
1简介
数据结构与算法:【数据结构与数据结构的算法】
为什么取这么个名:
算法大千万象,我们往往讨论的是基于时间复杂度和空间复杂度为基础的计算机数据结构的算法;
大O表示法:T = O(f(n))
学习数据结构与算法主要就是为了优化计算机的执行效率;
"大O表示法"表示程序的执行时间或占用空间随数据规模的增长趋势,是一种度量计算性能的表示
T(n)我们已经讲过了,它表示代码执行的时间;n表示数据规模的大小;f(n)表示每行代码执行的次数总和
注意:
1 只关注循环执行次数最多的一段代码
2.加法法则:总复杂度等于量级最大的那段代码的复杂度
3.乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
T(n) = O(2n^2+2n+3) 也就是O(N^2)
常见的有 1 lgn n nlgn n平方 etc...
案列:求其时间复杂度
i=1;
while (i <= n) {
i = i * 2;
}
答案: 执行次数:lgN
备注:最好,最坏,均摊,平均等等
数据规模n =8 执行次数3
数据规模n =16 执行次数4
空间复杂度(Space Complexity)是对一个算法在运行过程中临时占用存储空间大小的量度;注意是临时
学数据结构和算法的目的就是为了写出更好的代码;从我的角度来看,一个中间件型的程序员务必要懂得数据结构与算法,从而在实现数据落地时选择更优化的方式,比如数据库的B+,redis的压缩表,跳表等等
进入正题:今天分享两部分:
1数据结构与算法的相关原理与实现
2 数据结构在主流中间件中的应用简介
一数组和链表
万物之祖【数组与链表】
数组:下标为什么是0,不是1
抽象表示:地址 = 首地址 + index 地址 = 首地址 + (index-1)
数组:动态扩容:[其实现往往包含开辟新的big内存空间,赋值过程}
array = copy(array ,newarray)
数组与压缩表的不同,大小统一(?怎么理解String[]的大小统一,String[]存的是引用还是对象)
数据的类型固定
数组不做过多叙述
链表:由于不必须按顺序存储,链表在插入的时候可以达到 O(1) 的复杂度,比另一种线性表 —— 顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要 O(n) 的时间,而顺序表相应的时间复杂度分别是 O(log n) 和O(1)。
使用链表结构可以克服数组需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。
单链表
原理:参见图,每个节点包含数据存储以及指针指向下一个节;
实践 单链表的实现核心就是一个责任链的调用
class Link{ // 链表的完成类
class Node{ // 保存每一个节点,此处为了方便直接定义成内部类
private String data ; // 保存节点的内容
private Node next ; // 保存下一个节点
public Node(String data){
this.data = data ; // 通过构造方法设置节点内容
}
public void add(Node newNode){ // 将节点加入到合适的位置
if(this.next==null){ // 如果下一个节点为空,则把新节点设置在next的位置上
this.next = newNode ;
}else{ // 如果不为空,则需要向下继续找next
this.next.add(newNode) ;
}
}
public void print(){
System.out.print(this.data + "\t") ; // 输出节点内容
if(this.next!=null){ // 还有下一个元素,需要继续输出
