

本文RIAD详解部分摘自:WIKI
RAID 0
RAID 0亦称为带区集。它将两个以上的磁盘串联起来,成为一个大容量的磁盘。在存放数据时,分段后分散存储在这些磁盘中,因为读写时都可以并行处理,所以在所有的级别中,RAID 0的速度是最快的。但是RAID 0既没有冗余功能,也不具备容错能力,如果一个磁盘(物理)损坏,所有数据都会丢失,危险程度与JBOD相当。
RAID 1
两组以上的N个磁盘相互作镜像,在一些多线程操作系统中能有很好的读取速度,理论上读取速度等于硬盘数量的倍数,另外写入速度有微小的降低。只要一个磁盘正常即可维持运作,可靠性最高。RAID 1就是镜像,其原理为在主硬盘上存放数据的同时也在镜像硬盘上写一样的数据。当主硬盘(物理)损坏时,镜像硬盘则代替主硬盘的工作。因为有镜像硬盘做数据备份,所以RAID 1的数据安全性在所有的RAID级别上来说是最好的。但无论用多少磁盘做RAID 1,仅算一个磁盘的容量,是所有RAID中磁盘利用率最低的一个级别。
如果用两个不同大小的磁盘建RAID 1,可用空间为较小的那个磁盘,较大的磁盘多出来的空间也可以分区成一个区来使用,不会造成浪费。
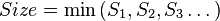
RAID 2
这是RAID 0的改良版,以汉明码(Hamming Code)的方式将数据进行编码后分区为独立的比特,并将数据分别写入硬盘中。因为在数据中加入了错误修正码(ECC,Error Correction Code),所以数据整体的容量会比原始数据大一些,RAID2最少要三台磁盘驱动器方能运作。
RAID 3
采用Bit-interleaving(数据交错存储)技术,它需要通过编码再将数据比特分割后分别存在硬盘中,而将同比特检查后单独存在一个硬盘中,但由于数据内的比特分散在不同的硬盘上,因此就算要读取一小段数据资料都可能需要所有的硬盘进行工作,所以这种规格比较适于读取大量数据时使用。
RAID 4
它与RAID 3不同的是它在分区时是以区块为单位分别存在硬盘中,但每次的数据访问都必须从同比特检查的那个硬盘中取出对应的同比特数据进行核对,由于过于频繁的使用,所以对硬盘的损耗可能会提高。(块交织技术,Block interleaving)
RAID 5
RAID Level 5是一种储存性能、数据安全和存储成本兼顾的存储解决方案。它使用的是Disk Striping(硬盘分区)技术。RAID 5至少需要三块硬盘,RAID 5不是对存储的数据进行备份,而是把数据和相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,并且奇偶校验信息和相对应的数据分别存储于不同的磁盘上。当RAID5的一个磁盘数据发生损坏后,可以利用剩下的数据和相应的奇偶校验信息去恢复被损坏的数据。RAID 5可以理解为是RAID 0和RAID 1的折衷方案。RAID 5可以为系统提供数据安全保障,但保障程度要比镜像低而磁盘空间利用率要比镜像高。RAID 5具有和RAID 0相近似的数据读取速度,只是因为多了一个奇偶校验信息,写入数据的速度相对单独写入一块硬盘的速度略慢,若使用“回写缓存”可以让性能改善不少。同时由于多个数据对应一个奇偶校验信息,RAID 5的磁盘空间利用率要比RAID 1高,存储成本相对较便宜。
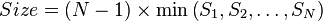
RAID 6
与RAID 5相比,RAID 6增加了第二个独立的奇偶校验信息块。两个独立的奇偶系统使用不同的算法,数据的可靠性非常高,即使两块磁盘同时失效也不会影响数据的使用。但RAID 6需要分配给奇偶校验信息更大的磁盘空间,相对于RAID 5有更大的“写损失”,因此“写性能”非常差。较差的性能和复杂的实作方式使得RAID 6很少得到实际应用。
同一数组中最多容许两个磁盘损坏。更换新磁盘后,数据将会重新算出并写入新的磁盘中。依照设计理论,RAID 6必须具备四个以上的磁盘才能生效。
可使用的容量为硬盘总数减去2的差,乘以最小容量,公式为:
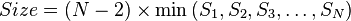
同理,数据保护区域容量则为最小容量乘以2。
RAID 6在硬件磁盘阵列卡的功能中,也是最常见的磁盘阵列等级。
JBOD
JBOD( Just a Bunch Of Disks)在分类上,JBOD并不是RAID的等级。由于并没有规范,市场上有两类主流的做法
使用单独的链接端口如SATA、USB或1394同时控制多个各别独立的硬盘,使用这种模式通常是较高级的设备,还具备有RAID的功能,不需要依靠JBOD达到合并逻辑扇区的目的。
只是将多个硬盘空间合并成一个大的逻辑硬盘,没有错误备援机制。
数据的存放机制是由第一颗硬盘开始依序往后存放,即操作系统看到的是一个大硬盘(由许多小硬盘组成的)。但如果硬盘损毁,则该颗硬盘上的所有数据将无法救回。若第一颗硬盘损坏,通常无法作救援(因为大部分文件系统将磁盘分区表(partition table)存在磁盘前端,即第一颗),失去磁盘分区表即失去一切数据,若遭遇磁盘阵列数据或硬盘出错的状况,危险程度较RAID 0更剧。它的好处是不会像RAID,每次访问都要读写全部硬盘。
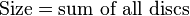
RAID 10/01
RAID 10是先镜射再分区数据,再将所有硬盘分为两组,视为是RAID 0的最低组合,然后将这两组各自视为RAID 1运作。
RAID 01则是跟RAID 10的程序相反,是先分区再将数据镜射到两组硬盘。它将所有的硬盘分为两组,变成RAID 1的最低组合,而将两组硬盘各自视为RAID 0运作。
当RAID 10有一个硬盘受损,其余硬盘会继续运作。RAID 01只要有一个硬盘受损,同组RAID 0的所有硬盘都会停止运作,只剩下其他组的硬盘运作,可靠性较低。如果以六个硬盘建RAID 01,镜射再用三个建RAID 0,那么坏一个硬盘便会有三个硬盘脱机。因此,RAID 10远较RAID 01常用,零售主板绝大部份支持RAID 0/1/5/10,但不支持RAID 01。
mdadm命令详解
mdadm用法
基本语法:mdadm [mode] [options]
mode 有7种:
Assemble:将以前定义的某个阵列假如当前在用的阵列
Build:Build a legacy array,每个device没有superblocks
Create:创建一个新的阵列,每个device具有superblocks
Manage:管理阵列,比如add或remove
Misc:允许单独对阵列中的某个decice做操作,比如抹去superblocks或终止在用的阵列
Follow or Monitor:监控 raid 1,4,5,6 和 multipath 的状态
Grow:改变raid容量或阵列中的device数目
可用的[options]:
-A --assemble:加入一个以前定义的阵列
-B --build:Build a legacy array without superblocks.
-C --create:创建一个新的阵列
-C: 创建模式中专用选项
-n #: 用于创建RAID设备的磁盘个数;
-l #: 级别
-a yes: 自动为创建的RAID生成设备文件;
-c Chunk_Size:
md设备的设备文件,一般在/dev目录下,以md开头,后跟一个数字来区别
-Q --query:查看一个device,判断它为一个md device 或是一个md 阵列的一部分
-D --detail:打印一个或多个md device 的详细信息
-E --examine:打印 device上的 md superblock 的内容
-F --follow ,--monitor:选择Monitor 模式
-G --grow:改变在用阵列的大小或形态
-help :帮助信息
-V:查看版本号
-v:显示细节
-b --brief:较少的细节。用于 --detail 和 --examine选项
-f --force
-c --config=:指定配置文件,缺省为 /etc/mdadm.conf
-s --scan:扫描配置文件或/proc/mdstat以搜寻丢失的信息。配置文件/etc/mdadm.conf
mdadm -D /dev/md#
显示指定的软RAID的详细信息
mdadm /dev/md# -f /dev/some_device
将/dev/md#中的/dev/some_device手动设置为损坏
mdadm /dev/md# -r /dev/some_device
将/dev/md#中的损坏状态的/dev/some_device移除
mdadm /dev/md# -a /dev/new_device
新增设备
实例演示软RAID划分
本实例的两块磁盘


