
概述
五链指的是五个关卡,这五个关卡正好处在数据流量的必经之路上,我们就是通过这五个关卡来控制报文。这五个关卡就处在tcp/ip协议栈里面,而tcp/ip协议线处在内核里面,所以软件防火墙是属于内核空间的功能而不是用户空间的功能。
引申:
软防火墙通过关卡来控制报文的流动,硬件防火墙通过区域来控制报文的流动,无论是关卡还是区域它们的目的都是为了控制报文的流动。
流经防火墙的流量无非是以下三种情况:
-
目标地址是防火墙,比如我们通过telnet连接防火墙进行管理时。
-
请求防火墙转发报文,目标地址不是防火墙,比如让防火墙充当路由器时。
-
防火墙本身发出来的,源属于防火墙,比如防火墙的接口参与到OSPF路由协议时。
怎样判断一个报文的目的是防火墙本身还是请求让防火墙转发的呢?无论是软件防火墙还是硬件防火墙在这一点上都是相同的,都是查看报文的目的IP来确认,如果目的地址是防火墙本身的接口地址,那就说明此报文就是给防火墙本身的,如果报文目的IP不是防火墙本身的,那就说明此报文是防火墙转发的。
我们只要在三种流量的必经之地设定关卡就能有效的控制流量,那么上述三种流量分别流经哪些地方?我们又该怎样设置关卡呢?且看我慢慢道来:
假如说一个报文的目的地址就是防火墙本身,那然后呢?下一步直接由网络层向传输层提交此报文,我们只要在网络层和传输层之间放置一个关卡,这样所有到达防火墙本身的报文必定会流过此关卡,我们给此关卡起一个名字:INPUT。
假如说一个报文的目的地址不是防火墙本身接口的地址,那然后呢?如果一个报文的目的地址不是防火墙本身,肯定不会向传输层提交了,而是应该转发出去,向哪里转呢?路由表当中会有指示此报文下一步的出接口,所以我们只要在网络层横向面与出接口之间设立一个关卡,这样所有通过防火墙转发的报文必定会流过此关卡,我们给此关卡起一个名字:FORWARD。
那么对于防火墙主动向外发送的流量我们应该在什么地方设置关卡呢?我们还是先要分析一下该流量的流动路径,防火墙本身向外发送时封装到网络层时我们才能通过其源IP地址判断此报文是防火墙本身向外发送的,所以这个关卡应该设置在网络层之后(路由之后,因为路由就在网络层),我们也给此关卡起一外名字:OUTPUT。
还有两个关卡是PREROUTING(路由前)和POSTROUTING(路由后),它们有什么作用呢?
它们主要的作用就是做NAT,NAT分为两种源NAT和目标NAT,路由前适合做目标NAT转换,路由后适应做源NAT转换,为什么?我们一个一个说:
源地址转换应该发生在什么地方?在forward位置上吗?还是在postrouting?应该是从postrouting,为什么?因为可能我们有多个网卡,forward这个位置上我们仅仅是知道了这个报文是要转发的,但是要对这个报文重新封装源IP的时候,需要获取源网卡的IP地址,但是很有可能我们有多个网卡,究竟使用哪一个网卡现在还不知道,所以即便在FORWARD这个位置上想转换源IP地址也是没有能力转换的。而POSTROUTING位于网卡的缓冲队列当中(每个网卡都有一个消息队列),位于网卡内部,所以说POSTRUOTING有能力去转换源IP地址。
目标地址转换使用PREROUTING。客户端通过防火墙的公网IP访问内网的服务器,防火墙需要做目标地址转换,将,将报文的目标地址:防火墙公网IP转换为内网胳IP,这个转换一定要在进入网络层之间,也就是刚进入网卡的时候就要进行转换,为什么?因为如果不及时转换的话,报文就会通过网络层检查后发现是访问防火墙本身的,向传输层提交,而传输层却没有打开报文当中对应的端口就会进行丢弃。经过PREROUTING转换之后防火墙就不会把此报文当成是访问自己本身的访问向传输层提交了,而是转发出去。
总结:
路由前是为了做目标地址转换,晚了不行,晚上就直接向上交付了。
路由后是为了做源地址转换,早了不行,早了还不知道发向哪个网卡。
注意:
很多人在学习五链的时候很容易把五链的INPUT当成是一个网卡,然后OUTPUT当成另外一个网卡,或者,把PREROUTING当成一个网卡,把POSTROUTING当成是另外一个网卡,这种想法是不对的,因为五链不存在于任何硬件(比如网卡)当中,五链是在内核当中的,所有的网卡都会使用一套五链,不管有多少网卡,无论数据从哪一个网卡进入主机都得经过PREROUTING,同样,无论数据从哪一个网卡出去都得经过POSTROUTING。
图解四表五链和顺序
五链指的是五个数据必定会流经的“地点”,而四表指的是四种功能。真是奇怪,为什么要把关卡称做是链?,为什么把功能称为表,就老老实实的叫做“五关卡四功能”不行吗?这样理解起来就容易多了。
四表就是四个功能:过滤功能、地址转换功能、修改报文功能、RAW功能(极少使用,不讲)
1. 过滤功能:
过滤功能只能在三个关卡实现:INPUT、OUTPUT、FORWORD。
只有三个关卡能够实现过滤功能,分别是INPUT、FORWARD、OUTPUT,原因是因为这三个位置的报文都是比较“稳定的”,所以在这三个地方可以实现过滤的功能,而prerouting和postrouting这两个位置可能发生NAT,报文极不稳定,容易“认错”报文,所以不能使用过滤的功能。
比如通过INPUT,我们可以实现报文目标地址是自己,源是某个网段的主机拒绝通过。
比如通过FORWARD,我们可以拒绝报文目标是某个主机的报文通过。
比如通过OUTPUT,我们可以拒绝本机icmp 的reply报文通过,这样外面的主机就无法ping通我们了。
2. NAT
NAT的功能就简单了,PREROUTING和POSTROUTING就专门为源NAT和目标NAT准备的,此外,还有OUTPUT。 对于PREROUTING和POSTROUTING为什么适合地址转换,我们在上文已经说过了,但是OUTPUT为什么适合NAT转换呢?