this.next.print() ; // 下一个节点继续调用print
}
}
public boolean search(String data){ // 内部搜索的方法
if(data.equals(this.data)){ // 判断输入的数据是否和当前节点的数据一致
return true ;
}else{ // 向下继续判断
if(this.next!=null){ // 下一个节点如果存在,则继续查找
return this.next.search(data) ; // 返回下一个的查询结果
}else{
return false ; // 如果所有的节点都查询完之后,没有内容相等,则返回false
}
}
}
public void delete(Node previous,String data){
if(data.equals(this.data)){ // 找到了匹配的节点
previous.next = this.next ; // 空出当前的节点
}else{
if(this.next!=null){ // 还是存在下一个节点
this.next.delete(this,data) ; // 继续查找
}
}
}
};
private Node root ; // 链表中必然存在一个根节点
public void addNode(String data){ // 增加节点
Node newNode = new Node(data) ; // 定义新的节点
if(this.root==null){ // 没有根节点
this.root = newNode ; // 将第一个节点设置成根节点
}else{ // 不是根节点,放到最后一个节点之后
this.root.add(newNode) ; // 通过Node自动安排此节点放的位置
}
}
public void printNode(){ // 输出全部的链表内容
if(this.root!=null){ // 如果根元素不为空
this.root.print() ; // 调用Node类中的输出操作
}
}
public boolean contains(String name){ // 判断元素是否存在
return this.root.search(name) ; // 调用Node类中的查找方法
}
public void deleteNode(String data){ // 删除节点
if(this.contains(data)){ // 判断节点是否存在
// 一定要判断此元素现在是不是根元素相等的
if(this.root.data.equals(data)){ // 内容是根节点
this.root = this.root.next ; // 修改根节点,将第一个节点设置成根节点
}else{
this.root.next.delete(root,data) ; // 把下一个节点的前节点和数据一起传入进去
}
}
}
};
public class Demo01{
public static void main(String args[]){
Link l = new Link() ;
l.addNode("A") ; // 增加节点
l.addNode("B") ; // 增加节点
l.addNode("C") ; // 增加节点
l.addNode("D") ; // 增加节点
l.addNode("E") ; // 增加节点
System.out.println("======= 删除之前 ========") ;
l.printNode() ;
// System.out.println(l.contains("X")) ;
l.deleteNode("C") ; // 删除节点
l.deleteNode("D") ; // 删除节点
