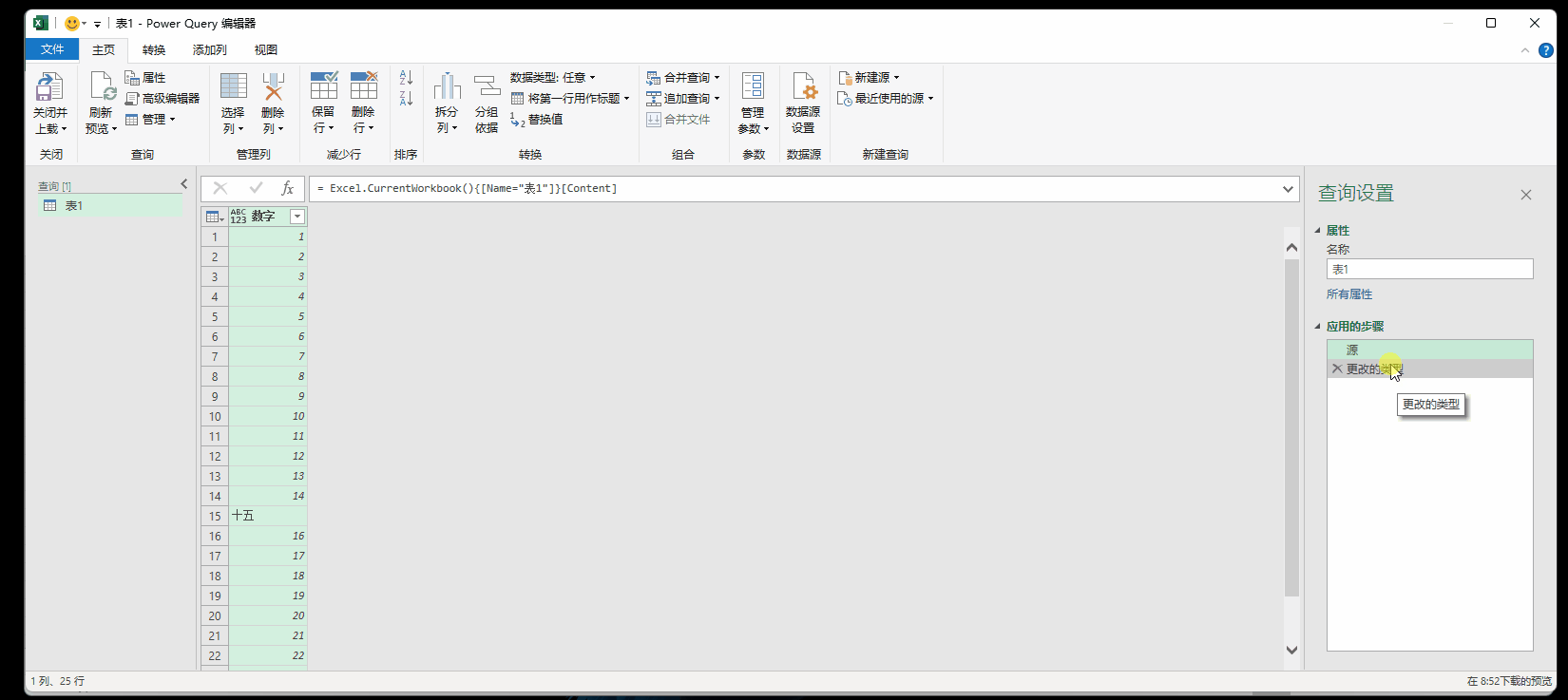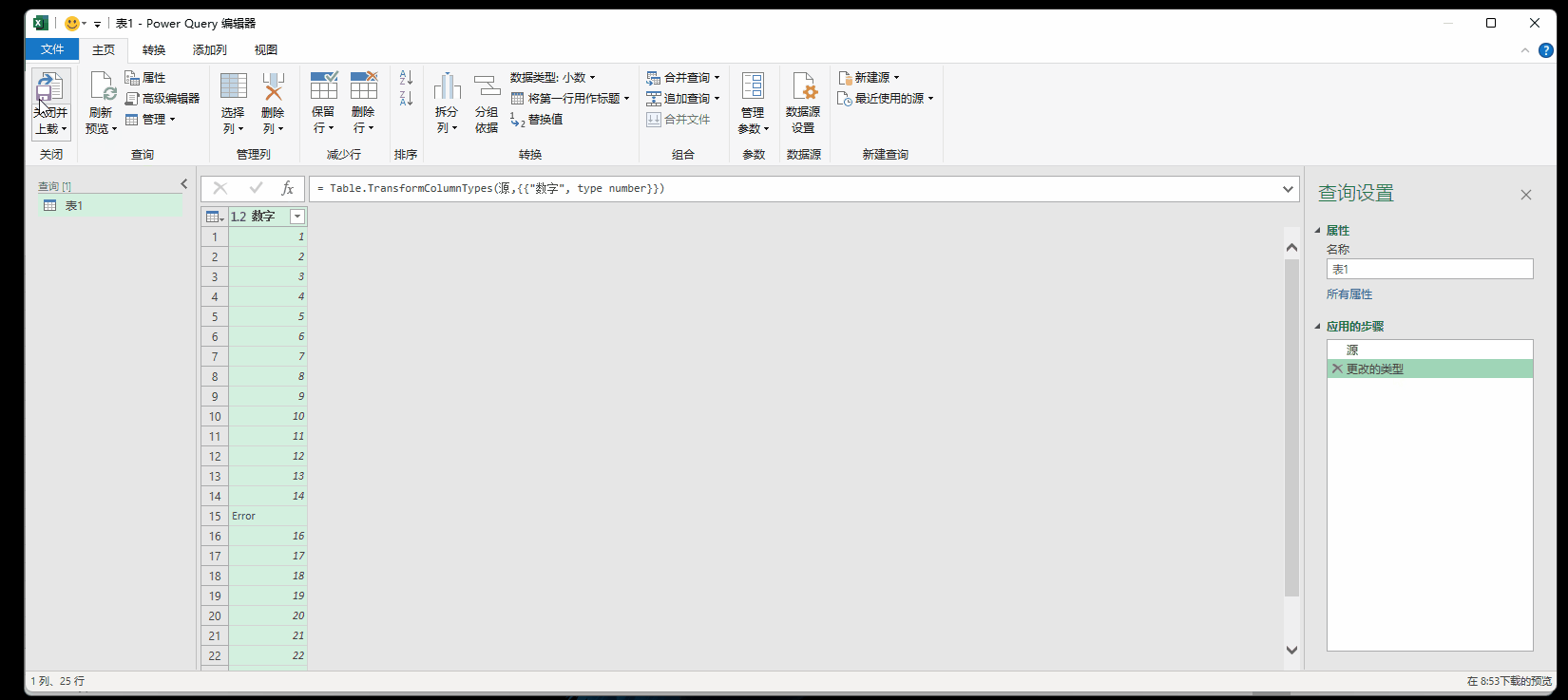