OUTPUT发生在路由后,所以在进行路由封装的时候随便把地址转换了这就节省了POSTROUTING的事了。
3. mangle
在所有的地方都可以,mangle就是修改报文某个字段,比如修改报文的TTL。
4. RAW
连接追踪,NAT里面有连接追踪的机制,
图示
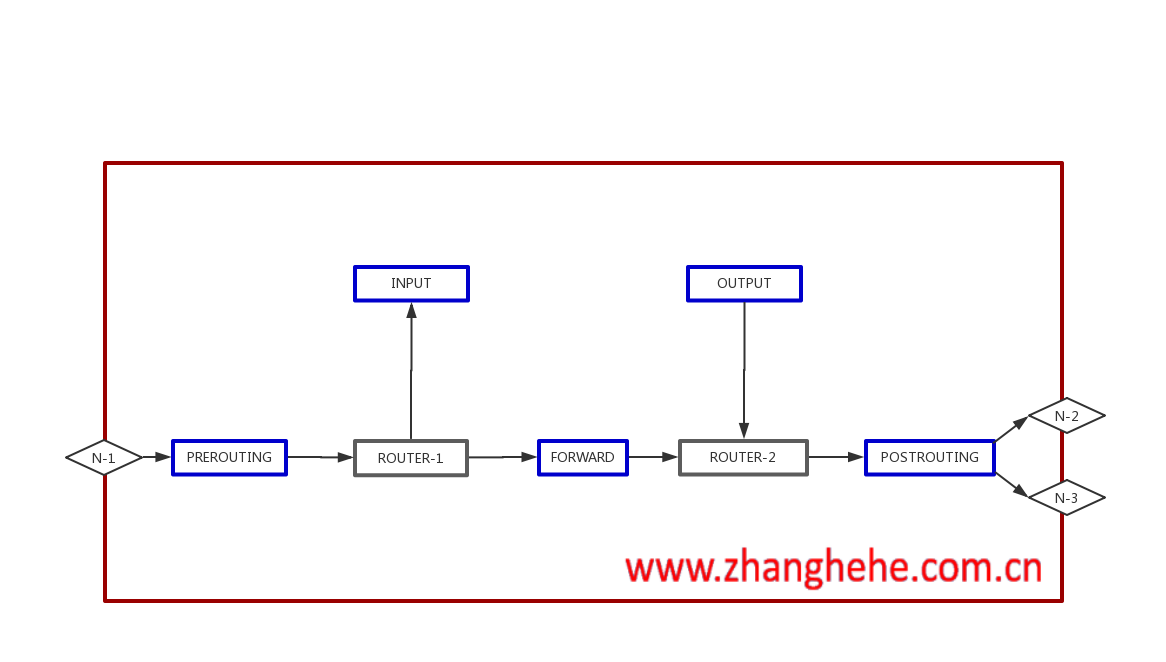
路由1决定是否要进行转发,路由2决定要转发给哪一个网卡
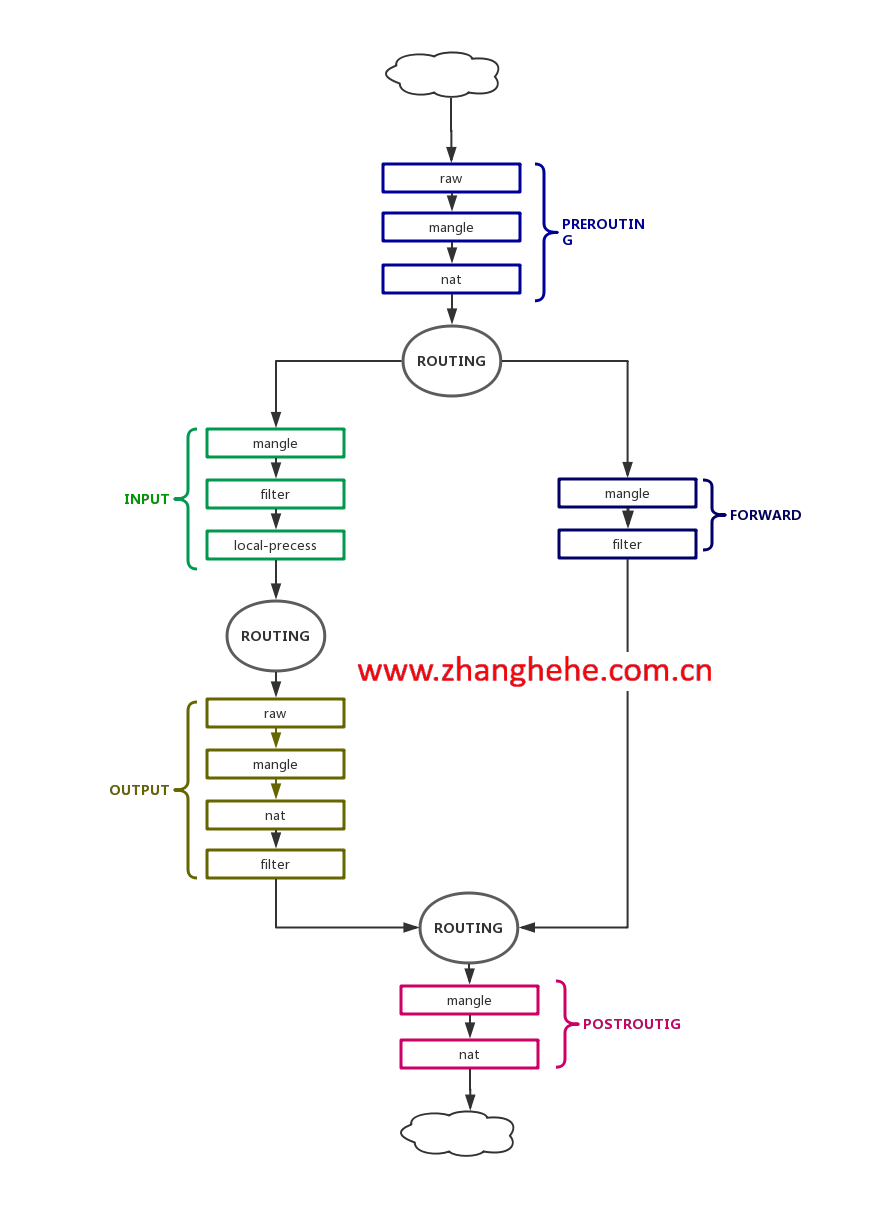
上述图都是根据自己的理解画的,如果错误,概不负责!
判断练习
- 拒绝本机访问百度的请求
如何判断呢?首先从拒绝关键字“拒绝”得知是是使用过滤的功能,而filter可以实现的位置有三个:INPUT、FORWARD、OUTPUT,根据“拒绝本机”得知方向是很明显是在OUTPUT关卡上,别忘记了,数据包是一去一回的,我们也可以在INPUT上做,但最好是在OUTPUT上做。
- 拒绝内网某个主机访问百度。
明显是filter功能。
INPUT是到防火墙本身的,所以INPUT不符合条件。
OUTPUT是防火墙本身向外发送的,所以OUTPUT也不符合条件。
FORWARD正好。
- 给内网某个网段做源-NAT,怎么做?
NAT只能在三个地方做,PREROUING、POSTROUTING、OUTPUT,而源NAT只能在POSTROUTING上做。
- 拒绝访问防火墙本身的telnet,应该在哪里做规则?
filter,在INPUT上,因为流量只会经过INPUT,而不会经过FORWARD和OUTPUT
TCP/IP iptables规则说明
添加规则时的考量点:
(1)要实现哪种功能:判断添加到哪个表上;
(2)报文流经的路径:判断添加到哪个链上;
链:链上的规则次序,即为检查的次序;因此,隐含一定的应用法则:
