
一、实验拓扑图:
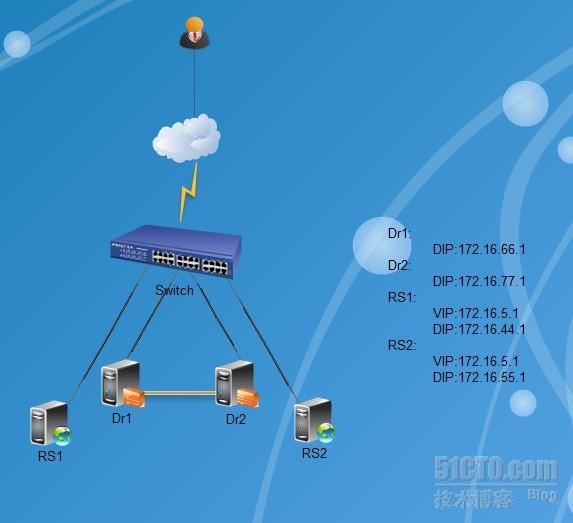
二、实验介绍
Corosync+pacemaker结合起来可以提供更强大的,功能更新的,维护状态更活跃的高可用集群,本文的主要
就是利用Corosync+pacemaker实现LVS的director的高可用。如上图实验拓扑图所示:RS1、RS1和Dr1够成一个负载均
衡集群,为了实现此集群的高可用,又将此集群的Director即:Dr1与Dr2做成高可用集群。
三、实验前提:
(1)将Dr1和Dr2配置成双机互信。并让这四台服务器的时间同步
(2)将RS1、RS2和Dr2配成LVS-DR模型的集群,配好后让ipvsadm开机不能自动启动,并用#ipvsadm -C清空
定义的规则;并在Dr2中安装ipvsadm。(此过程可参照: Heartbeat v2+heartbeat-ldirectord实现LVS(DR)中Director的高可用此博文)
四、实验步骤:
完成以上步骤之后,就可以开始进行如下操作:
Dr1:
(1)下载软件包并安装:
cluster-glue-1.0.6-1.6.el5.i386.rpm
cluster-glue-libs-1.0.6-1.6.el5.i386.rpm
(这两个软件包是Corosync和pacemaker的中间层,即使Corosync和pacemaker相互兼容)
corosync-1.2.7-1.1.el5.i386.rpm
corosynclib-1.2.7-1.1.el5.i386.rpm
(这不做解释,相信大家都明白O(∩_∩)O哈!)
heartbeat-3.0.3-2.3.el5.i386.rpm
heartbeat-libs-3.0.3-2.3.el5.i386.rpm
(以上两个是pacemaker所依赖的软件包,必须得安装)
ldirectord-1.0.1-1.el5.i386.rpm
perl-MailTools-1.77-1.el5.noarch.rpm
perl-TimeDate-1.16-5.el5.noarch.rpm
(ldirectord可以实现Director的高可用,并可以检查RS的健康状况,其余两个都是其所依赖的软件包)
openais-1.1.3-1.6.el5.i386.rpm
openaislib-1.1.3-1.6.el5.i386.rpm
(以上两个可以安装也可不安装)
pacemaker-1.1.5-1.1.el5.i386.rpm
pacemaker-cts-1.1.5-1.1.el5.i386.rpm
pacemaker-libs-1.1.5-1.1.el5.i386.rpm
resource-agents-1.0.4-1.1.el5.i386.rpm(资源代理)
libesmtp-1.0.4-5.el5.i386.rpm
#yum -y --nogpgcheck localinstall *.rpm
注意同时需要在Dr2中也安装相同的软件包
(2)将corosync和pacemaker整合
- #cd /etc/corosync/
- #cp corosync.conf.example corosync.conf
- #vim corosync.conf
- totem {
- version: 2
- secauth: on
- threads: 0
- interfae {
- ringnumber: 0
- bindnetaddr: 172.16.0.0 //写出需绑定地址的网段
- mcastaddr: 226.94.58.1 //组播地址
- mcastport: 5405
- }
- }
- logging {
- fileline: off
- to_stderr: no
- to_logfile: yes
- #to_syslog: yes
- logfile: /var/log/cluster/corosync.log
- debug: off
- timestamp: on
- logger_subsys {
- subsys: AMF
- debug: off
- }
- }
- service {
- ver: 0
- name: pacemaker
- }
- aisexec {
- user: root
- group: root
- }
- amf {
- mode: disabled
- }
- #corosync-keygen //创建认证文件
- #mkdir /var/log/cluster //创建日志文件目录
- #scp corosync.conf node2:/etc/corosync/
- #ssh node2 'mkdir /var/log/cluster'
(3)启动服务并检查其是否正常
#service corosync start
1、 验证 corosync引擎是否启动成功
- # grep -e 'Corosync Cluster Engine' -e 'configuration' /var/log/cluster/corosync.log
- Aug 10 11:05:59 corosync [MAIN ] Corosync Cluster Engine ('1.2.7'): started and ready to provide service.
