原文链接:http://wuchong.me/blog/2016/05/04/flink-internal-how-to-build-streamgraph/
继上文Flink 原理与实现:架构和拓扑概览中介绍了Flink的四层执行图模型,本文将主要介绍 Flink 是如何根据用户用Stream API编写的程序,构造出一个代表拓扑结构的StreamGraph的。
注:本文比较偏源码分析,所有代码都是基于 flink-1.0.x 版本,建议在阅读本文前先对Stream API有个了解,详见官方文档。
StreamGraph 相关的代码主要在 org.apache.flink.streaming.api.graph 包中。构造StreamGraph的入口函数是 StreamGraphGenerator.generate(env, transformations)。该函数会由触发程序执行的方法StreamExecutionEnvironment.execute()调用到。也就是说 StreamGraph 是在 Client 端构造的,这也意味着我们可以在本地通过调试观察 StreamGraph 的构造过程。
Transformation
StreamGraphGenerator.generate 的一个关键的参数是 List<StreamTransformation<?>>。StreamTransformation代表了从一个或多个DataStream生成新DataStream的操作。DataStream的底层其实就是一个 StreamTransformation,描述了这个DataStream是怎么来的。
StreamTransformation的类图如下图所示:
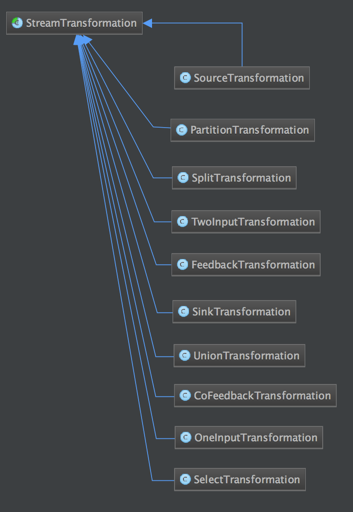
DataStream 上常见的 transformation 有 map、flatmap、filter等(见DataStream Transformation了解更多)。这些transformation会构造出一棵 StreamTransformation 树,通过这棵树转换成 StreamGraph。比如 DataStream.map源码如下,其中SingleOutputStreamOperator为DataStream的子类:
public <R> SingleOutputStreamOperator<R> map(MapFunction<T, R> mapper) {
TypeInformation<R> outType = TypeExtractor.getMapReturnTypes(clean(mapper), getType(),
Utils.getCallLocationName(), true);
return transform("Map", outType, new StreamMap<>(clean(mapper)));
}
public <R> SingleOutputStreamOperator<R> transform(String operatorName, TypeInformation<R> outTypeInfo, OneInputStreamOperator<T, R> operator) {
transformation.getOutputType();
OneInputTransformation<T, R> resultTransform = new OneInputTransformation<>(
this.transformation,
operatorName,
operator,
outTypeInfo,
environment.getParallelism());
@SuppressWarnings({ "unchecked", "rawtypes" })
SingleOutputStreamOperator<R> returnStream = new SingleOutputStreamOperator(environment, resultTransform);
getExecutionEnvironment().addOperator(resultTransform);
return returnStream;
}
|
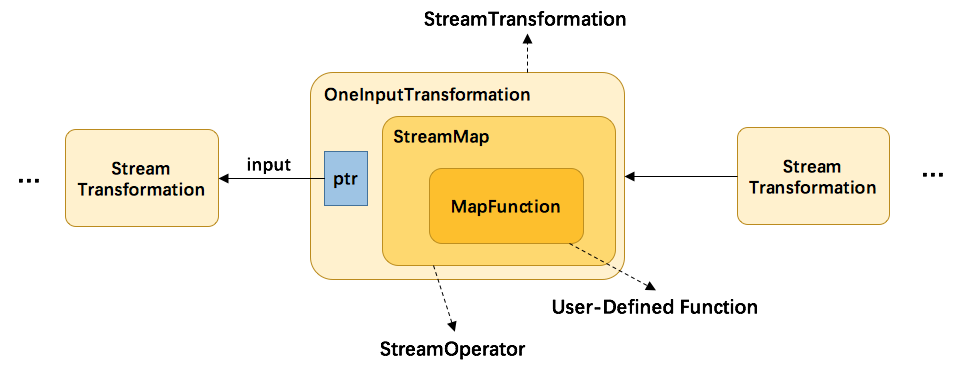
从上方代码可以了解到,map转换将用户自定义的函数MapFunction包装到StreamMap这个Operator中,再将StreamMap包装到OneInputTransformation,最后该transformation存到env中,当调用env.execute时,遍历其中的transformation集合构造出StreamGraph。其分层实现如下图所示:
另外,并不是每一个 StreamTransformation 都会转换成 runtime 层中物理操作。有一些只是逻辑概念,比如 union、split/select、partition等。如下图所示的转换树,在运行时会优化成下方的操作图。

union、split/select、partition中的信息会被写入到 Source –> Map 的边中。通过源码也可以发现,UnionTransformation,SplitTransformation,SelectTransformation,PartitionTransformation由于不包含具体的操作所以都没有StreamOperator成员变量,而其他StreamTransformation的子类基本上都有。
StreamOperator
DataStream 上的每一个 Transformation 都对应了一个 StreamOperator,StreamOperator是运行时的具体实现,会决定UDF(User-Defined Funtion)的调用方式。下图所示为 StreamOperator 的类图(点击查看大图):
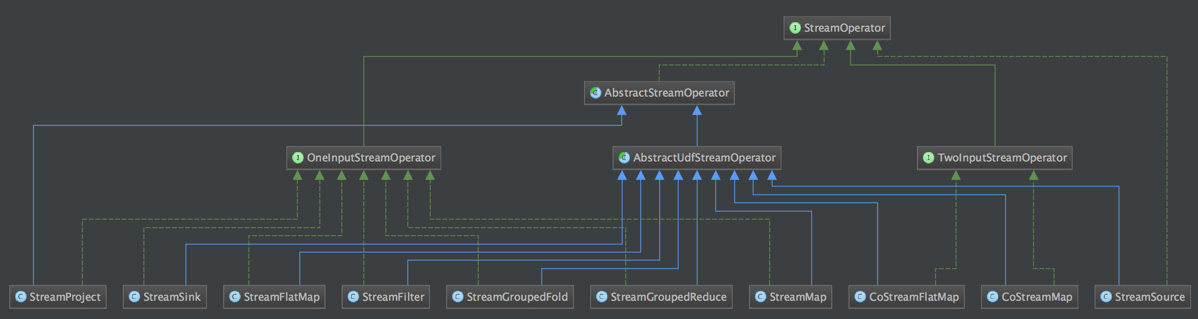