l.deleteNode("A") ; // 删除节点
System.out.println("\n====== 删除之后 =========") ;
l.printNode() ;
System.out.println("\n查询节点:" + l.contains("B")) ;
}
};
链表是抽象的逻辑结构,在代码块中只有头结点,尾结点指针等引用 通过巧妙的引用关系使地址块产生关联关系,并且可以实现crud功能从而实现逻辑上的链表;
单向链表

双向链表
first last
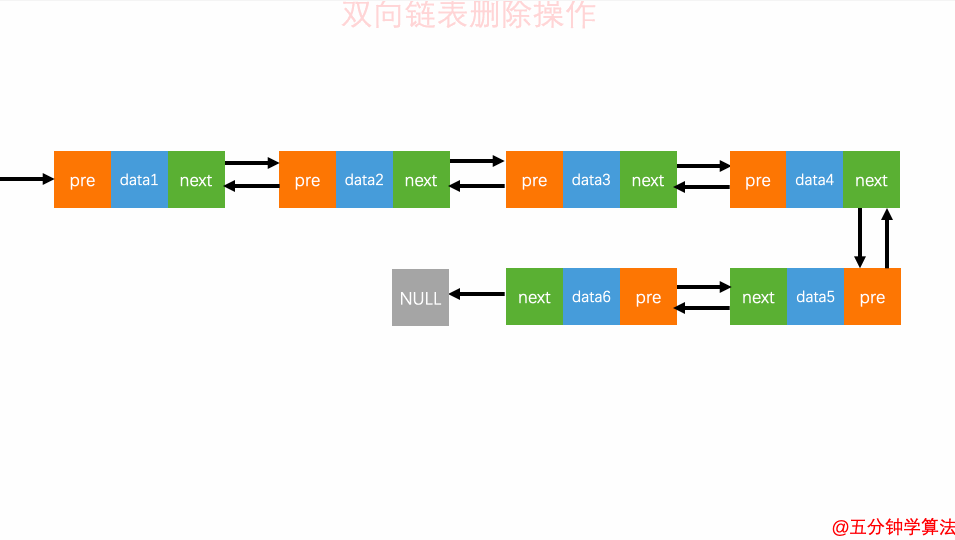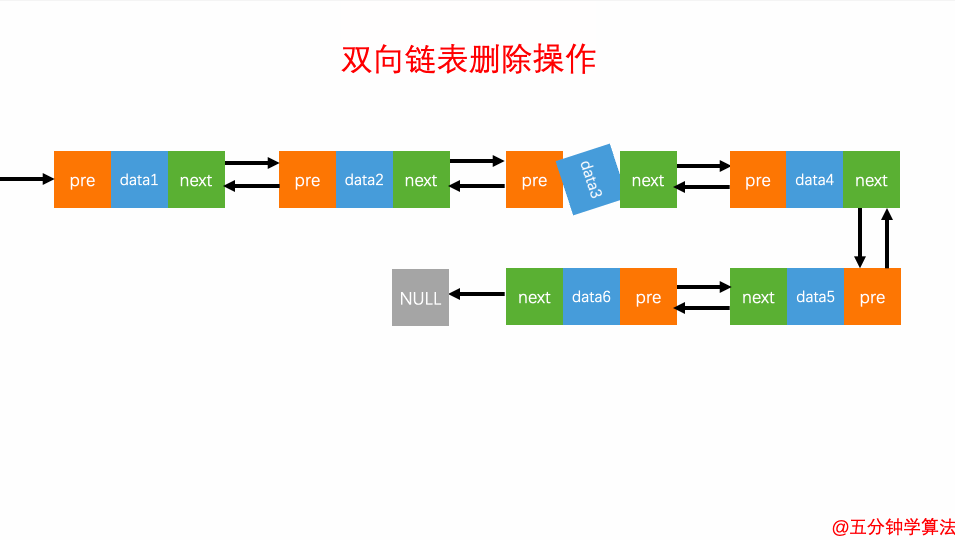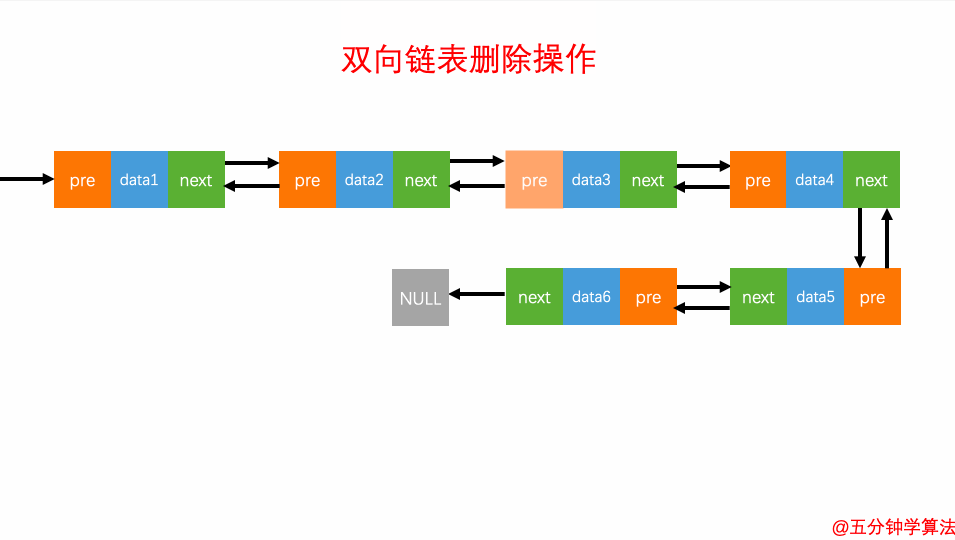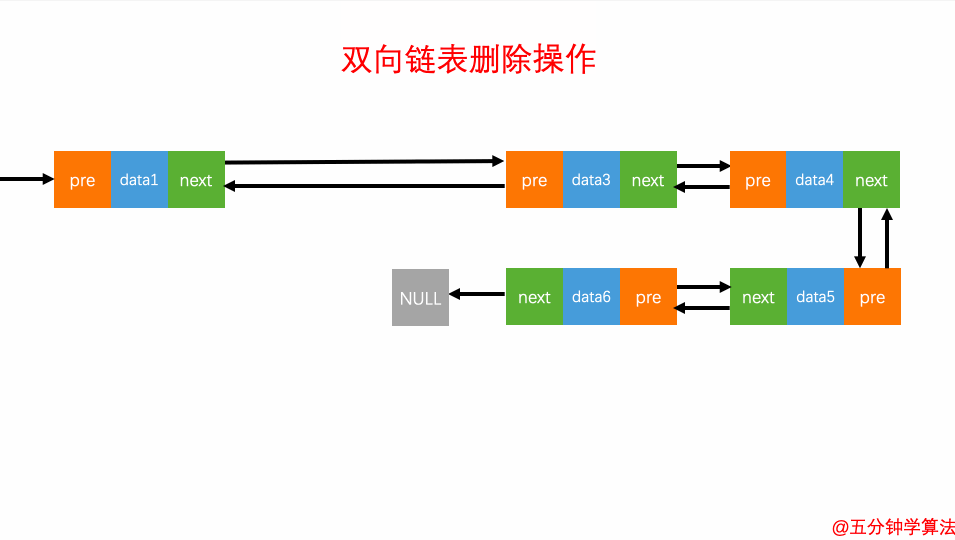
操作举例:
让上一个节点的next指向下一个节点
让下一个节点的pre指向上一个节点
程序实现:参见代码
主要包含:
add/deleteFrist add/deleteLast
addBefore/Last(key,value) deleteKey(key) 以及正向反向遍历
双向链表的优缺点:
相比双向链表可以反向遍历
增加了pre指针,相应的存储空间也会增加[在我看来,这在以前是一种缺点,以现在现代机器内存来说,这类缺点完全可以忽略]
双向链表的原理:参见图,其多了前驱后继节点,从而提高了遍历的灵活度
实践:
import org.junit.Test;
import java.io.IOException;
public class DoublyLinkList<T>{
class Link <T>{
public T val;
public Link<T> next;
public Link<T> pre;
public Link(T val) {
this.val = val;
}
public void displayCurrentNode() {
System.out.print(val + " ");
}
}
private Link<T> frist;
private Link<T> last;
public DoublyLinkList(){//初始化首尾指针
frist = null;
last = null;
}
public boolean isEmpty(){
return frist == null;
}
public void addFrist(T value){
Link<T> newLink= new Link(value);
if(isEmpty()){ // 如果链表为空
last = newLink; //last -> newLink
}else {
frist.pre = newLink; // frist.pre -> newLink
}
newLink.next = frist; // newLink -> frist
frist = newLink; // frist -> newLink
}
public void addLast(T value){
Link<T> newLink= new Link(value);
if(isEmpty()){ // 如果链表为空
frist = newLink; // 表头指针直接指向新节点
}else {
last.next = newLink; //last指向的节点指向新节点
newLink.pre = last; //新节点的前驱指向last指针
}
last = newLink; // last指向新节点
}
public boolean addBefore(T key,T value){
Link<T> cur = frist;
if(frist.next.val == key){