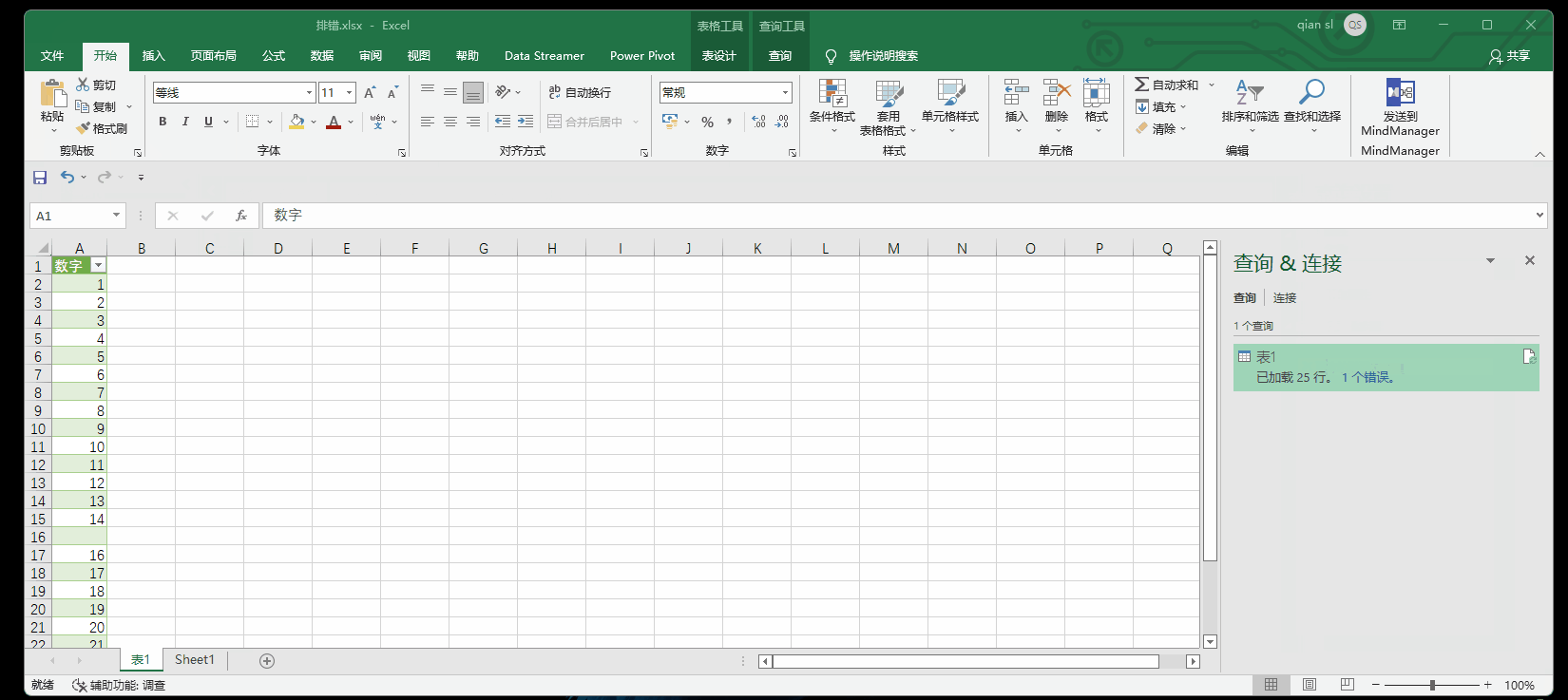
9.1 点击错误的超链接
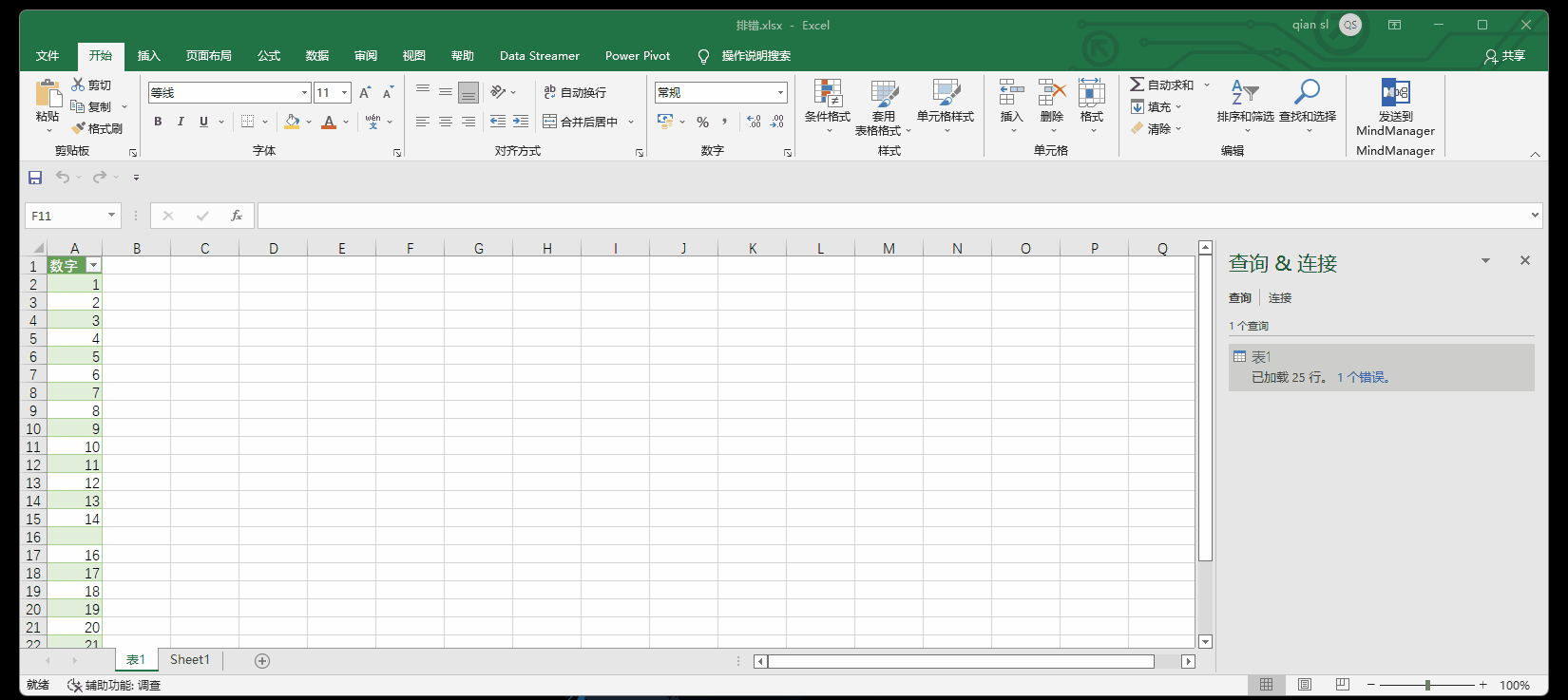