可以发现,所有实现类都继承了AbstractStreamOperator。另外除了 project 操作,其他所有可以执行UDF代码的实现类都继承自AbstractUdfStreamOperator,该类是封装了UDF的StreamOperator。UDF就是实现了Function接口的类,如MapFunction,FilterFunction。
生成 StreamGraph 的源码分析
我们通过在DataStream上做了一系列的转换(map、filter等)得到了StreamTransformation集合,然后通过StreamGraphGenerator.generate获得StreamGraph,该方法的源码如下:
public static StreamGraph generate(StreamExecutionEnvironment env, List<StreamTransformation<?>> transformations) {
return new StreamGraphGenerator(env).generateInternal(transformations);
}
private StreamGraph generateInternal(List<StreamTransformation<?>> transformations) {
for (StreamTransformation<?> transformation: transformations) {
transform(transformation);
}
return streamGraph;
}
private Collection<Integer> transform(StreamTransformation<?> transform) {
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
LOG.debug("Transforming " + transform);
transform.getOutputType();
Collection<Integer> transformedIds;
if (transform instanceof OneInputTransformation<?, ?>) {
transformedIds = transformOnInputTransform((OneInputTransformation<?, ?>) transform);
} else if (transform instanceof TwoInputTransformation<?, ?, ?>) {
transformedIds = transformTwoInputTransform((TwoInputTransformation<?, ?, ?>) transform);
} else if (transform instanceof SourceTransformation<?>) {
transformedIds = transformSource((SourceTransformation<?>) transform);
} else if (transform instanceof SinkTransformation<?>) {
transformedIds = transformSink((SinkTransformation<?>) transform);
} else if (transform instanceof UnionTransformation<?>) {
transformedIds = transformUnion((UnionTransformation<?>) transform);
} else if (transform instanceof SplitTransformation<?>) {
transformedIds = transformSplit((SplitTransformation<?>) transform);
} else if (transform instanceof SelectTransformation<?>) {
transformedIds = transformSelect((SelectTransformation<?>) transform);
} else if (transform instanceof FeedbackTransformation<?>) {
transformedIds = transformFeedback((FeedbackTransformation<?>) transform);
} else if (transform instanceof CoFeedbackTransformation<?>) {
transformedIds = transformCoFeedback((CoFeedbackTransformation<?>) transform);
} else if (transform instanceof PartitionTransformation<?>) {
transformedIds = transformPartition((PartitionTransformation<?>) transform);
} else {
throw new IllegalStateException("Unknown transformation: " + transform);
}
if (!alreadyTransformed.containsKey(transform)) {
alreadyTransformed.put(transform, transformedIds);
}
if (transform.getBufferTimeout() > 0) {
streamGraph.setBufferTimeout(transform.getId(), transform.getBufferTimeout());
