
课程链接:Python人工智能20个小时玩转NLP自然语言处理【黑马程序员】_哔哩哔哩_bilibili
目录
一、神经网络基础知识
1、神经网络介绍:
*基本概念
*单层神经网络:感知机
*偏置节点(bias unit)
*训练
*多层神经网络(机器学习)
2、卷积神经网络CNN
*卷积神经网络的组成:
*激活函数
*卷积
*激励层与池化层
二、课程内容
1、典型流程:
*Conv2d函数
2、代码介绍
3、损失函数nn.MSELoss等
4、反向传播执行:
*反向传播顺序:
*代码实现:loss.backward()
5、更新网络参数(SGD)
*传统python代码实现
*pytorch实现
*小结
一、神经网络基础知识
1、神经网络介绍:
*基本概念
典型的神经网络包含三层:输入层、输出层、中间层(隐藏层)。输入输出层一般是固定的,中间层可以自由指定。拓扑与箭头表示预测过程中数据的走向。需要训练的是肩头上的权重,即连接线的权值。

神经网络基于神经元模型,几个输入通过不同权重求和,经过一个非线性函数输出。箭头表示值的加权传递。

这个基础的MP模型中最终输出的是sgn函数,即0或1。在完整的神经元中,将sum与sgn统一到一个函数中,且允许多个输出。后续的研究主要针对于特征与目标之间关系的权值。
*单层神经网络:感知机
为权值附上角标,得到下面的图

类似于线性方程组形式得到输出可以改写成:z=g(W*a),即神经网络中前一层计算后一层的矩阵运算。
*偏置节点(bias unit)
除去输出层之外,都设定一个偏置单元,要求只含有储存功能,且储存值永远为1。偏置单元与后一层的所有节点都连接,但是一般不会画出来
*训练
定义损失函数,要求所有训练数据的损失最小化。但是需要注意的是,机器学习中优化只是很小的一部分,更重要的是学习而不是优化,要求保证泛化能力。
*多层神经网络(机器学习)
CNN(Conventional Neural Network,卷积神经网络)
RNN(Recurrent Neural Network,递归神经网络)
在两层神经网络的输出层后面,继续添加层次。原来的输出层变成中间层,新加的层次成为新的输出层。所以可以得到下图。

依照这样的方式不断添加,我们可以得到更多层的多层神经网络。公式推导的话其实跟两层神经网络类似,使用矩阵运算的话就仅仅是加一个公式而已。
在已知输入a(1),参数W(1),W(2),W(3)的情况下,输出z的推导公式如下:
- g(W(1) * a(1)) = a(2);
- g(W(2) * a(2)) = a(3);
- g(W(3) * a(3)) = z;
2、卷积神经网络CNN
神经网络的每一个神经元如下:

wx + b的形式,其中
- X1X2表示输入向量
- W1W2为权重,几个输入则意味着有几个权重,即每个输入都被赋予一个权重
- b为偏置bias
- g(z) 为激活函数
- a 为输出
因此有:
*卷积神经网络的组成:
- 输入层。输入层是整个神经网络的输入,在处理图像的卷积神经网络中,它一般代表了一张图片的像素矩阵。三维矩阵的长和宽代表了图像的大小,而三维矩阵的深度代表了图像的色彩通道(channel)。从输入层开始,卷积神经网络通过不同的神经网络结构将上一层的三维矩阵转换成下一层的三维矩阵,直至最后的全连接层。
- 卷积层。和传统全连接层不同,卷积层中每个节点的输入只是上一层神经网络的一小块,这个小块常用的大小有3*3或者5*5.卷积层试图将神经网络中的每一小块进行更加深入的分析从而得到抽象程度更高的特征。一般来说通过卷积层处理过的节点矩阵会变得更深。
- 池化层(Pooling)。池化层神经网络不会改变矩阵的深度,但是它可以缩小矩阵的大小。通过池化层可以进一步缩小最后全连接层中节点的个数,从而达到减少整个神经网络中参数的目的。
- 全连接层。在经过多轮卷积层和池化层的处理之后,在卷积神经网络的最后一般会是由一到两个全连接层来给出最后的分类结果。
- softmax层。Softmax层主要用于解决分类问题,通过softmax层,可以得到当前样例属于不同种类的概率分布情况。
因为没太弄清楚卷积和池化所以问了朋友:

*激活函数
激活函数一开始是线性函数g(z)=g(w1x1+w2x2+b),b表示调整作用的偏置项。后引入非线性激活函数sigmoid函数:

z表示w1x1+w2x2+b或者其他线性组合,其图像表示如下( 横轴表示定义域z,纵轴表示值域g(z) ),即将一个实数压缩到0,1空间中,也就是说,sigmoid函数的功能是相当于把一个实数压缩至0到1之间。当z是非常大的正数时,g(z)会趋近于1,而z是非常小的负数时,则g(z)会趋近于0,由此就可以把激活函数堪称一种分类正负样本的概率。