(1)同类规则(访问同一应用) ,匹配范围小的放上面;
(2)不同类的规则(访问不同应用) ,匹配到报文频率较大的放在上面;
(3)将那些可由一条规则描述的多个规则合并起来;
(4)设置默认策略;
NOTE:iptables默认是黑名单,黑名单不安全,我们一定要使用白名单!
iptables的链分为:内置链和自定义链
内置链:对应着五个勾子函数
自定义链:用于内置链的扩展和补充,可以实现更灵活的规则管理机制。
自定义的链是没有勾子函数的,需要引用内置链的勾子函数,为什么需要自定义链呢?比如有我们在filter表当中定义了很多的规则,有ssh相关的,有web相关的,看起来比较混乱,这时就可以通过自定义链定义一个WEB链,将WEB相关的规则定义在这里面,ssh链同理,这样的话我们想要删除ssh相关的规则,直接把ssh链删除即可。
格式
iptables的格式在man文档里面有,选项部分是这个样子的,如下所示:
SYNOPSIS
iptables [-t table] {-A|-C|-D} chain rule-specification
ip6tables [-t table] {-A|-C|-D} chain rule-specification
iptables [-t table] -I chain [rulenum] rule-specification
iptables [-t table] -R chain rulenum rule-specification
iptables [-t table] -D chain rulenum
iptables [-t table] -S [chain [rulenum]]
iptables [-t table] {-F|-L|-Z} [chain [rulenum]] [options...]