}
if (transform.getUid() != null) {
streamGraph.setTransformationId(transform.getId(), transform.getUid());
}
return transformedIds;
}
|
最终都会调用 transformXXX 来对具体的StreamTransformation进行转换。我们可以看下transformOnInputTransform(transform)的实现:
private <IN, OUT> Collection<Integer> transformOnInputTransform(OneInputTransformation<IN, OUT> transform) {
Collection<Integer> inputIds = transform(transform.getInput());
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
String slotSharingGroup = determineSlotSharingGroup(transform.getSlotSharingGroup(), inputIds);
streamGraph.addOperator(transform.getId(),
slotSharingGroup,
transform.getOperator(),
transform.getInputType(),
transform.getOutputType(),
transform.getName());
if (transform.getStateKeySelector() != null) {
TypeSerializer<?> keySerializer = transform.getStateKeyType().createSerializer(env.getConfig());
streamGraph.setOneInputStateKey(transform.getId(), transform.getStateKeySelector(), keySerializer);
}
streamGraph.setParallelism(transform.getId(), transform.getParallelism());
for (Integer inputId: inputIds) {
streamGraph.addEdge(inputId, transform.getId(), 0);
}
return Collections.singleton(transform.getId());
}
|
该函数首先会对该transform的上游transform进行递归转换,确保上游的都已经完成了转化。然后通过transform构造出StreamNode,最后与上游的transform进行连接,构造出StreamNode。
最后再来看下对逻辑转换(partition、union等)的处理,如下是transformPartition函数的源码:
private <T> Collection<Integer> transformPartition(PartitionTransformation<T> partition) {
StreamTransformation<T> input = partition.getInput();
List<Integer> resultIds = new ArrayList<>();
Collection<Integer> transformedIds = transform(input);
for (Integer transformedId: transformedIds) {
int virtualId = StreamTransformation.getNewNodeId();
streamGraph.addVirtualPartitionNode(transformedId, virtualId, partition.getPartitioner());
resultIds.add(virtualId);
}
return resultIds;
}
|
对partition的转换没有生成具体的StreamNode和StreamEdge,而是添加一个虚节点。当partition的下游transform(如map)添加edge时(调用StreamGraph.addEdge),会把partition信息写入到edge中。如StreamGraph.addEdgeInternal所示:
public void addEdge(Integer upStreamVertexID, Integer downStreamVertexID, int typeNumber) {
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, null, new ArrayList<String>());
}
private void addEdgeInternal(Integer upStreamVertexID,
Integer downStreamVertexID,
int typeNumber,
StreamPartitioner<?> partitioner,
List<String> outputNames) {
if (virtualSelectNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualSelectNodes.get(virtualId).f0;
if (outputNames.isEmpty()) {
outputNames = virtualSelectNodes.get(virtualId).f1;
}
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, outputNames);