例如,在两个样本的分类问题中,通过设定合适的sigmoid函数使得只有

和
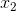
都取1的时候,g(z)→1,判定为正样本;
或
取0的时候,g(z)→0,判定为负样本,如此达到分类的目的。
还有常用的非线性激活函数有sigmoid、tanh、relu等等。
*卷积
卷积神经网络在图像识别问题中将图像分割为多个小块,并分别进行匹配。
卷积,即对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)
理解起来,w1x1+w2x2+b就是一个滤波器。多个滤波器叠加就是卷积层。使用不同的滤波器进行图像处理,则可以得到不同的颜色深浅、轮廓数据等输出数据。
*激励层与池化层
实际梯度下降中,sigmoid容易饱和、造成终止梯度传递,且没有0中心化。
激活函数:ReLU收敛快,作为激励层

池化层是取小块区域的平均或者最大,来缩小数据(下图取最大)

二、课程内容
主要使用的包:torch.nn 构建子模块的包都在其中,以来auto grad自动求导
1、典型流程:
- 定义拥有可学习参数的神经网络【梯度下降与反向传输依赖于可学习参数】
- 遍历训练数据
- 处理输入数据使其流经神经网络
- 计算损失值
- 将网络参数的梯度进行反向传播
- 以一定的规则更新网络的权重、
*Conv2d函数
其中比较重要的是Conv2d函数,用来实现2d卷积操作,其输入参数如下:
- in_channels —— 输入的channels数
- out_channels —— 输出的channels数
- kernel_size ——卷积核的尺寸(图像处理时给定输入图像,输入图像中一个小区域中像素加权平均后成为输出图像中的每个对应像素,其中权值由一个函数定义,这个函数称为卷积核)
- stride —— 步长,用来控制卷积核移动间隔
- padding ——输入边沿扩边操作
- padding_mode ——扩边的方式
- bias ——是否使用偏置(即out = wx+b中的b)
- dilation —— 取数的间隔,=2则表示隔一个格取数
Conv2d函数要求批次样本输入,不接受单一样本,要求4DTensor,形状为(nsamples,nchannels,height,width)。单一样本需要扩充,设置nsamples为1
2、代码介绍
import torch
import torch.nn as nn
import torch.nn.functional as F
#定义一个简单的网络类(一个初始化函数+一个前向包裹函数+维度扁平化)
class Net(nn.Module):#所有的类的定义都继承nn.Module
#一共定义两个卷积层
def__init__(self):
super(Net,self).__init__()#首先定义初始化函数
#第一层卷积网络,输入维度1,输出维度6,卷积核3*3
self.conv1=nn.Conv2d(1,6,3)
#第二层卷积网络,输入维度6,输出维度16,卷积核3*3(2的输入就是1的输出)
self.conv2=nn.Conv2d(6,16,3)
#定义三层全连接层
self.fc1=nn.Linear(16*6*6,120)#未来输入的图片是32*32,需要推导
self.fc2=nn.Linear(120,84)
self.fc3=nn.Linear(84,10)
#前向传播
def forward(self,x):
#在(2,2)池化窗口下执行最大池化操作
#在第一个卷积层下relu且2*2池化
x=F.max_pool2d(F.relu(self.conv1(x)),(2,2))
#在第二个卷积层下relu
x=F.max_pool2d(F.relu(self.conv2(x)),2)
x=x.view(-1,self.num_flat_features(x))#减少了一个张量的维度
#num_flat_features表示卷积后的张量x计算size,见下
#在一二全连接层中relu,并在第三层输出
x=F.relu(self.fc1(x))
x=F.relu(self.fc2(x))
x=self.fc3(x)
return x
def num_flat_features(self,x)
#计算size,第零个维度上的batch_size(一次训练所抓取的数据样本数量)不计算
size=x.size()[1:]#取后两位
num_features=1
for s in size:
num_features*=s
return num_features
net=Net()#实例化
print(net)3、损失函数nn.MSELoss等
output=net(input)
#模拟十个标签
target=torch.randn(10)
#变成二维张量
target=target.view(1,-1)
#计算均方差损失模拟差距
criterion=nn.MSELoss()
#预测值和真实值之间的差距
loss=criterion(output,target)
print(loss)4、反向传播执行:
*反向传播顺序:

*代码实现:loss.backward()
#注意在反向传播之前需要将梯度首先清零
net.zero_grad()
#先打印第一个卷积层偏置清零前的数据
print("conv1.bias.grad before backward")
print(net.conv1.bias.grad)
#反向传播(就是这一句)
loss.backward()
print("conv1.bias.grad after backward")
print(net.conv1.bias.grad)5、更新网络参数(SGD)
随机梯度下降SGD(weight=weight-learning_rate*gradient)
*传统python代码实现
learning_rate=0.01#超参数
for f in net.parameters():#遍历所有参数
f.data.sub_(f.grad.data*learning_rate)#就地减法替代*pytorch实现
import torch.optim as optim
#有一个包提供常见的优化算法SGD、Adam等
#创建优化器优化的对象,就是网络中所有可训练参数net.parameters()
#lr设置初始学习率
optimizer=optim.SGD(net.parameters(),lr=0.01)
#注意三步走:梯度清零zero_grad(),反向传播backward(),参数更新step()
#优化器首先清零
optimizer.zero_grad()
#输入
output=net(input)
loss=criteron(output,target)
#执行反向传播
loss.backward()
#进行参数更新!!!
#optimizer.step()*小结




















