
在之前的视频学习中,我们使用的模型被称为全连接神经网络。
全连接 NN:每个神经元与前后相邻层的每一个神经元都有连接关系,输入是特征,输出为预测的结果。
参数个数:∑(前层 × 后层 + 后层)

这只是一张28*28的黑白图片,在实际生活中,更多的则是RGB格式的彩色图像,像素点更多,且为红绿蓝三通道信息。
待优化的参数过多,容易导致模型过拟合。为避免这种现象,实际应用中一般不会将原始图片直接喂入全连接网络。
因此,在实际应用中,会先对原始图像进行特征提取,把提取到的特征喂给全连接网络,再让全连接网络计算出分类评估值。

特征值的提取有多种方法,下面介绍一种常用方法,卷积
卷积 Convolutional
卷积是一种有效提取图片特征的方法。一般用一个正方形卷积核,遍历图片上的每一个像素点。图片与卷积核重合区域内相对应的每一个像素值乘卷积核
内相对应点的权重,然后求和,再加上偏置后,最后得到输出图片中的一个像素值。

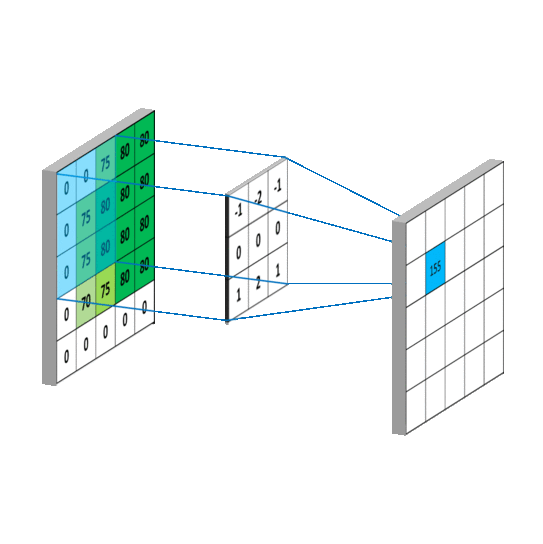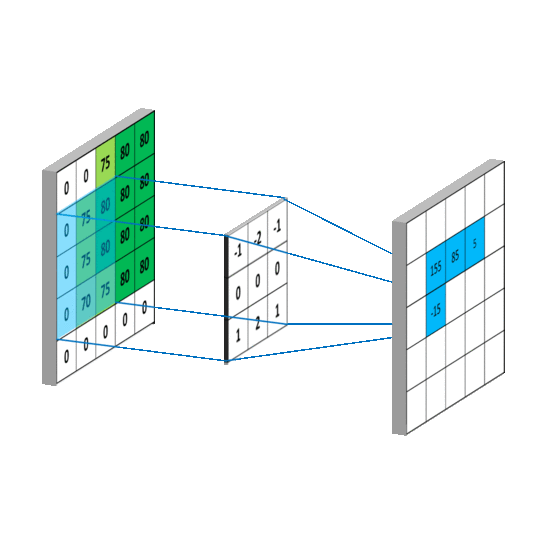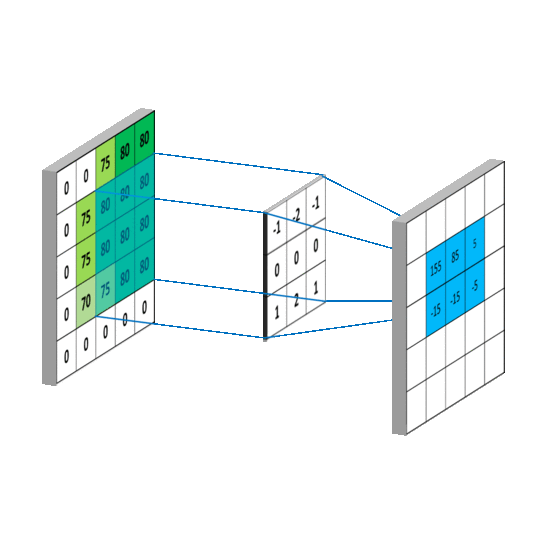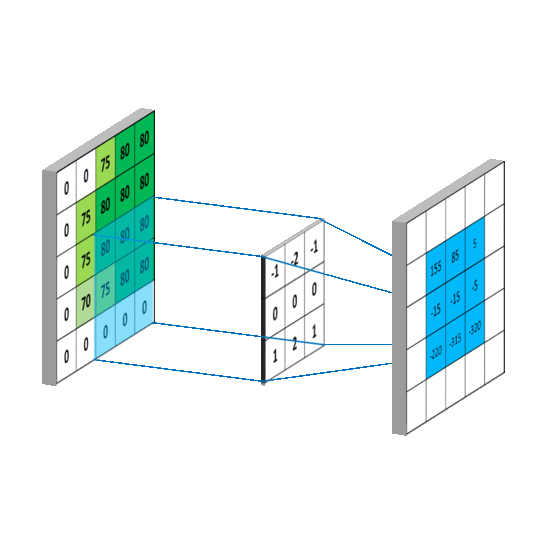
上图是一个5x5x1 的灰度图片,1 表示单通道,5x5 表示分辨率,共有 5 行 5列个灰度值。若用一个 3x3x1 的卷积核对此 5x5x1 的灰度图片进行卷积,,偏置项b=1,
则求卷积的计算是: (-1)x1+0x0+1x2+(-1)x5+0x4+1x2+(-1)x3+0x4+1x5+1=1(注意不要忘记加偏置 1)。
其中,得到的计算结果1是以 3x3x1 的卷积核的中间位置0对应的位置。
输出图片边长=(输入图片边长–卷积核长+1)/步长,此图为:( 5 – 3 + 1)/ 1 = 3,输出图片是 3x3 的分辨率,用了 1 个卷积核,输出深度是 1,
最后输出的是3x3x1 的图片。
卷积核每滑动一次,会输出一个特定的值
全零填充 Padding
有时会在输入图片周围进行全零填充,这样可以保证输出图片的尺寸和输入图片一致。