iptables [-t table] -N chain
iptables [-t table] -X [chain]
iptables [-t table] -P chain target
iptables [-t table] -E old-chain-name new-chain-name
rule-specification = [matches...] [target]
match = -m matchname [per-match-options]
target = -j targetname [per-target-options]

查看
虽然man iptalbes的解释看起来对我们中国人非常的不友好,完全看不懂呀!但是还是要认真看,争取能看明白。
上述选项当中我们看到iptables命令后是通过-t选项跟的是表的名字,即四种功能,按照生效顺序分别是raw、mangle、nat、filter,这个表名用中括号括了起来表示可以省略,省略的话默认就是filter表,为什么?因为我们用iptables是用来制定防火墙规则的,而防火墙规则无非也就是放行什么、丢弃什么,而放行和丢弃就是filter的功能,我们大多数情况下都是在filter表上制定规则,所以默认就是filter表。
在表的后面就是大写的选项了,如上述所示,如I/D/S/A……,这些选项是干啥的?其实就是一些查看 、添加、删除、重名名啥的,我们慢慢来讲,先来看看大写的-L选项是用来做啥子的。
List all rules in the selected chain. If no chain is selected, all chains are listed. Like every other iptables com‐ mand, it applies to the specified table (filter is the default), so NAT rules get listed by iptables -t nat -n -L
Please note that it is often used with the -n option, in order to avoid long reverse DNS lookups. It is legal to specify the -Z (zero) option as well, in which case the chain(s) will be atomically listed and zeroed. The exact out‐ put is affected by the other arguments given. The exact rules are suppressed until you use iptables -L -v
iptables [-t table] {-F|-L|-Z} [chain [rulenum]] [options...]
//-L(list)是用来查看的,等同于iptables -t filter -L,默认查看的是filter链,如下
[root@N2 ~]# iptables -L #
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
//查看还可以再具体一点,查看filter表上的INPUT链上的规则
[root@N2 ~]# iptables -t filter -L INPUT
[root@N2 ~]# iptables -nL
[root@N2 ~]# iptables -nL --line-numbers
[root@N2 ~]# iptables -vnL --line-numbers
查看:
-L:list,列出指定链上的所有规则
-v:verbose,详细信息,-v,-vv,-vvv,用一个v即可,会出现一个计数器,下文当中有解释
-x:exactly,显示计数结果的精确值,不执行单位换算
--line-numbers:显示规则的序号
NOTE:
-L选项与其辅助选项使用时-L要放在最后,除了--line-numbers
清空
清空分为:清空计数器(-Z)和清空规则(-F)
iptables [-t table] {-F|-L|-Z} [chain [rulenum]] [options...]
讲完了查看和其辅助命令之后,再看-Z选项,这个-Z选项是用来做啥子的呢?
List all rules in the selected chain. If no chain is selected, all chains are listed. Like every other iptables com‐ mand, it applies to the specified table (filter is the default), so NAT rules get listed by iptables -t nat -n -L
