
System Info
uname -a 查看系统内核、位数
uname -m 查看系统位数
lsb_release -a 查看系统版本
cat /etc/issue 查看系统版本,没有lsb_release -a 详细
FileSystem
Permission: owner(u)--group(g)--others(o)
chown [username] [FileName]
chgrp [groupname] [FileName]
chmod [NewPermission] [FileName]
chmod a+x filename所有用户(u+g+o)添加x权限
chmod a-x filename所有用户(u+g+o)移除x权限
chmod g=750,o=777 filenameGroup组内用户权限设置为750,others用户权限设置为777设置第一位的权限,需要使用4个数字
4为SUID, 2为SGID, 1为SBIT
如果要让一个文件权限为-rwxr-xr-x,那么chmod 4755 filename
SUID/SGID/SBIT 权限说明
对于二进制文件,一般是一些程序比如cat, ls等
如果在user权限的x权限的位置是s,那么执行该二进制文件的时候会暂时拥有user的权限,称为SUID (Set UID)
如果在group权限的x权限的位置是s,那么执行该二进制文件的时候会暂时拥有group的权限,称为SGID (Set GID)
对于目录
如果x权限的位置是t,那么这个目录只有创建者和root可以进行删除、重命名、移动等操作,创建者不能删除其他人创建的文件 =》 也就是说t权限的目录中的文件只有创建者和root可以删除
umask 默认权限
umask: 查看默认权限,返回4个数字,数字代表需要减去的权限,例如:0002,第二位数字代表user需要减去的权限为0,也就是rwx权限都有,user的权限为7; 第三位数字代表group的权限,最后一位数字代表others的权限,需要减去2,也就是r-x,权限为5
umask -S: 返回user, group, others的权限,以rwx形式显示而非数字形式。
隐藏属性
chattr +i filename: 为filename添加i隐藏属性,i属性不能删除、重命名等,只能查看,连root也无法删除
chattr -i filename:为filename移除i属性 另一个重要的属性,a属性,a属性代表无法删除无法修改数据,只能添加数据
PS:
几个重要的组合键
Ctrl + d: 即EOF,在终端输入可以退出终端
Ctrl + z: 挂起进程,可以在之后使用fg, bg恢复进程。先使用jobs查看任务的ID,不是PID。然后fg ID切换到前台运行,或者bg ID继续后台运行。
Ctrl + c: 结束进程
Ctrl + l: 清屏,相当于clear
目录没有x权限无法进入
文件没有w权限但是所在文件夹有w权限,也可以删除文件
目录切换:
cd ~ : 进入当前用户的根目录,如果是root用户,进入 / 目录(用的是波浪号~)
cd -: 进入上一个目录,相当于后退(用的是减号-)
文件操作:
cp: 重要参数
cp -r dir1 dir2: 递归复制,用于文件夹的复制
cp -l file1 file2:进行硬链接文件的创建,为file1创建硬链接file2
cp -s file1 file2:进行软链接文件的创建,为file1创建软链接file2
cp -a file1 file2:连同文件属性一起复制(文件创建的时间等),但是inode号不一样,其实不是同一个文件取得文件路径
basename /etc/network/interfaces显示文件名 interfaces
dirname /etc/network/interfaces显示文件所在的目录 /etc/network查看文件内容
cat filename查看文件内容,从第一行开始显示 内容少的时候常用
tac filename查看文件内容,从最后一行开始显示,逆序
cat -n filename显示行号
cat -b filename显示行号,但是空白行不编号
cat -A filename显示换行符号($)、tab键(^I)
more filename只能向下查找、向下翻页,可以用‘/’搜索
less filename可以向上向下查找翻页搜索 内容多的时候常用
head -n 10 filename显示头10行,参数可以省去
head -n -10 filename后面10行不显示
tail-n 100 filename从第100行开始显示剩下的内容
tail -f filename实时更新文件内
head -n 20 | tail -n 10取出第11-20行显示,用到了管线(|)的知识,把前面head的输出作为tail的输入查找文件
which [-a] command:从PATH中查找命令所在的第一个位置,如果加上-a参数,讲返回所有找到的位置whereis 在特定的目录中查找文件,因为查找的范围小,所以速度比find要快
whereis -l:显示查找的目录范围
whereis -b filename: 查找可执行文件(二进制)
whereis filename:不添加参数,查找所有符合文件名的文件位置locate 在数据库中查找文件,速度很快。由于文件数据库并不是实时更新,所以如果查找不到文件,可以先更新数据库,更新方法如下:updatedb
locate -i filename:忽略大小写
locate -l 5 filename:列出前5个查找到的文件
locate -c filename:显示查找到的数量,不显示位置
locate -b 'filename' 具体查找文件名,不使用模糊查找find 在硬盘中搜索文件,速度最慢
find path -name filename如果path留空那就默认是当前路径文件系统的基础概念
iNode 记录文件的一些基本属性:权限、时间等,并记录了文件内容所在的block地址。(查看iNode号:ls -i)