addFrist(value);
return true;
}else {
while (cur.next.val != key) {
cur = cur.next;
if(cur == null){
return false;
}
}
Link<T> newLink= new Link(value);
newLink.next = cur.next;
cur.next.pre = newLink;
newLink.pre = cur;
cur.next = newLink;
return true;
}
}
public void addAfter(T key,T value)throws RuntimeException{
Link<T> cur = frist;
while(cur.val!=key){ //经过循环,cur指针指向指定节点
cur = cur.next;
if(cur == null){ // 找不到该节点
throw new RuntimeException("Node is not exists");
}
}
Link<T> newLink = new Link<>(value);
if (cur == last){ // 如果当前结点是尾节点
newLink.next = null; // 新节点指向null
last =newLink; // last指针指向新节点
}else {
newLink.next = cur.next; //新节点next指针,指向当前结点的next
cur.next.pre = newLink; //当前结点的前驱指向新节点
}
newLink.pre = cur;//当前结点的前驱指向当前结点
cur.next = newLink; //当前结点的后继指向新节点
}
public void deleteFrist(){
if(frist.next == null){
last = null;
}else {
frist.next.pre = null;
}
frist = frist.next;
}
public void deleteLast(T key){
if(frist.next == null){
frist = null;
}else {
last.pre.next = null;
}
last = last.pre;
}
public void deleteKey(T key)throws RuntimeException{
Link<T> cur = frist;
while(cur.val!= key){
cur = cur.next;
if(cur == null){ //不存在该节点
throw new RuntimeException("Node is not exists");
}
}
if(cur == frist){ // 如果frist指向的节点
frist = cur.next; //frist指针后移
}else {
cur.pre.next = cur.next;//前面节点的后继指向当前节点的后一个节点
}
if(cur == last){ // 如果当前节点是尾节点
last = cur.pre; // 尾节点的前驱前移
}else {
cur.next.pre = cur.pre; //后面节点的前驱指向当前节点的前一个节点
}
}
public T queryPre(T value)throws IOException,RuntimeException{
Link<T> cur = frist;
if(frist.val == value){
throw new RuntimeException("Not find "+value+"pre");
}
while(cur.next.val!=value){
cur = cur.next;