Please note that it is often used with the -n option, in order to avoid long reverse DNS lookups. It is legal to specify the -Z (zero) option as well, in which case the chain(s) will be atomically listed and zeroed. The exact out‐ put is affected by the other arguments given. The exact rules are suppressed until you use iptables -L -v
第二段已经说的很清楚了,就是用来清零的?清什么零的?用-v选项出现一个计数器,就是清这个计数器的零的,如下所示:
[root@N2 ~]# iptables -nvL OUTPUT
Chain OUTPUT (policy ACCEPT 349 packets, 79920 bytes)
pkts bytes target prot opt in out source destination
349 79920 OUTPUT_direct all -- * * 0.0.0.0/0 0.0.0.0/0
//可以指定具体的链
[root@N2 ~]# iptables -nvL -Z OUTPUT
//甚至可以指定具体链当中的规则序号,前提是你要通过--line-numbers将序号显示出来
[root@N2 ~]# iptables -vL OUTPUT 1
pkts:命中此规则的次数
bytes:命中此规则的报文一共的大小
target:执行的动作,是允许了还是拒绝了
port:即端口
opt:选项
in:数据的流入端口
out:数据包的出接口
soucre:源地址
destination:目标地址
NOTE:-L -Z -F的使用方法是一样的,后面都可以指定具体的链、规则的序号,至于辅助的命令只有-L有,-F和-Z没有。
链管理
链管理包括新建一个新建/删除/重名名/设置链的默认策略
iptables [-t table] -N chain #新建
iptables [-t table] -X [chain] #删除
iptables [-t table] -E old-chain-name new-chain-name #重名命,被引用时无法重命名
iptables [-t table] -P chain target
note:
链想要删除需要满足三个条件:
1、链是空的,里面没有规则;
2、没有被引用,即引用计数为0
3、必须是自定义的,默认的五链是无法删除的
默认的动作有三种;
1、DROP(丢弃,最常用)
2、ACCEPT(允许)
3、REJECT(挑衅,拒绝之后并告诉别人被拒绝)
规则管理
iptables [-t table] {-A|-C|-D} chain rule-specification
iptables [-t table] -I chain [rulenum] rule-specification
iptables [-t table] -R chain rulenum rule-specification
iptables [-t table] -D chain rulenum
iptables [-t table] -S [chain [rulenum]]
-A:追加规则
-I(大):插入规则,要指明位置,省略时表示第一条
-D:删除规则,要不指明序号,要不指明规则本身,指明规则本身还需要重新写一遍,不如指明序号删除方便
-R:replace,替换指定链上的指定规则
-F和-Z前面都已经说过了
-S:显示规则是如何添加的
//当前为空
[root@N2 ~]# iptables -L INPUT
Chain INPUT (policy ACCEPT)
target prot opt source destination
//添加一条简单的规则
[root@N2 ~]# iptables -t filter -A INPUT -s 192.168.80.3 -j ACCEPT
//查看规则
[root@N2 ~]# iptables -nL INPUT --line-numbers
Chain INPUT (policy ACCEPT)
