
grep根据某一个模式,去搜索文本,并将复核模式的文本行显示出来。
使用模式:文本字符和正则表达式的元字符组合而成匹配条件
grep 选项 模式 文件名
-i 不区分大小写
--color 颜色显示
-v 显示没有被模式匹配到的行
-o 只显示被模式匹配到的字符串
正则表达式:REGular EXPression REGEXP
元字符:
. 匹配任意单个字符
[] 匹配指定范围内的任意单个字符
[^] 匹配指定范围外的任意单个字符
字符集和 [:space:] 表示所有的空白字符
[:punct:] 表示所有的标点符号
[:lower:] 表示所有的小写字母
[:upper:] 表示所有的大写字母
[:alpha:] 表示所有的大小写字母
[:digit:] 表示所有的数字
[:alnum:] 表示所有的数字和大小写字母也支持
用的时候再加个中括号
匹配次数:(贪婪模式-尽可能长的匹配)
*:匹配其前面的字符任意次数
例 a,b,ab,aab,acb,adb,amnb
a*b 只有 b、aab、ab、匹配
.* 任意长度的任意字符
例 a.*b 除了a、b之外都能匹配
\? 匹配其前面的字符1次或0次
\{m,n\}: 匹配其前面的字符至少m次,至多n次
\{1,\} 最少1次,最多不限
\{0,3\} 最多三次
位置锚定:
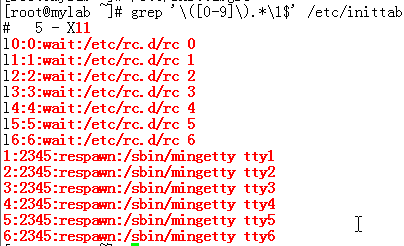
^ 锚定行首,此字符后面的任意内容必须出现在行首
$ 锚定行尾,此字符前面的任意内容必须出现在行尾
^$ 空白行
\< 锚定词首 其后面的任意字符必须作为单词首部出现
\> 锚定词尾 其后面的任意字符必须作为单词的尾部出现
分组
\(\) 例 \(ab\)* 表示ab可以出现任意次
\1 第一个左括号以及与之对应的右括号所包括的所有内容
\2 第二个左括号以及与之对应的右括号所包含的所有内容
\3 同上
扩展正则表达式 egrep
字符匹配:
. 表示匹配任意单个字符
[] 表示匹配指定范围内的任意单个字符
[^] 表示匹配指定范围内的任意单个字符
次数匹配
* 匹配其前面的字符任意次
? 匹配其前面的字符一次或零次,部分匹配就可以
+ 匹配其前面的字符至少一次
{m,n} 匹配其前面的字符至少m次,至多n次
位置锚定
和正则表达式相同
^ 锚定行首,此字符后面的任意内容必须出现在行首
$ 锚定行尾,此字符前面的任意字符必须出现在行尾
^$ 空白行
分组:
() 分组
\1,\2,\3,……
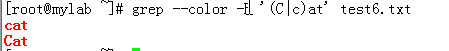
或者
| 相当于or
\逃逸符,让符号显示出它本身
egrep '



















