
前面几个篇幅,我们介绍了alertmanger报警配置,在实际运维过程中,我们都会遇到,报警的重复发送,以及报警信息关联性报警。接下来我们就介绍下通过alertmanger对告警信息的收敛。
一、告警分组(Grouping)
1.1 定义三个报警规则:
文中为了实验验证,告警值设置比较小,实际生产中,应该跟据业务的实际使用场景,来确定合理的告警值

[root@prometheus-server ~]# vim /etc/prometheus/rules/node_alerts.yml
groups:- name: node_alerts
rules:
- alert: InstanceDown
expr: up{job='node'} == 0
for: 2m
labels:
severity: "critical"
env: dev
annotations:
summary: Host {{ $labels.instance }} of {{ $labels.job }} is Down!
- alert: OSLoad
expr: node_load1 > 1
for: 2m
labels:
severity: "warning"
env: dev
annotations:
summary: "主机 {{ $labels.instance }} 负载大于 1"
description: "当前值: {{ $value }}"
- alert: HightCPU
expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by(instance)*100 > 10
for: 2m
labels:
severity: "warning"
annotations:
summary: "主机 {{ $labels.instance }} of CPU 使用率大于10%!"
description: "当前值: {{ $value }}%"
以上3个报警规则,node_alerts是监控node_exporter服务状态,OSLoad是监控系统负载,HightCPU是监控系统cpu使用率,前两个有标签env: dev,后面2个有标签 severity: "warning",重启Prometheus服务,可以看到监控规则已经加载
1.2 定义alertmanager报警组:
-- name: - to:
1.3 验证
我们停掉一台主机node_exporter(10.10.0.12)服务,用压测工具使某一台机器(10.10.0.11)负载大于1,cpu使用率(10.10.0.11)大于10,看下报警邮件是否会按我们定义组进行报警:
虽然我们同时触发了三个报警,但是跟据我们的定义,应该只会发两条报警信息,因为拥有env标签的报警规则,同时报警,会被合并为一条发送。
触发报警查看Prometheus ui界面上的alerts:

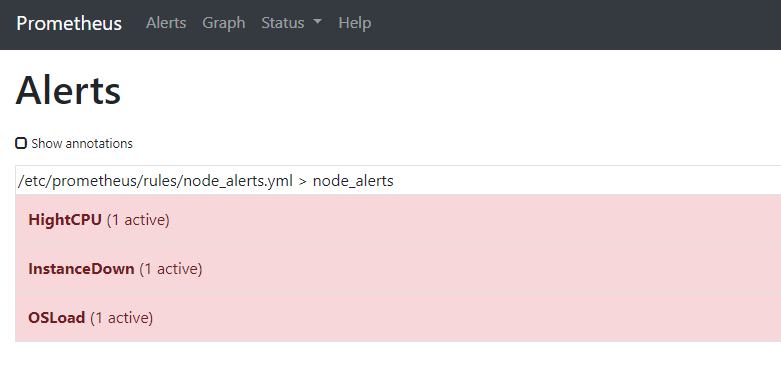
等2分钟后,如果检测到机器还是处于触发告警状态,Prometheus把会告警信息发送至alertmanager,然后跟据报警定义进行邮件报警:
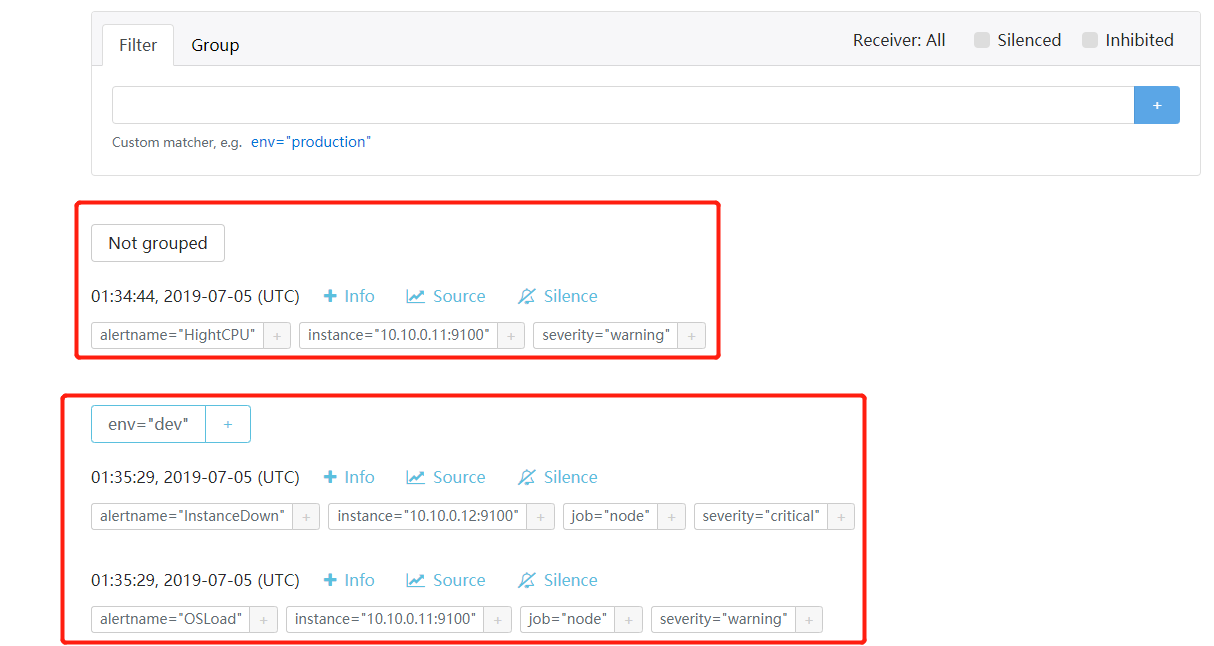
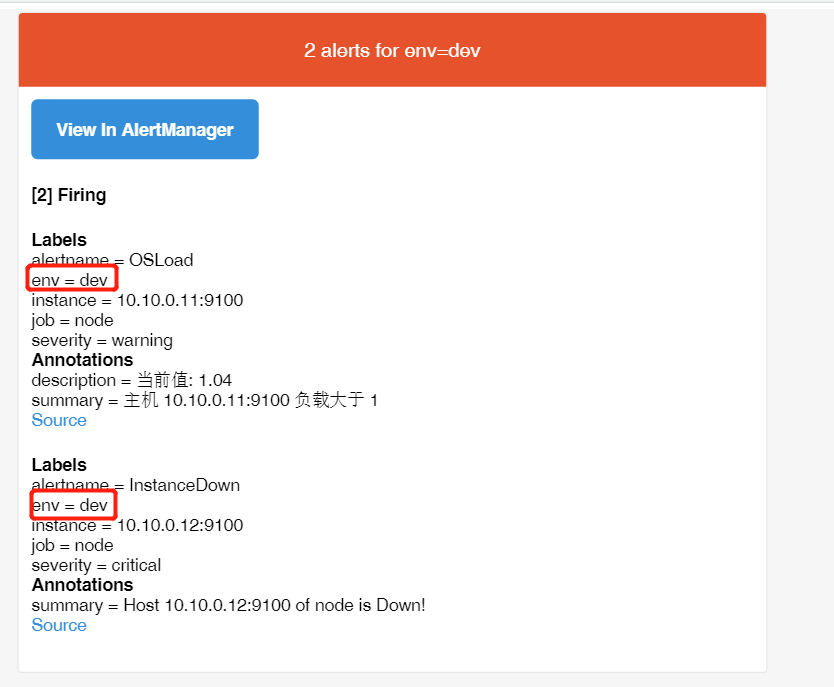
上图从alertmanager报警界面可以看到,报警信息已经按照分组合并,接下来我们看下邮箱中报警信息:
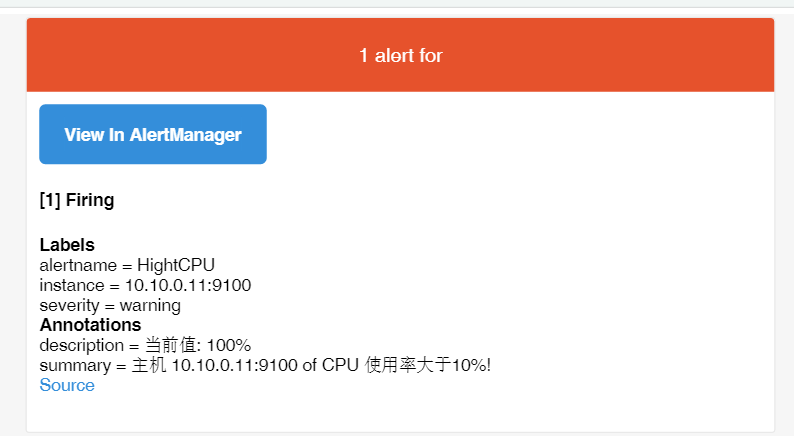
分组总结:
1、alertmanager跟据标签进行分组时,应该选择合适的标签,标签可以自定义,也可以使用默认的标签。
2、alertmanager报警分组,可以有效减少告警邮件数,但是仅是在同一个时间段报警,同一个组的告警信息才会合并发送。
二、告警抑制(Inhibition)
2.1 修改Prometheus 报警规则文件,为报警信息添加新标签area: A
[root@prometheus-server ~]# vim /etc/prometheus/rules/node_alerts.yml
groups:
- name: node_alerts
rules:
- alert: InstanceDown
expr: up{job='node'} == 0
for: 2m
labels:
severity: "critical"
env: dev
area: A
annotations:
summary: Host {{ $labels.instance }} of {{ $labels.job }} is Down!
- alert: OSLoad
expr: node_load1 > 0.6
for: 2m
labels:
severity: "warning"
env: dev
area: A
annotations:
summary: "主机 {{ $labels.instance }} 负载大于 1"
description: "当前值: {{ $value }}"
- alert: HightCPU
expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by(instance)*100 > 10
for: 2m
labels:
severity: "warning"
area: A
annotations:
summary: "主机 {{ $labels.instance }} of CPU 使用率大于10%!"
description: "当前值: {{ $value }}%"
2.2 修改alertmanager配置文件
-] ## 需要都有相同的标签及值,否则抑制不起作用
2.3 验证
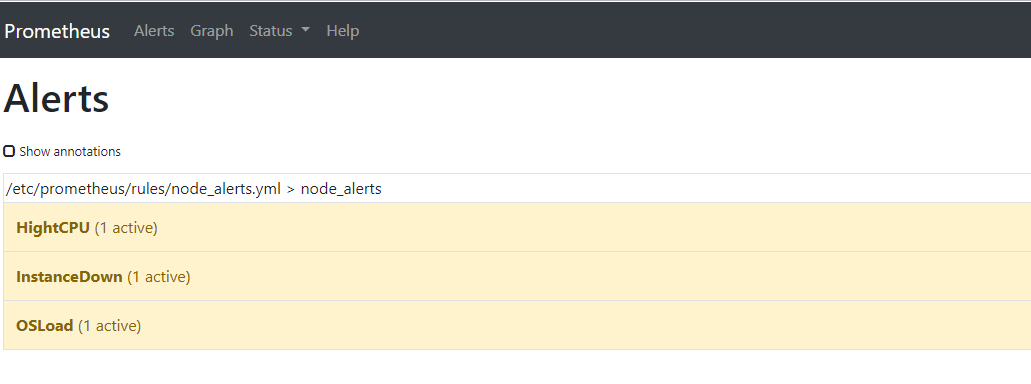
跟上面一样手动触发三个规则告警,跟据定义规则,应该只会收到一条报警信息:
查看Prometheus告警都已经触发,状态变为PENDING状态
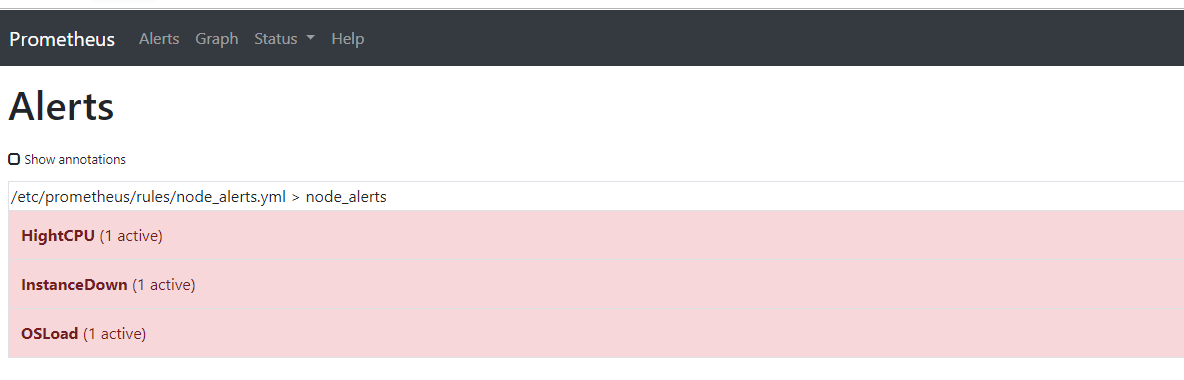
等待2分钟后, 三个告警状态由PENDING 变为 FIRING,同时prometheus会把告警信息发给alertmanager。
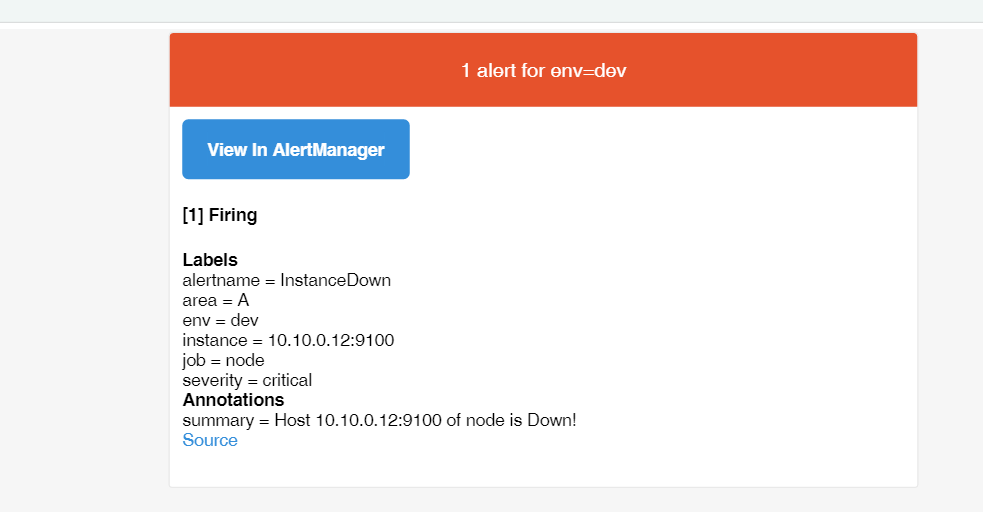
Alertmanager中我们只看到一条InstanceDown报警信息。

查看邮件中,也只收到InstanceDown的报警,另外2条报警已经被配置的抑制规则,把报警信息忽略掉。
抑制总结:
1、抑制是指当警报发出后,停止重复发送由此警报引发其他错误的警报的机制。(比如网络不可达,服务器宕机等灾难性事件导致其他服务连接相关警报);
2、配置抑制规则,需要合理源规则及需要抑制的规则;
3、源规则与抑制规则需要具有相同的标签及标签值;


