num target prot opt source destination
1 ACCEPT all -- 192.168.80.3 0.0.0.0/0
//替换INPUT链上的第一条规则
[root@N2 ~]# iptables -R INPUT 1 -s 192.168.80.4 -j ACCEPT
//新插入一条到第一条的上面
[root@N2 ~]# iptables -I INPUT 1 -s 192.168.80.5 -j ACCEPT
[root@N2 ~]# iptables -L INPUT
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT all -- 192.168.80.5 anywhere
ACCEPT all -- 192.168.80.4 anywhere
//删除INPUT链的第二条
[root@N2 ~]# iptables -D INPUT 2
[root@N2 ~]# iptables -L INPUT
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT all -- 192.168.80.5 anywhere
//显示第一条是如何添加的
[root@N2 ~]# iptables -L INPUT
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT all -- 192.168.80.5 anywhere
[root@N2 ~]# iptables -S INPUT 1
-A INPUT -s 192.168.80.5/32 -j ACCEPT
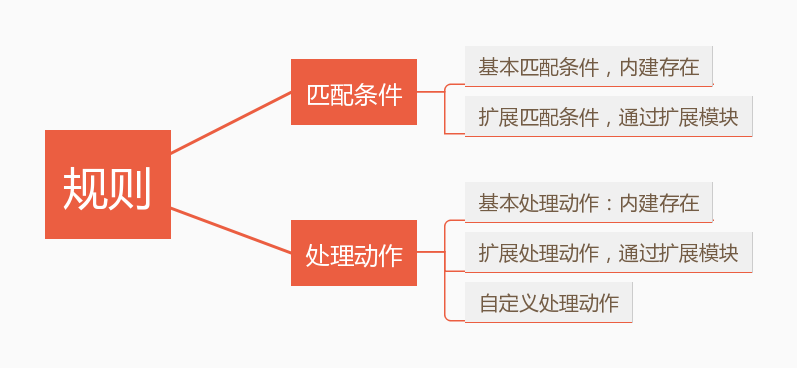
rule-specification = [matches...] [target] #规则=匹配条件+动作
match = -m matchname [per-match-options]
target = -j targetname [per-target-options]
匹配条件分为:
1、基础匹配条件:无需调用 模块
2、扩展匹配条件:需调用或手动装载模块
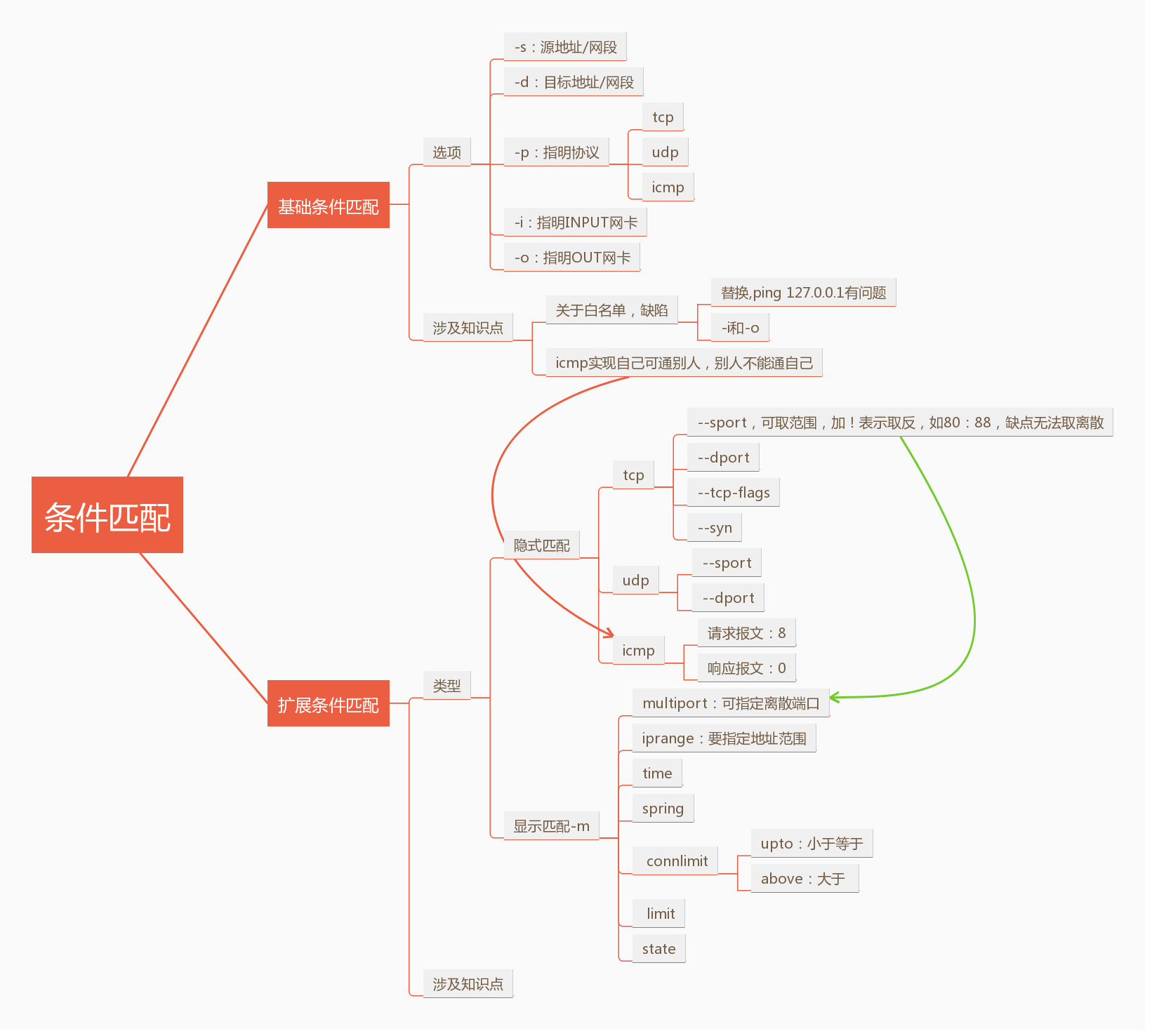
基础匹配
-s:匹配源地址,可以是具体的地址、也可以是网段,还可以使用!取反。
-d:匹配目标地址,可以是地址和网段,也可以使用!取反。0.0.0.0表示所有
-p:匹配协议, tcp, udp, icmp,
-i:数据报文流入的接口,通常只用于input、FORWARD和PREROUTING
-o:数据报文流出的接口:通常用于OUTPUT、FORWARD和POSTROUTING
NOTE:
你发现了没有,基础匹配的功能并不是特别全面,为什么?里面没有端口匹配,端口匹配是属于扩展匹配里面的功能。
实战与改进:假设当前主机是192.168.80.59(在没开启状态测试的情况下)
//当前无任何一条规则,查看为空
[root@N2 ~]# iptables -vnL
//源主机到目标主机的所有tcp连接(在INPUT和OUTPUT都要设置,最后再设置默认策略,如果你先设置完默认策略自己的终端就无法连接了
iptables -A INPUT -s 192.168.80.6 -d 192.168.80.59/32 -p tcp -j ACCEPT
iptables -A OUTPUT -s 192.168.80.59 -d 192.168.80.6/32 -p tcp -j ACCEPT
iptables -P INPUT DROP
iptables -P OUTPUT DROP
[root@N2 ~]# iptables -vnL
Chain INPUT (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
56 3696 ACCEPT tcp -- * * 192.168.80.6 192.168.80.59
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
31 3028 ACCEPT tcp -- * * 192.168.80.59 192.168.80.6
上述做法是白名单,我们在实际的生产环境当中就要使用白名单,黑名单太不安全了。但是白名单有一些缺点,什么缺点呢?下文当中有阐述。
这样做的隐患:误操作
一旦有人不小心清空了所有的规则:iptables -F,那么就只剩默认规则,而INPUT和OUTPUT的默认规则就都是DROP了,终端也无法连接了!