例:在前面 5x5x1 的图片周围进行全零填充,可使输出图片仍保持 5x5x1 的维度。这个全零填充的过程叫做 padding。 输出数据体的尺寸=(W−F+2P)/S+1
W:输入数据体尺寸,F:卷积层中神经元感知域,S:步长,P:零填充的数量。
例:输入是 7×7,滤波器是 3×3,步长为 1,填充为 0,那么就能得到一个 5×5的输出((5-3+2)/1+1=5)。如果步长为 2,输出就是 3×3。
如果输入量是 32x32x3,核 是 5x5x3,不用全零填充,输出是(32-5+1)/1=28,
如果要让输出量保持在 32x32x3,可以对该层加一个大小为 2 的零填充。可以根据需求计算出需要填充几层零。32=(32-5+2P)/1 +1,计算出 P=2,即需填充 2层零。 
使用 padding 和不使用 padding 的输出维度

上一行公式是使用 padding 的输出图片边长,下一行公式是不使用 padding的输出图片边长。公式如果不能整除,需要向上取整数。
如果用全零填充,也就是 padding=SAME。如果不用全零填充,也就是 padding=VALID
Tensorflow 给出的计算卷积的函数

函数中要给出四个信息:对输入图片的描述、对卷积核的描述、对卷积核滑动步长的描述以及是否使用 padding。
1)对输入图片的描述:用 batch 给出一次喂入多少张图片,每张图片的分辨率大小,比如 5 行 5 列,以及这些图片包含几个通道的信息,如果是灰度图
则为单通道,参数写 1,如果是彩色图则为红绿蓝三通道,参数写 3。
2)对卷积核的描述:要给出卷积核的行分辨率和列分辨率、通道数以及用了几个卷积核。比如上图描述,表示卷积核行列分辨率分别为 3 行和 3 列,且是
1 通道的,一共有 16 个这样的卷积核,卷积核的通道数是由输入图片的通道数决定的,卷积核的通道数等于输入图片的通道数,所以卷积核的通道数也是 1。
一共有 16 个这样的卷积核,说明卷积操作后输出图片的深度是 16,也就是输出为 16 通道。
3)对卷积核滑动步长的描述:上图第二个参数表示横向滑动步长,第三个参数表示纵向滑动步长。第一个 1 和最后一个 1 这里固定的。这句表示横向纵向
都以 1 为步长。
4)是否使用padding:用的是VALID。注意这里是以字符串的形式给出VALID。
对多通道的图片求卷积
多数情况下,输入的图片是 RGB 三个颜色组成的彩色图,输入的图片包含了红、绿、蓝三层数据,卷积核的深度应该等于输入图片的通道数,所以使用 3x3x3
的卷积核,最后一个 3 表示匹配输入图像的 3 个通道,这样这个卷积核有三层,每层会随机生成 9 个待优化的参数,一共有 27 个待优化参数 w 和一个偏置 b。
对于彩色图,按层分解开,可以直观表示为上面这张图,三个颜色分量:红色分量、绿色分量和蓝色分量。 卷积计算方法和单层卷积核相似,卷积核为了匹配红绿蓝三个颜色,把三层
的卷积核套在三层的彩色图片上,重合的 27 个像素进行对应点的乘加运算,最后的结果再加上偏置项 b,求得输出图片中的一个值。
这个 5x5x3 的输入图片加了全零填充,使用 3x3x3 的卷积核,所有 27 个点与对应的待优化参数相乘,乘积求和再加上偏置 b 得到输出图片中的一个值 6。