- Aug 10 11:05:59 corosync [MAIN ] Successfully read main configuration file '/etc/corosync/corosync.conf'.
2、查看初始化成员节点通知是否正常出发
- # grep TOTEM /var/log/cluster/corosync.log
- Aug 10 11:05:59 corosync [TOTEM ] Initializing transport (UDP/IP).
- Aug 10 11:05:59 corosync [TOTEM ] Initializing transmit/receive security: libtomcrypt SOBER128/SHA1HMAC (mode 0).
- Aug 10 11:05:59 corosync [TOTEM ] The network interface [172.16.66.1] is now up.
- Aug 10 11:05:59 corosync [TOTEM ] Process pause detected for 525 ms, flushing membership messages.
- Aug 10 11:05:59 corosync [TOTEM ] A processor joined or left the membership and a new membership was formed.
3、查看启动过程中是否有错误产生
- # grep ERROR /var/log/cluster/corosync.log
- Aug 10 11:07:02 node1 pengine: [22023]: ERROR: unpack_resources: Resource start-up disabled since no STONITH resources have been defined
- Aug 10 11:07:02 node1 pengine: [22023]: ERROR: unpack_resources: Either configure some or disable STONITH with the stonith-enabled option
- Aug 10 11:07:02 node1 pengine: [22023]: ERROR: unpack_resources: NOTE: Clusters with shared data need STONITH to ensure data integrity
- 若出现以上错误时由于未安装STONITH设备而造成的可以忽略
4、查看pacemaker是否启动
- # grep pcmk_startup /var/log/cluster/corosync.log
- Aug 10 11:05:59 corosync [pcmk ] info: pcmk_startup: CRM: Initialized
- Aug 10 11:05:59 corosync [pcmk ] Logging: Initialized pcmk_startup
- Aug 10 11:05:59 corosync [pcmk ] info: pcmk_startup: Maximum core file size is: 4294967295
- Aug 10 11:05:59 corosync [pcmk ] info: pcmk_startup: Service: 9
- Aug 10 11:05:59 corosync [pcmk ] info: pcmk_startup: Local hostname: node1
- # ssh node2 'service corosync start'(启动node2的corosync,并检查其是否成功,步骤同上)
(4)配置ldirectord
- # cp /usr/share/doc/heartbeat-ldirectord-2.1.4/ldirectord.cf /etc/ha.d/
- # vim /etc/ha.d/ldirectord.cf
- virtual=172.16.5.1:80
- real=172.16.44.1:80 gate
- real=172.16.55.1:80 gate
- fallback=127.0.0.1:80 gate
- service=http
- scheduler=rr
- #persistent=600
- #netmask=255.255.255.255
- protocol=tcp
- checktype=negotiate
- checkport=80
- request=".test.html"
- receive="OK"
- virtualhost=www.x.y.z
- # scp /etc/ha.d/ldirectord.cf node2:/etc/ha.d/
(5)配置资源
配置资源之前,先配置集群的参数:
- (1)禁用stonith
- #crm(live)# configure
- crm(live)configure# property stonith-enabled=false
- crm(live)configure# property no-quorum-policy=ignore
- crm(live)configure# commit
- crm(live)configure# exit
- (2)crm(live)configure# property no-quorum-policy=ignore(忽略策略)
- crm(live)configure# commit
- crm(live)configure# exit
- 这样的话可以当一个节点的服务停掉是,可以转到另一个节点
资源的配置:
- # crm
- crm(live)# configure
- crm(live)configure# primitive VIP ocf:heartbeat:IPaddr params ip=172.16.5.1
- nic=eth0:0 cidr_netmask=255.255.255.255 broadcast=172.16.5.1 //配置VIP资源
- crm(live)configure# primitive LVS lsb:ldirectord //配置ldirectord资源
- crm(live)configure# colocation VIP_with_LVS inf: VIP LVS //定义排列约束,使VIP和LVS两个资源必须同时在一个节点上
- crm(live)configure# location conn1 VIP 100: director2 //定义位置约束,使VIP资源更倾向于运行与director2节点
- crm(live)configure# commit //提交配置
- crm(live)configure# exit //退出
五、实验结果测试:
(1)刚配完之后查看资源是否生效
- (1)查看状态:
- root@node1 corosync]# crm_mon
- Connection to the CIB terminated
- Reconnecting...[root@node1 corosync]# crm_mon -1
- ============
- Last updated: Fri Aug 10 16:24:54 2012
- Stack: openais
- Current DC: node1 - partition with quorum
- Version: 1.1.5-1.1.el5-01e86afaaa6d4a8c4836f68df80ababd6ca3902f
- 2 Nodes configured, 2 expected votes
- 2 Resources configured.