怎样解决呢?(多种解决办法)
思路1:写一个定时任务,每隔一段时间就重启防火墙服务,这样当前的规则就会被配置文件里面的规则给“冲刷”掉。
思路2:默认规则我们不动,还是ACCEPT,我们在默认规则的前面加一个REJECT或DROP,后续的所有的规则不要在此规则的后面,而是要放到前面(再次添加规则的时候不要用-A而是要用-I 指定位置),这样,一旦前面的规则无法匹配,到此规则之后就会拒绝,类似于默认策略,如果有人误操作了也不要紧,因为真正的默认策略是ACCEPT,终端 仍然可以登陆,演示一下,还是上面那个例子,如下所示:
iptables -A INPUT -s 192.168.80.6 -d 192.168.80.59/32 -p tcp -j ACCEPT
iptables -A OUTPUT -s 192.168.80.59 -d 192.168.80.6/32 -p tcp -j ACCEPT
iptables -A INPUT -j REJECT
iptables -A OUTPUT -j REJECT
iptables -P INPUT ACCEPT
iptables -P OUTPUT ACCEPT
[root@N2 ~]# iptables -vnL
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
34 2244 ACCEPT tcp -- * * 192.168.80.6 192.168.80.59
0 0 REJECT all -- * * 0.0.0.0/0 0.0.0.0/0 reject-with icmp-port-unreachable
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
22 2264 ACCEPT tcp -- * * 192.168.80.59 192.168.80.6
0 0 REJECT all -- * * 0.0.0.0/0 0.0.0.0/0 reject-with icmp-port-unreachable
NOTE:如上所示,如果我们在本机上用127.0.0.1的话,会有什么现象,当然是被REJECT,因为规则所至。这其实有点过分紧张了,ping 127.0.0.1本身的源地址也必须是127.0.0.1,只要127.0.0.1能ping能,说明tcp/ip协议栈是好的,与网卡没有关系,没有网卡ping 127.0.0.1也一样能ping通,那么就要引用我们下面要讲的-i和-o选项,通过这两个选项就可以避免这种过分紧张的问题。
那最后的-i和-o用到何处呢?
也是用来替换默认策略,防止误操作的,我们也可以通过-i将入站(从某个网卡入站)的最后一条设置为DROP或REJECT,通过-o将出站(从某个网卡出站)的最后一条设置为DROP或REJECT,与上文的例子意思是一样的,例如:
iptables -A INPUT -s 192.168.80.6 -d 192.168.80.59/32 -p tcp -j ACCEPT
iptables -A OUTPUT -s 192.168.80.59 -d 192.168.80.6/32 -p tcp -j ACCEPT
iptables -A INPUT -i eth0 -j REJECT
iptables -A OUTPUT -o eth0 -j REJECT
iptables -P INPUT ACCEPT
iptables -P OUTPUT ACCEPT
[root@N2 ~]# iptables -vnL
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
21 1412 ACCEPT tcp -- * * 192.168.80.6 192.168.80.59
0 0 REJECT all -- eth0 * 0.0.0.0/0 0.0.0.0/0 reject-with icmp-port-unreachable
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
16 2208 ACCEPT tcp -- * * 192.168.80.59 192.168.80.6
0 0 REJECT all -- * eth0 0.0.0.0/0 0.0.0.0/0 reject-with icmp-port-unreachable
关于-p:
在基础匹配当中,-p可指定tcp/udp/icmp/,最常用的就是tcp、因为大多数协议都是tcp,当然有时候也要用到udp,比如DNS,就同时用到了TCP/UDP,此外还有icmp值得说道说道。
icmp是网络层协议,报文的类似有好多,我们最常见的类似有两种:请求和响应。请求的报文类似是8,而响应的报文类型是0,一次完整的ICMP连接由INPUT的请求报文和OUTPUT的响应报文组成。
通过-p icmp我们可以实现,让别人无法ping通自己,而自己可以ping通别人,怎样实现呢?其实很简单,很简单,阻拦INPUT方向的请求报文或阻拦OUT的响应报文都可以,这样不会影响自己ping别人的,因为自己ping的人的时候,OUTPUT出支的请求报文,而INPUT回来的响应报文,下面来演示一下这两种方法:
方法1,当前主机是80.59
iptables -A INPUT -d 192.168.80.59 -p icmp --icmp-type 8 -j DROP
方法2:当前主机是80.59
iptables -A OUTPUT -s 192.168.80.59 -p icmp --icmp-type 0 -j DROP
而且ping 127.0.0.1也是正常的哟!因为ping 127.0.0.1不走网卡,匹配规则不到,直接到默认规则,而默认规则是ACCEPT。
扩展匹配
//扩展匹配man文档
man iptables-extensions
扩展匹配分类:
隐式扩展:隐式扩展就是指在-p选项时指明了协议,不需要手动加载扩展模块,所以但凡使用了-p指明了协议,就表示已经明了要扩展的模块。
显式扩展:必须使用-m 选项指明要调用的扩展模块的扩展机制
NOTE:所有的隐式扩展都可以转化成显式扩展,显式扩展就是指明了具体的细节,比如要放行某某端口,而隐式扩展通过指定协议,比如指定ftp协议,那么ftp相关的端口就自动被放行了,不用被明确指定了。
扩展匹配都要通过加载模块,才可以生效,大部分模块都是自动加载,少部分模块需要手动才能加载。
隐式
-p tcp
--dport m[-n],匹配的目标端口,可以是连续的多个端口
--sport:m[-n],匹配的源端口,可以是连续的多个端口
--tcp-flags
URG PSH PST SYN ACK FIN
例如”—tcp-flags SYN,ACK,FIN,FIN,RST SYN”表示,要检查的标志为SYN/FIN/FIN/RST,其中SYN必须为1,余下的必须为0.再比如“—tcp-flags SYN,ACK,FIN,RST SYN”,可以简写为”--syn”,用于匹配第一次握手。