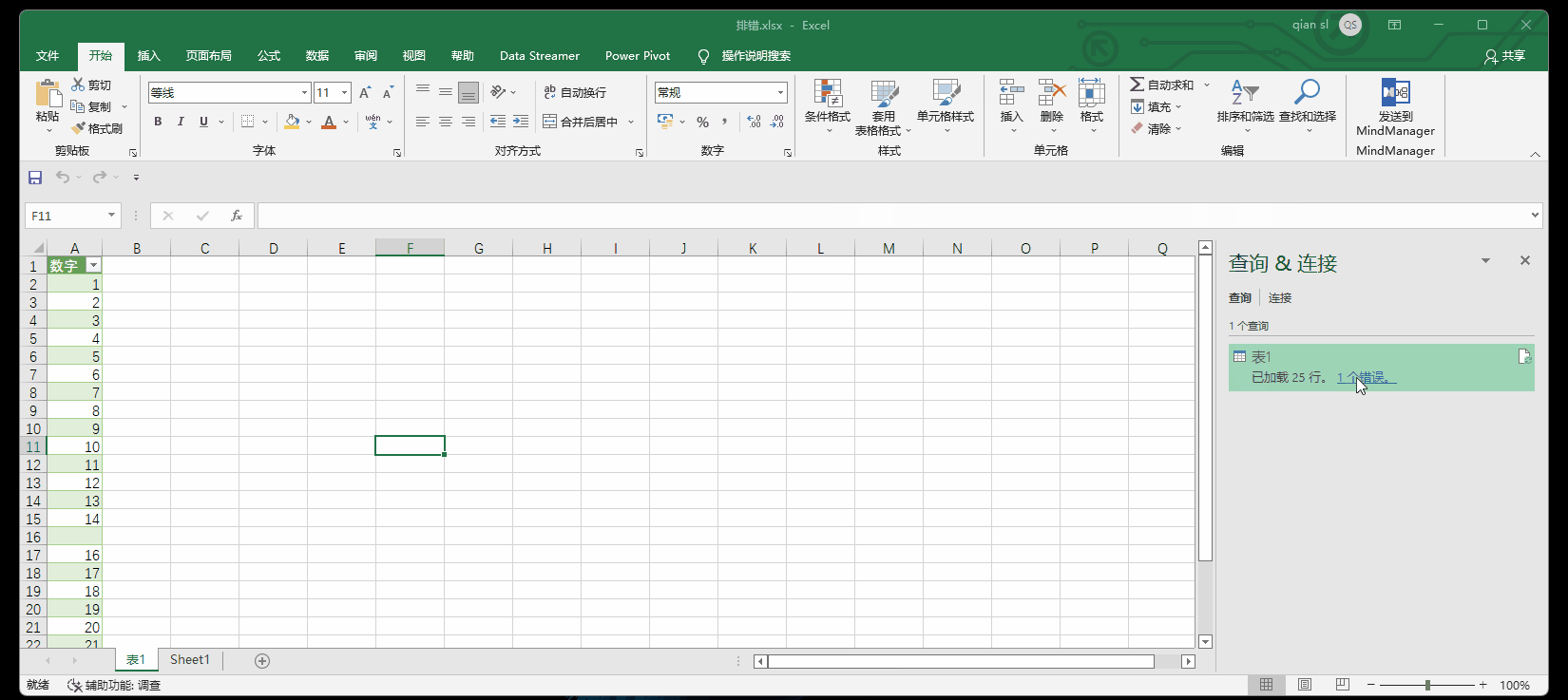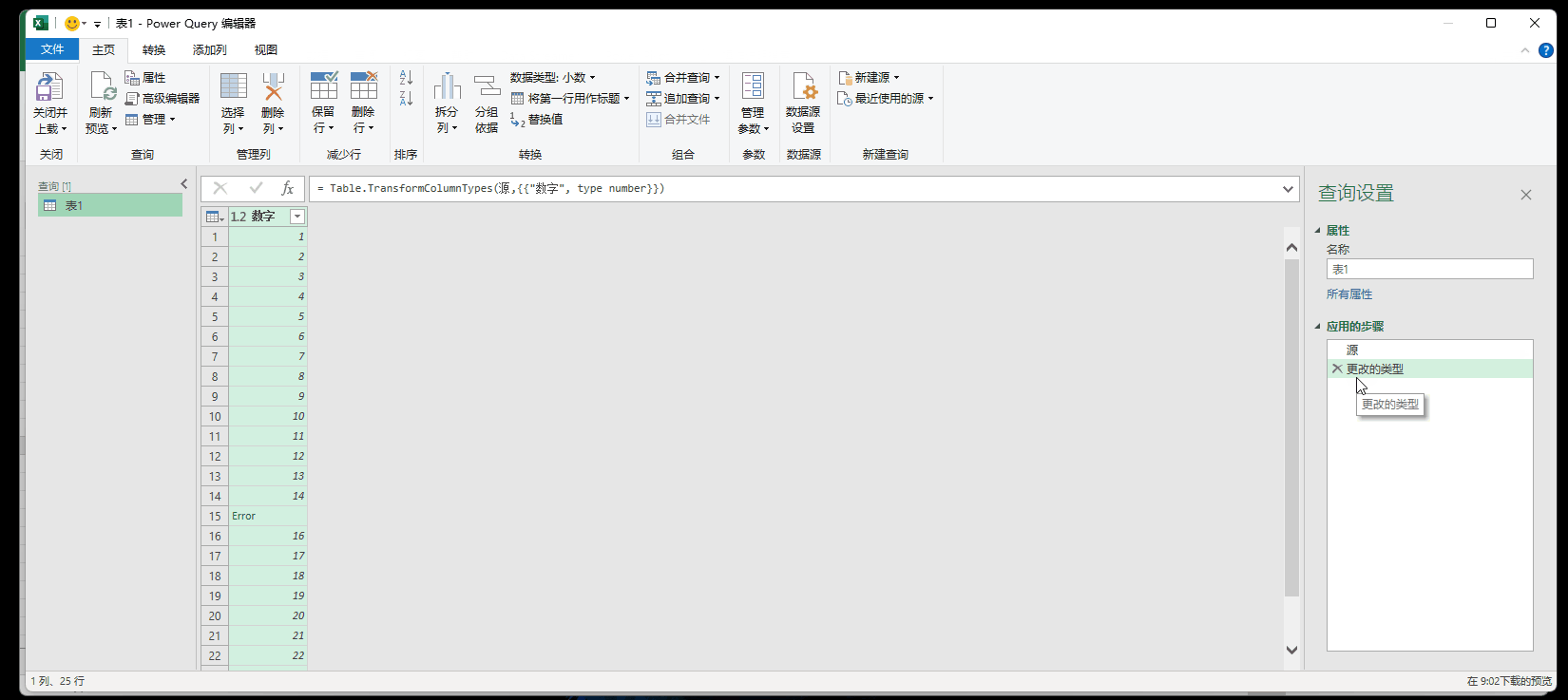