[root@mage 10.19.166.23 ~ ] #查看可硬盘分区情况 # fdisk -l Device Boot Start End Blocks Id System /dev/sdb1 1 2871 23061276 fd Linux raid autodetect Device Boot Start End Blocks Id System /dev/sdc1 1 1305 10482381 fd Linux raid autodetect
[root@mage 10.19.166.23 ~ ] # mdadm -C /dev/md0 -a yes -n 2 -l 0 /dev/sdb1 /dev/sdc1 <--上面的意思是,创建一个新的阵列/dev/md0,指定模式为自动创建,创建磁盘的各位为2,级别为0--> mdadm: Defaulting to version 1.2 metadata mdadm: array /dev/md0 started. [root@mage 10.19.166.23 ~ ] # cat /proc/mdstat #当前系统上所有已启用的软件RAID设备及其相关信息 Personalities : [raid0] md0 : active raid0 sdc1[1] sdb1[0] 33510400 blocks super 1.2 512k chunks unused devices: <none>
[root@mage 10.19.166.23 ~ ] # mke2fs -t ext4 /dev/md0 #格式化硬盘,指定格式化硬盘的格式ext4 mke2fs 1.41.12 (17-May-2010) Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=128 blocks, Stripe width=256 blocks 2097152 inodes, 8377600 blocks 418880 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=4294967296 256 block groups 32768 blocks per group, 32768 fragments per group 8192 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000, 7962624 Writing inode tables: done Creating journal (32768 blocks): done Writing superblocks and filesystem accounting information: done This filesystem will be automatically checked every 35 mounts or 180 days, whichever comes first. Use tune2fs -c or -i to override.
# mkdir /backup # mount /dev/md0 /backup/ #挂载

# df Filesystem 1K-blocks Used Available Use% Mounted on /dev/sda1 41283904 903368 38283436 3% / tmpfs 506176 0 506176 0% /dev/shm /dev/md0 32983920 180152 31128248 1% /backup


