- ============
- Online: [ node1 node2 ]
- VIP (ocf::heartbeat:IPaddr): Started node2
- LVS (lsb:ldirectord): Started node2
- (2)查看资源:
- [root@node1 corosync]#ssh node2 'ifconfig' (查看vip是否生效)
- eth0 Link encap:Ethernet HWaddr 00:0C:29:10:55:33
- inet addr:172.16.77.1 Bcast:172.16.255.255 Mask:255.255.0.0
- UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
- RX packets:866240 errors:0 dropped:0 overruns:0 frame:0
- TX packets:168454 errors:0 dropped:0 overruns:0 carrier:0
- collisions:0 txqueuelen:1000
- RX bytes:186781842 (178.1 MiB) TX bytes:22115957 (21.0 MiB)
- Interrupt:67 Base address:0x2000
- eth0:0 Link encap:Ethernet HWaddr 00:0C:29:10:55:33
- inet addr:172.16.5.1 Bcast:172.16.5.1 Mask:255.255.255.255
- UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
- Interrupt:67 Base address:0x2000
- lo Link encap:Local Loopback
- inet addr:127.0.0.1 Mask:255.0.0.0
- UP LOOPBACK RUNNING MTU:16436 Metric:1
- RX packets:6880 errors:0 dropped:0 overruns:0 frame:0
- TX packets:6880 errors:0 dropped:0 overruns:0 carrier:0
- collisions:0 txqueuelen:0
- RX bytes:902177 (881.0 KiB) TX bytes:902177 (881.0 KiB)
- [root@node1 corosync]# ipvsadm -Ln (查看ldirectord是否生效)
- IP Virtual Server version 1.2.1 (size=4096)
- Prot LocalAddress:Port Scheduler Flags
- -> RemoteAddress:Port Forward Weight ActiveConn InActConn
- TCP 172.16.5.1:80 rr
- -> 172.16.55.1:80 Route 1 0 0
- -> 172.16.44.1:80 Route 1 0 0
(2)测试效果,在浏览其中访问10次,查看结果:
- root@node1 corosync]# ipvsadm -Ln
- IP Virtual Server version 1.2.1 (size=4096)
- Prot LocalAddress:Port Scheduler Flags
- -> RemoteAddress:Port Forward Weight ActiveConn InActConn
- TCP 172.16.5.1:80 rr
- -> 172.16.55.1:80 Route 1 0 5
- -> 172.16.44.1:80 Route 1 0 5
- 这就是负载均衡的结果
(3)假设RS1挂掉之后的情况:
- [root@node1 corosync]# ipvsadm -Ln
- IP Virtual Server version 1.2.1 (size=4096)
- Prot LocalAddress:Port Scheduler Flags
- -> RemoteAddress:Port Forward Weight ActiveConn InActConn
- TCP 172.16.5.1:80 rr
- -> 172.16.55.1:80 Route 1 0 11
(4)当Dr2挂掉之后,看一下Dr1是否工作
- 让node2 standby看看是否转移到node1上
- [root@node2 corosync]# ssh node1 'ifconfig'
- eth0 Link encap:Ethernet HWaddr 00:0C:29:C1:CB:91
- inet addr:172.16.66.1 Bcast:172.16.255.255 Mask:255.255.0.0
- UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
- RX packets:235799 errors:0 dropped:0 overruns:0 frame:0
- TX packets:218981 errors:0 dropped:0 overruns:0 carrier:0
- collisions:0 txqueuelen:1000
- RX bytes:83322431 (79.4 MiB) TX bytes:39479951 (37.6 MiB)
- Interrupt:67 Base address:0x2000
- eth0:0 Link encap:Ethernet HWaddr 00:0C:29:C1:CB:91
- inet addr:172.16.5.1 Bcast:172.16.5.1 Mask:255.255.255.255
- UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
- Interrupt:67 Base address:0x2000
- lo Link encap:Local Loopback
- inet addr:127.0.0.1 Mask:255.0.0.0
- UP LOOPBACK RUNNING MTU:16436 Metric:1
- RX packets:11597 errors:0 dropped:0 overruns:0 frame:0
- TX packets:11597 errors:0 dropped:0 overruns:0 carrier:0
- collisions:0 txqueuelen:0
- RX bytes:1565341 (1.4 MiB) TX bytes:1565341 (1.4 MiB)
- [root@node1 corosync]# ipvsadm -Ln
- IP Virtual Server version 1.2.1 (size=4096)
- Prot LocalAddress:Port Scheduler Flags
- -> RemoteAddress:Port Forward Weight ActiveConn InActConn
- TCP 172.16.5.1:80 rr
- -> 172.16.44.1:80 Route 1 0 0
- -> 172.16.55.1:80 Route 1 0 11
这样实验就结束了,有不足之处还请大家多多指教……


















