由于这段时间都在进行实验,在进行数据库恢复的时候,所引起一系列的错误,记录所出现的错误及解决办法
进入PL/SQL Developer时报ora-01033:oracle initializationg or shutdown in progress
表示ORACLE 正在初始化或关闭
遂进入 E:\oracle\product\10.2.0\admin\orcl\bdump\ 下的alert_orcl.log查看
具体显示如下:
starting up 1 dispatcher(s) for network address '(ADDRESS=(PARTIAL=YES)(PROTOCOL=TCP))'...
MMNL started with pid=12, OS id=3256
Wed Jan 09 09:58:27 2013
starting up 1 shared server(s) ...
Wed Jan 09 09:58:28 2013
alter database mount exclusive
Wed Jan 09 09:58:33 2013
Setting recovery target incarnation to 2
Wed Jan 09 09:58:33 2013
Successful mount of redo thread 1, with mount id 1332029637
Wed Jan 09 09:58:33 2013
Failed to allocate 3981204 bytes from shared pool for flashback generation buffer
Wed Jan 09 09:58:33 2013
Errors in file e:\oracle\product\10.2.0\admin\orcl\udump\orcl_ora_3768.trc:
ORA-04031: ???? 3981220 ??????? ("shared pool","unknown object","sga heap(1,0)","flashback generation buffer")
网上查了一下 具体错误原因:
共享内存太小,分配给共享池的内存不足以满足用户请求,或者存在一定碎片,没有有效的利用保留区,造成无法分配合适的共享区。
一个ORACLE例程的系统全局区域(SGA)包含几个内存区域(包括缓冲高速缓存、共享池、Java 池、大型池和重做日志缓冲)
SGA=db_cache+shared_pool+java_pool+large_pool
处理方法:
手动调整SGA的大小,然后重新分配四大内存区域的大小。主要增加共享内存和缓冲高速缓存。
sql> show sga; //查看SGA的具体大小信息。
sql>show parameter sga_max_size //查看SGA最大值
sql> show parameter shared_pool //查看共享内存
sql>show parameter db_cache //查看数据缓存
sql> alter system set sga_max_size = 500M scope=spfile;//修改SGA最大值
sql> alter system set shared_pool_size =200M scope=spfile; //修改共享内存
sql> alter system set db_cache_size =250M scope=spfile; //修改数据缓存
一个ORACLE例程的系统全局区域(SGA)包含几个内存区域(包括缓冲高速缓存、共享池、Java 池、大型池和重做日志缓冲)
SGA=db_cache+shared_pool+java_pool+large_pool
处理方法:
手动调整SGA的大小,然后重新分配四大内存区域的大小。主要增加共享内存和缓冲高速缓存。
sql> show sga; //查看SGA的具体大小信息。
sql>show parameter sga_max_size //查看SGA最大值
sql> show parameter shared_pool //查看共享内存
sql>show parameter db_cache //查看数据缓存
sql> alter system set sga_max_size = 500M scope=spfile;//修改SGA最大值
sql> alter system set shared_pool_size =200M scope=spfile; //修改共享内存
sql> alter system set db_cache_size =250M scope=spfile; //修改数据缓存
以上解决方法来自网络
最后重启服服发现,可以登录,之后会出现ORA-04031: ???? 3981220 ??????? ("shared pool","unknown object","sga heap(1,0)","flashback generation buffer")
同样的错误
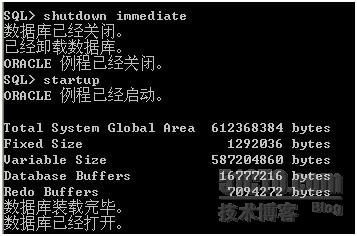
如下操作步骤:
WINDOWS 命令行 输入 sqlplus “/as sysdba”
接着关闭ORACLE
SHUTDOWN IMMEDIATE
出错如下异常:

接下来开启
Startup
错误如下:
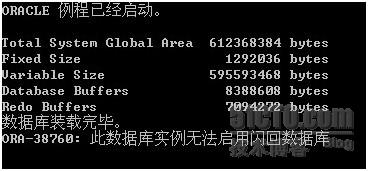
注意:有的时候 设置打开闪回,如果日志不够,ORACLE是打不开的
所有针对办法
关闭闪回
Alter database flashback off;
打开数据库
Alter database open;
问题解决