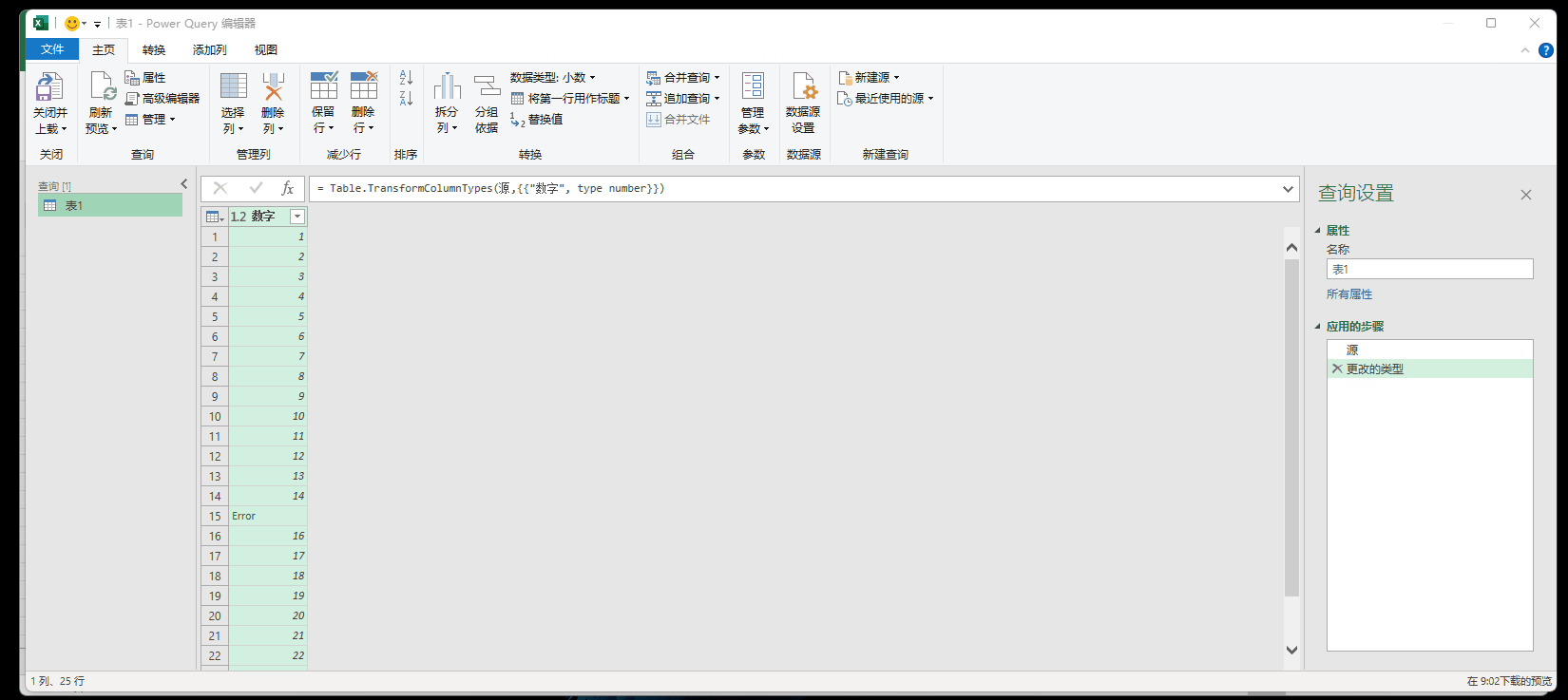
9.2 使用try函数
使用该函数的前提是知道错误列
字段“错误.HasError”为TRUE,则为错误选项;
建议进行排序,因为PP室友行数显示限制的,如果TRUE在行数范围之外,则无法筛选出来。
如果配合索引,则可精确定位错误行

参考文档:
https://docs.microsoft.com/zh-cn/powerquery-m/


