针对上面这幅彩色图片,用 conv2d 函数实现可以表示为:
一次输入 batch 张图片,输入图片的分辨率是 5x5,是 3 通道的,卷积核是3x3x3,一共有 16 个卷积核,这样输出的深度就是 16,核滑动横向步长是 1,纵
向步长也是 1,padding 选择 same,保证输出是 5x5 分辨率。由于一共用了 16个卷积核,所以输出图片是 5x5x16。
上面讲到卷积,用来提取图像的特征值,但对于有些图片来说,即使使用卷积,特征值也会很多。所以下面简单介绍一下减少特征值的方法
池化 Pooling
池化用于减少特征数量
最大池化可提取图片纹理,均值池化可保留背景特征。

如图,最大池化(max)为以2*2的矩阵在原图片中选取最大的点,如1 1 5 6中最大的为6,依次遍历整个图片,得到结果。
均值池化和最大池化相同,不过选取的是4个的均值。

Tensorflow 给出了计算池化的函数。最大池化用 tf.nn.max_pool 函数,平均池化用 tf.nn.avg_pool 函数。
函数中要给出四个信息,对输入的描述、对池化核的描述、对池化核滑动步长的描述和是否使用 padding。
1)对输入的描述:给出一次输入 batch 张图片、行列分辨率、输入通道的个数。
2)对池化核的描述:只描述行分辨率和列分辨率,第一个和最后一个参数固定是 1。
3)对池化核滑动步长的描述:只描述横向滑动步长和纵向滑动步长,第一个和最后一个参数固定是 1。
4)是否使用 padding:padding 可以是使用零填充 SAME 或者不使用零填充 VALID。
舍弃 Dropout

在神经网络训练过程中,为了减少过多参数常使用 dropout 的方法,将一部
分神经元按照一定概率从神经网络中舍弃。这种舍弃是临时性的,仅在训练时舍
弃一些神经元;在使用神经网络时,会把所有的神经元恢复到神经网络中。比如上面这张图,在训练时一些神经元不参加神经网络计算了。Dropout 可以有效减少过拟合。
Tensorflow 提供的 dropout 的函数:用 tf.nn.dropout 函数。第一个参数链接上一层的输出,第二个参数给出神经元舍弃的概率。
在实际应用中,常常在前向传播构建神经网络时使用 dropout 来减小过拟合 加快模型的训练速度。
dropout 一般会放到全连接网络中。如果在训练参数的过程中,输出=tf.nn.dropout(上层输出,暂时舍弃神经元的概率), 这样就有指定概率的神经
元被随机置零,置零的神经元不参加当前轮的参数优化。
√卷积 NN:借助卷积核(kernel)提取特征后,送入全连接网络。

卷积神经网络可以认为由两部分组成,一部分是对输入图片进行特征提取,
另一部分就是全连接网络,只不过喂入全连接网络的不再是原始图片,而是经过若干次卷积、激活和池化后的特征信息。
卷积神经网络从诞生到现在,已经出现了许多经典网络结构,比如 Lenet-5、Alenet、VGGNet、GoogleNet 和 ResNet 等。每一种网络结构都是以卷积、激活、池化、全连接这四种操作为基础进行扩展。
注:本文章通过观看北京大学曹健老师的Tensorflow视频,笔记总结而来的。


