}
else if (virtuaPartitionNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtuaPartitionNodes.get(virtualId).f0;
if (partitioner == null) {
partitioner = virtuaPartitionNodes.get(virtualId).f1;
}
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, outputNames);
} else {
StreamNode upstreamNode = getStreamNode(upStreamVertexID);
StreamNode downstreamNode = getStreamNode(downStreamVertexID);
if (partitioner == null && upstreamNode.getParallelism() == downstreamNode.getParallelism()) {
partitioner = new ForwardPartitioner<Object>();
} else if (partitioner == null) {
partitioner = new RebalancePartitioner<Object>();
}
if (partitioner instanceof ForwardPartitioner) {
if (upstreamNode.getParallelism() != downstreamNode.getParallelism()) {
throw new UnsupportedOperationException("Forward partitioning does not allow " +
"change of parallelism. Upstream operation: " + upstreamNode + " parallelism: " + upstreamNode.getParallelism() +
", downstream operation: " + downstreamNode + " parallelism: " + downstreamNode.getParallelism() +
" You must use another partitioning strategy, such as broadcast, rebalance, shuffle or global.");
}
}
StreamEdge edge = new StreamEdge(upstreamNode, downstreamNode, typeNumber, outputNames, partitioner);
getStreamNode(edge.getSourceId()).addOutEdge(edge);
getStreamNode(edge.getTargetId()).addInEdge(edge);
}
}
|
实例讲解
如下程序,是一个从 Source 中按行切分成单词并过滤输出的简单流程序,其中包含了逻辑转换:随机分区shuffle。我们会分析该程序是如何生成StreamGraph的。
DataStream<String> text = env.socketTextStream(hostName, port);
text.flatMap(new LineSplitter()).shuffle().filter(new HelloFilter()).print();
|
首先会在env中生成一棵transformation树,用List<StreamTransformation<?>>保存。其结构图如下:

其中符号*为input指针,指向上游的transformation,从而形成了一棵transformation树。然后,通过调用StreamGraphGenerator.generate(env, transformations)来生成StreamGraph。自底向上递归调用每一个transformation,也就是说处理顺序是Source->FlatMap->Shuffle->Filter->Sink。
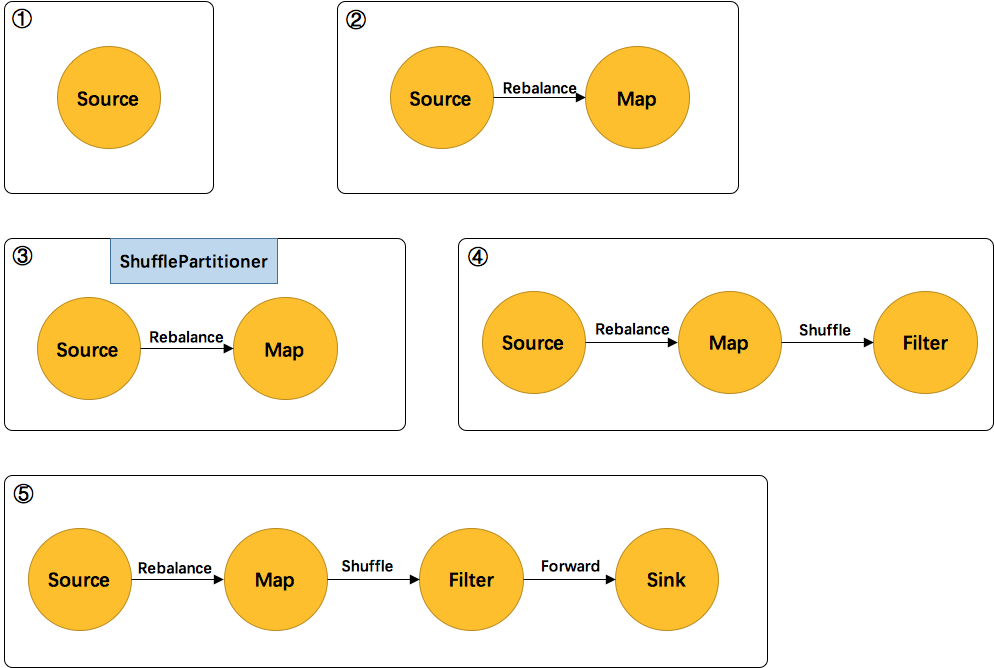
如上图所示:
首先处理的Source,生成了Source的StreamNode。
然后处理的FlatMap,生成了FlatMap的StreamNode,并生成StreamEdge连接上游Source和FlatMap。由于上下游的并发度不一样(1:4),所以此处是Rebalance分区。
然后处理的Shuffle,由于是逻辑转换,并不会生成实际的节点。将partitioner信息暂存在virtuaPartitionNodes中。
在处理Filter时,生成了Filter的StreamNode。发现上游是shuffle,找到shuffle的上游FlatMap,创建StreamEdge与Filter相连。并把ShufflePartitioner的信息写到StreamEdge中。
最后处理Sink,创建Sink的StreamNode,并生成StreamEdge与上游Filter相连。由于上下游并发度一样(4:4),所以此处选择 Forward 分区。
最后可以通过 UI可视化 来观察得到的 StreamGraph。

总结
本文主要介绍了 Stream API 中 Transformation 和 Operator 的概念,以及如何根据Stream API编写的程序,构造出一个代表拓扑结构的StreamGraph的。本文的源码分析涉及到较多代码,如果有兴趣建议结合完整源码进行学习。下一篇文章将介绍 StreamGraph 如何转换成 JobGraph 的,其中设计到了图优化的技巧。





