if(cur.next == null){
throw new RuntimeException(value +"pre is not exeist!");
}
}
return cur.val;
}
public void displayForward(){
Link<T> cur = frist;
while(cur!=null){
cur.displayCurrentNode();
cur = cur.next;
}
System.out.println();
}
public void displayBackward(){
Link<T> cur = last;
while(cur!=null){
cur.displayCurrentNode();
cur = cur.pre;
}
System.out.println();
}
@Test
public void test()throws Exception{ // 自己测试代码
DoublyLinkList<Integer> d = new DoublyLinkList<Integer>();
d.addFrist(1);
// d.addFirst(1);
d.addFrist(2);
d.addFrist(3);
d.addLast(6);
d.addFrist(4);
d.addFrist(5);
d.addLast(7);
d.displayForward();
System.out.println(d.queryPre(4));
System.out.println(d.queryPre(0));
}
}
扩展:如何基于链表实现LRU?
每次遍历找到则移到表头,
每次插入插到表头,如果过长则移除链表表尾
每次更新则移动到表头【java的LinkList】
扩展1:基于单向链表实现lru算法; 【每次查找完将节点移动到表头】【添加不够的时候删除链表尾部】【添加到链表头部】
扩展2: 基于单向链表实现有序链表:【每次插入的时候比较大小】
扩展3:基于双向链表实现循环链表
不采用单链表的优势
- 相比单链表,双向循环链表所有基本操作均快于单链表(java源码的LinkList类就是双向循环链表)
- 能直接获取节点的前一个节点,十分灵活
二基本排序
插入: 插入的核心思想就是从左到右将右边为排序的插入到左边排序好的
冒泡: 冒泡的核心就是冒泡[交换与比较]
选择:从一个数组池中不断选择最值
代码实现只讲 插入排序:参见代码,为什么只讲插入[他们的时间复杂度都是大O(n^2)],插入的优点在哪里
动画实现
https://www.cs.usfca.edu/~galles/visualization/ComparisonSort.html
排序之间的比较:播放排序完毕的动画和随机数组的动画,插入的优点是什么?[是插入]

扩展:推荐同学们自行了解归并和快排: 其中归并的思想广泛被应用
二万物麻麻的衍生之队列与栈
所有的顺序结构和线性结构基本离不开数组或链表【也有其他:比如压缩表等等】
队列: 先进先出
队列概述:
队列的8大基本方法
异常 阻塞
aop add offer put
异常 阻塞
rpt remove poll take
element[peek]
队列的分类
有界队列【数组】
无界队列【链表】
队列的分类2
阻塞队列
非阻塞队列
如何实现阻塞队列
其实非常简单
以put和take举例
一个lock外加 一个fullCondition 和emptyCondition即可
调用add满了则fullCondtion 调用take唤醒fullCondtion等待的线程
这里主要涉及java并发和锁相关线程,大家可以自行参考java实现
参考代码: 1有界队列 2有界阻塞队列
优先级队列: 其原理是设置数据的优先级从而在插入的时候根据优先级插入到指定的位置
循环队列的指针问题:
