
二分类问题与logistic 回归
回归问题
“回归”一词源自英国科学弗朗西斯·高尔顿(Francis Galton),他还是著名的生物学家、进化论奠基人查尔斯·达尔文(Charles Darwin)的表弟。高尔顿发现,虽然有一个趋势——父母高,儿女也高;父母矮,儿女也矮,但给定父母的身高,儿女辈的平均身高却趋向于或者“回归”到全体人口的平均身高。换句话说,即使父母双方都异常高或者异常矮,儿女的身高还是会趋向于人口总体的平均身高。这也就是所谓的普遍回归规律。高尔顿的这一发现被他的朋友,英国数学家、数理统计学的创立者卡尔·皮克逊(Karl Pearson)所证实。皮尔逊收集了一些家庭的1000多名成员的身高记录,发现对于一个父亲高的群体,儿辈的平均身高低于他们父辈的身高;而对于一个父亲矮的群体,儿辈的平均身高则高于其父辈的身高。这样就把高的和矮的儿辈一同“回归”到所有男子的平均身高,用高尔顿的话说,这是“回归到中等”
回归分析是被用来研究一个被解释变量(Explained Variable)与一个或多个解释变量(Explanatory Variable)之间关系的统计技术。被解释变量有时也被称为因变量(Dependent Variable),与之相对应地,解释变量也被称为自变量(Independent Variable)。回归分析的意义在于通过重复抽样获得的解释变量的已知或设定值来估计或者预测被解释变量的总体均值。
下面举一个简单的线性回归实例来了解其中的原理:
通过调查我们记录了父辈身高与子辈身高的几组数据。

y=wx+b
其中w、b表示回归参数。我们只要找到了符合条件的w、b,就可以通过这个回归模型预测y的值。
更一般的,如果我们的解释变量不止一个,且他们与被解释变量存在线性关系,我们就可以构建这样的回归模型:
y=w1x1+w2x2+w3x3+···+wnxn+b
Logistic回归
线性回归解决了连续变量之间的关系问题,但是现实生活中也会存在许多离散的分类问题。例如我们要判别一张图片的内容是不是“猫”,这里我们只希望预测结果为“是”或者“否”,那么我们就要对一般的回归进行改造。于是便出现了logistic regression模型:
如下图,我们希望通过数学模型很好的区分下面的点该分为哪一区域(类),假设为0和1。

这个问题中,我们输入点的坐标是可以连续变化的,但我们希望得到到的结果是离散的,于是我们可以构建logistic回归模型来预测图中的点属于哪一类。
我们假设可以找到一条直线可以很好的区分两个区域,首先我们求横纵坐标(x1,x2)的线性和(w1、w2、b是回归参数):
z=w1x1+w2x2+b
将z的值通过Sigmoid函数映射到0~1之间
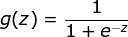
g(z)的值我们将它看做是(x1,x2)对应的z属于0还是1这一类的概率,假设P0、P1分别 代表属于0、1的概率,则有
P1=g(z)
P0=1-g(z)
于是通过比较概率的大小我们就能确定(x1,x2)对应的点属于哪一类了。其中P=0.5对应的点所在的直线就成为决策边间(z=w1x1+w2x2+b,g(z)=0.5)
如果找到了合适的回归参数,上述模型就能很好的解决这类问题了,接下来看看如何通过学习算法找到这些参数:
我们将所有参数向量化表示,θ=(θ0,θ1,θ2,θ3,···,θn)T,X=(x1,x2,x3,···,xn),n表示特征数,m表示数据集大小,X(i)和y(i)表示第i个数据。
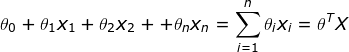
预测函数
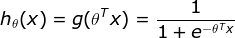
属于不同类的概率
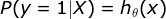
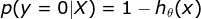
由于y只能等于1或0,将上式结合起来表示
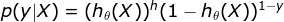
在我们的数据集中一组X(x1,x2,···,xn)对应一个类别y,我们通将这组数据代入上式就能评估模型的准确程度。显然,模型越准确时p(y|X)的值就越大,所以我们希望通过调整θ来增大P。现在我们得到了一组数据的情况,那么我们需要一个函数来观测模型在整个数据集上的准确程度,取似然函数
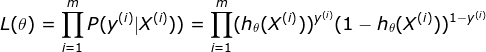
这样我们就得到了这个模型在整个数据集下的表现,显然L约大模型越准确。而且可以知道0<=L<=1。我们在对此函数进行等价处理
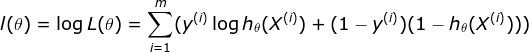
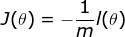
通过上式变换,我们构建了数据集在模型上的表现与参数θ之间的函数关系,我们根据这个函数关系来找到最适合这个数据集的参数,也就是找到使得J足够小的θ。
梯度下降算法
在学习高等数学时我们经常遇到求一个函数最小值的问题,当时利用导数工具可以求得函数在某一点的梯度,根据梯度可以找到最值。
对于上述的logsitic回归我们先设置一组初始值参数,然后这组参数为起始点,求出各个方向的梯度,然后根据梯度来更新参数。具体过程如下
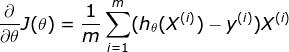
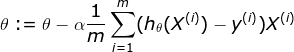
经过上面几个步骤就可以找到一个比较好的模型来接觉简单的二分类问题。



