-p udp
--dport m[-n],匹配的目标端口,可以是连续的多个端口
--sport:m[-n],匹配的源端口,可以是连续的多个端口
-p icmp
-p icmp --icmp-type 8 请求报文
-p icmp --icmp-type 0 响应报文
例如:
//指定具体的端口
iptables -t filter -A INPUT -s 192.168.33.0/24 -p tcp --sport 2235 -j DROP
//取端口范围20一直到80,但无法取离散,想取离散需要通过显式匹配,隐式匹配做不到
iptables -t filter -A INPUT -s 192.168.33.0/24 -p tcp --sport 20:100 -j DROP
//匹配第一次握手,等于于--syn
iptables -A INPUT -s 192.168.33.0/24 -p tcp --tcp-flags SYN,ACK,FIN,RST SYN -j DROP
iptables -A INPUT -s 192.168.33.0/24 -p tcp --syn -j DROP
显式
-m multiport:多端口匹配,一次指定多个离散端口
--source-ports --sport ports{port1 port2}
--destination-ports, --dports
//散列取端口的意义在于多规则合并成一条规则
iptables -A INPUT -s 192.168.33.0/24 -p tcp -m multiport --sports 22,80,445 -j DROP
iptables -A INPUT -s 192.168.33.0/24 -p tcp -m multiport --dports 22,80,445 -j DROP
iprange:ip地址服务
[!] --src-range from [-to]
[!] --dst-range from [-to]
IPTABLES -I INPUT 3 -D 192.168.80.5 -P TCP --DPORT 23 -M IPRANGE --SRC-RANGE 192.168.80.1-192.168.80.10 -J ACCEPT
IPTABLES -I INPUT 3 -D 192.168.80.5 -P TCP --DPORT 23 -M IPRANGE --DST-RANGE 192.168.80.1-192.168.80.10 -J ACCEPT
time 指定时间范围
--datestart YYYY[-MM[-DD[Thh[:mm[:ss]]]]]
--datestop YYYY[-MM[-DD[Thh[:mm[:ss]]]]]
--timestart hh:mm[:ss]
--timestart hh:mm[:ss]
[!] --weekdays day[,day....]
[!]—monthdays day
--datestart YYYYMMDDhhmmss
--datestop YYYYMMDDhhmmss
--kerneltz:使用内核配置的时区而非默认的UTC
//指明了范围,周几
iptables -A INPUT -d 192.168.80.63 -p tcp --dport 23 -m iprange --src-range 192.168.80.1-192.168.80.88 -m time --timestart 10:00:00 --timestop 16:00:00 --weekdays 1,2,3,4,5 --kerneltz -j ACCEPT
iptables -A INPUT -d 192.168.80.63 -p tcp --dport 23 -m iprange --src-range 192.168.80.1-192.168.80.88 -m time --datestart 2007-01-01T17:00 --datestop 2007-01-01T23:59:59 -j ACCEPT
string 字符串匹配
--alog {bm|kmp} :字符匹配查找时使用的算法,任意一个都行
--string “STRING” :要查找的字符串
//可用nginx或apache测试
iptables -I OUTPUT -s 192.168.80.9 -m string --algo kmp --string "gay" -j REJECT
对于非加密的协议生效,对于ssh,https是不生效的,仅对明文生效。
connlimit:每IP对指定服务的最大并发连接数
--connlimit-upto n
--connlimit-above n
upto:小于等于
above:大于
//如果大于两个连接就拒绝,用mysql或ssh验证,
iptables -I INPUT -d 192.168.80.11 -p tcp --syn --dport 22 -m connlimit --connlimit-above 2 -j REJECT
limit:报文速率控制
--limit #[/second|/minute|/hour|/day]
--limit-burst #
假如出口才3M,一个连接占完了怎么办?这时就可以用上limit,并不是限止的每秒发多少M,而是每秒/分/时/天发出多少个包,通过控制包的数量来进行限制,也就是卡住,怎么卡住?用令牌发,假如一秒给三个,没发包需要的时候就放到桶里面,桶有大小。
iptables -I INPUT 6 -d 192.168.80.6 -p icmp --icmp-type 8 -m limit --limit-burst 5 --limit 20/minute -j ACCEPT
可以在web服务器上配合
--syn,这样就能控制服务器每秒可以建立多少个连接
//辅助命令
tcpdump -i eth0 -nn icmp
//练习:仅允许80.6访问本机的22端口
iptables -A INPUT -s 192.168.80.6/32 -d 192.168.80.59/32 -p tcp --dport 22 -j ACCEPT
iptables -A OUTPUT -s 192.168.80.59/32 -d 192.168.80.6/32 -p tcp --sport 22 -j ACCEPT
iptables -P INPUT DROP
iptables -P OUTPUT DROP
保存和导入
//保存规则,默认规则会被保存到/etc/sysconfig/iptables文件中
service iptable save
//保存iptables至别的位置
iptables-save > /path/to/some_rulefile
//从自定义的位置读取并使之生效
iptables-restore < /path/to/some_rulefile
最好是把命令写入脚本当中开机运行,因为使用命令直接定义的规则只是在内核当中生效,并没有保存。




















