
1.
安装Ubuntu10.10
wubi安装不解释
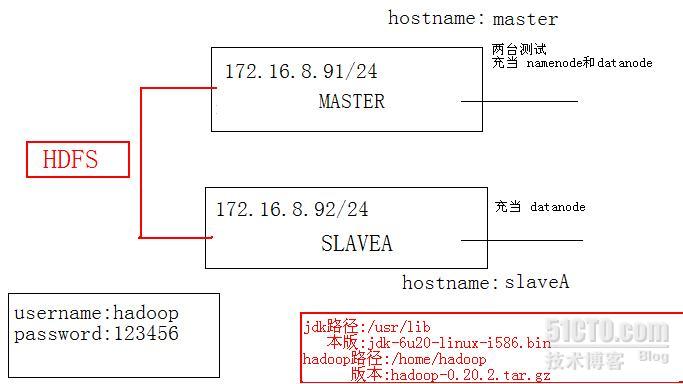
两台:
hostname:master
username:hadoop
password:123456
ipaddress:172.16.8.91/24
hostname:slaveA
username:hadoop
password:123456
ipaddress:172.16.8.92/24
一》 修改/etc/hosts 两台都做
172.16.8.91 master
172.16.8.92 slaveA
配置 ssh验证 安装不成功时刷新 新立得 包管理器
sudo apt-get install openssh-server //这里需要网络连接
ssh-keygen -t rsa -P "" //生成密钥对
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys //授权本地登录
拷贝各自的公钥到个节点之间(这里我做了双向验证)
进到hadoop用户的.ssh/文件夹下
scp *.pub slaveA:/home/hadoop/.ssh/master.pub 为了区分我们把 master的公钥保存到slaveA命名为 master.pub
scp *.pub master:/home/hadoop/.ssh/slaveA.pub 为了区分我们把 slaveA的公钥保存到master命名为 slaveA.pub
将拷贝过来的pub文件加至到各自节点的登录授权文件
cat master.pub >> authorized_keys
cat slaveA.pub >> authorized_keys
二》 安装JDK 两台都做
准备JDK 的安装包:jdk-6u20-linux-i586.bin
chmod +x jdk-6u20-linux-i586.bin //赋予执行权力
./jdk-6u20-linux-i586.bin //执行安装
换切root用户cp jdk1.6.0_20 /usr/lib //把安装目录移到/usr/lib/jdk1.6.0_20
然后ln –s /usr/lib/jdk1.6.0_20/bin/java /usr/bin/java
gedit /etc/profile //用gedit编辑器打开profile文件
在文件最后一行添加JDK的路径
export JDK_HOME=/usr/lib/jdk1.6.0_20
重启一次后测试JDK
java -version //安装成功的情况下当会出现JDK的版本等信息
至此JDK的环境变量设置完成
三》 安装 hadoop 两个节点都做
准备hadoop安装包这里我准备的是:hadoop-0.20.2.tar.gz
直接放在hadoop用户目录下直接解包
tar -zxvf hadoop-0.20.2.tar.gz
修改conf/hadoop-env.sh,设置JAVA_HOME,改为如下:
export JAVA_HOME=/usr/lib/jdk1.6.0_20
修改配置文件 cd /hadoop-0.20.2/conf
gedit master
添加
master
gedit slaves
添加
master
slaveA //这里是两台测试 master 既做namenode 又做datanode
在所有节点上修改conf/core-site.xml,更改fs.default.name的值为hdfs://master:9000,具体为:
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
在所有节点上修改conf/mapred-site.xml,将JobTracker的地址改为master具体为:
<property>
<name>mapred.job.tracker</name>
<value>hdfs://master:9001</value>
</property>
在所有节点上修改conf/hdfs-site.xml,将更改dfs.replication的值,这个参数决定了集群中一个文件需要保存为多少个拷贝。其默认值为3,因本次试验节点数为2,故更改为2。具体为:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
为了节省时间直接拷贝master上的hadoop安装包
压缩为hadoop-0.20.2.tar.gz包
scp hadoop-0.20.2.tar.gz slaveA:/home/hadoop/
进到slaveA机器
直接解压gz包
tar -zxvf hadoop-0.20.2.tar.gz
至此hadoop的配置完成
————————————————————————————————————————————————————————————————————————以下命令都在bin目录下执行,进入hadoop安装目录~/bin/
一》》
格式化 HDFS //只需在master上运行
./hadoop namenode -format
二》》
启动和停止集群
在master节点上启动HDFS
./start-dfs.sh
在master节点上停止HDFS
./stop-dfs.sh
在master节点上启动MapReduce
./start-mapred.sh
在master节点上停止MapReduce
./stop-mapred.sh
三》》
检测运行
jps //查看节点是否正常启动 需要的话需要在安装一个包——可以直接在线安装
sudo apt-get install openjdk-6-jdk
./hadoop dfsadmin -report //查看HDFS系统状态
四》》
跑 wordcount
1.准备测试文本
sudo echo“I`am the king of the world,My friend thinks” > /tmp/test.txt
2.上传文本到系统
hadoop dfs -put /tmp/test.txt systemTest
将会在系统创建文件夹 systemTest
3.开始记数
hadoop jar hadoop-mapred-examples0.21.0.jar wordcout systemTest result
4.查看输出
hadoop dfs -cat result/part-r-00000
————————————————————————————————————————————————————————————————————————


