循环队列解决了什么问题:
假溢出问题:刚刚的队列出队的时候做了一次for循环处理;来恢复空间的使用,否则就出现假溢出
而循环队列在更低的时间复杂度上解决了假溢出问题
2.循环队列的两个指针rear和front互相追赶着,这个追赶过程就是队列添加和删除的过程,如果rear追到head说明队列满了,如果front追到rear说明队列为空;
3 循环队列的队空队满的指针条件:
队空时: front=rear
队满时: (rear+1)%maxsize=front
[实际上这个公式只是业界的普遍定义,我们也可以反过来,但我没用代理证明,
同时为什么不反过来我个人认为和程序挂钩,初始化一个队列,指针都是0,0,初始化的队列肯定是空队列,也就是对空的条件给定是front=rear
这样队满再用一个条件就冲突了,所以空一个元素不存储数据,比如容量是5,则front是3,rear是2队满,且a[2]不存储数据]
循环队列详解
队列,先进先出 当rear到达capacity则rear= 0;
入队:rear++
出队:front++ ,当front到达capacity则front = 0;
这样得出的结论就是,每次入队出队后指针的位置为inedx= (inedx+1)%capacity;
给出的结论就是
入队:
q[rear] = object
rear= (rear+1)%capacity;
出队:
front = (front +1)%capacity;
再看队满对空的判断条件
队空 front=rear
队满时: (rear+1)%maxsize=front
最后一个队列的长度:
当rear>front size = rear-front
当reae<font
我们抽象下场景,原来是要扩容往扩容后的数组插入,现在是指针返回0
那(rear+capacity )-front是新的指针
综合就是:( rear - front + capacity) % capacity
如果听懂过掉下面
初始化5个长度的数组,一直入队,满队后rear=0, 0+5 -capacity = 5
入队ok,出队ok,队满队空条件ok,长度ok那么就可以实现代码了
参见代码
栈:
栈是先进后出的数据结构,java栈结构包含栈帧,栈帧的大小不定;参数参见xss默认1M
栈的代码同学们自行实现
三散列表
散列/哈希表
散列表:[hash表]
散列表的插入 查找的时间复杂度都是O(1)
但其核心问题是避免不了散列冲突
其二是散列空间的大小,过小过大都不合适;
散列冲突解决办法
1.开放寻址法
2链表法[hashmap]
2.再哈希法
常见的hash冲突问题解决方式
java hashmap的解决方式;
扰动函数的设计:
跳表
参见文档和代码
满二叉树
完全二叉树
二叉搜索树
平衡二叉搜索树
红黑树
左旋右旋讲下
b树
忽略:
b+树
b+树被创造的原因:
区间搜索如何实现;
1 散列表
2 二叉树[二叉树能否实现区间搜索]
3 跳表【为什么不用跳表 高度,索引大小磁盘化】
b+树
4 采用有序链表+M插树的结构
00o
000 000 000
000000000000000000000
一个M阶B+树的定义:【M指的是树的度】
B+树是B树的一种变形形式,B+树上的叶子结点存储关键字以及相应记录的地址,叶子结点以上各层作为索引使用。一棵m阶的B+树定义如下:
(1)每个结点至多有m个子女;
(2)除根结点外,每个结点至少有[m/2]个子女,根结点至少有两个子女;
(3)有m个子节点的非叶子节点拥有m-1个键,键按照升序排列;
M的大小多少合适?
以mysql举例;innodb_page_size
动画演示参见:https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
堆[大顶堆小顶堆]
倒排索引


