block 存储文件内容,如果文件内容过多可以占用多个block
superblock 存储整个文件系统的信息,包括iNode总数、可用量,文件系统格式等信息
在文件夹中也有iNode和block,iNode作用和文件中的iNode一样,block用于记录该文件夹中的文件的iNode号码
查看磁盘使用情况
df -h:用适合人类阅读的方式显示磁盘使用情况
df -ih:显示iNode使用情况
ll -sh: 用于查看每个文件占用的硬盘空间软链接 硬链接
硬链接:增加一个文件名(硬链接不能link目录),使用相同的iNode号和block,所以不会增加硬盘使用量。在删除文件名的时候只要iNode号还有文件指向,就不会从硬盘中删除
ln newfile oldfile:为oldfile添加一个硬链接newfile软链接:相当于快捷方式,全新创建一个文件,使用新的iNode和block。
ln -s newfile oldfile:创建软链接磁盘操作
fdisk 用于操作mbr格式的硬盘
gdisk 用于操作gpt格式的硬盘
mkfs(make filesystem) 用于格式化,具体格式最好用相应的mkfs软件,按下mkfs[Tab][Tab]即可看到所有的mkfs软件,比如mkfs.ext4
fsck (filesystem check) 用于修复文件系统,最好使用专用的fsck软件,按下fsck[Tab][Tab]即可看到所有的fsck软件,比如fsck.ext4
mount 挂载文件系统
mount -t [文件系统类型ntfs, ext4等] -o [rw / ro] [文件系统所在目录] [挂载到哪个目录]例如:
mount -t ntfs -o ro /dev/sdb1 /mnt使用blkid命令获取到UUID后根据UUID挂载文件系统:
mount UUID=“查找到的UUID” /mnt
mount -o loop filename.iso destinationDir一般用于挂载镜像文件
umount destinationDir用于卸载 挂载在destinationDir文件夹中的文件系统创建swap分区(swap分区用于将内存中暂时不用的程序转移到swap分区中,缓解内存不足,所以swap不用太大)
新建一个分区之后使用mkswap格式化成swap分区,然后使用
swapon 设备文件名即可启动swap分区使用free查看内存使用情况,使用
swapon -s查看swap分区使用情况单一文件压缩
gzip -- 默认使用压缩比6
gzip [-cdtv#] filename各参数意义:
-c 输出压缩过程产生的数据;
-d 解压缩
-t 校验一致性,查看文件是否出错
-v 显示压缩比
-# 数字代表压缩率,9的压缩率最大速度最慢,1的压缩率最小速度最快
bzip2
bzip2 [-cdkzv#] filename各个参数意义
-c 输出压缩过程产生的数据;
-d 解压缩
-k 保留原文件不删除
-z 压缩
-v 显示压缩比
-# 数字代表压缩率,9的压缩率最大速度最慢,1的压缩率最小速度最快
xz
xz [-dtlkc#] filename各个参数意义
-d 解压缩
-t 校验一致性,查看文件是否出错
-l 列出压缩文件的相关信息
-k 保留原文件不删除
-c 输出压缩过程产生的数据
-# 压缩比率
文件夹压缩
tar
tar -zxvf file.tar.gz各个参数意义
-c 创建压缩包
-t 查看压缩包中的文件名
-x 解压 --c,t,x不能同时出现在一条命令中
-z 通过gzip进行压缩/解压缩,文件名为*.tar.gz
-j 通过bzip2进行压缩/解压缩,文件名为*.tar.bz2
-J 通过xz进行压缩/解压缩,文件名为*.tar.xz
z,j,J不能同时出现在一条命令中
-v 显示压缩/解压缩过程中的文件名
-f filename : -f后面要立刻接压缩包的文件名(*.tar.*)
-C dirName:用于在指定目录下解压
--exclude=FILE:在压缩过程中不打包FILE
仅仅解压需要的文件而非整个压缩包
tar -ztvf file.tar.gz查看压缩包中的文件名
tar -zxvf file.tar.gz filename解压压缩包中文件名为filename的文件同时选择多个目录和排除多个文件进行压缩
如果要把/etc 和 /root打包,移除/root/etc*开头的文件,可以用以下命令:
tar -zcvf file.tar.gz --exclude=/root/etc* --exclude=file.tar.gz /etc /root没有压缩过,仅仅使用
tar -cvf file.tar的文件称为tarfile。有使用压缩技术的称为tarball拷贝备份命令dd
dd if=input_filename of=output_filename bs=1M count=512其中bs是block size的意思,默认为512B(一个sector的大小),count是有多少个block的意思。if和of可以是文件名也可以是设备名(/dev/sda)
将镜像烧录到USB中,假设USB挂载为/dev/sdc
dd if=p_w_picpath.iso of=/dev/sdc
dd if=/dev/sda of=/dev/sdbdd命令会直接把扇区拷贝,因此连uuid也复制了,所以如果是磁盘间的拷贝,需要使用uuidgen这个命令重新生成uuid
vim
vim基本语法
光标移动
数字0可以移动到当前行的第一个字符,相当于home
向下移动30行:30j
移动到最后一行的开头:G
移动到第一行的开头:gg
搜索与替换
如果每次替换都需要确认,把g换成gc
向下搜索: /word
向上搜索: ?word
查找下一个: n
查找上一个: N
全局替换: :%s/old/new/g
从第n1行开始到n2行进行替换: :n1, n2s/old/new/g 注意这里是s不是%s
从第n行开始到最后进行替换: :n,%s/old/new/g
删除复制粘贴
删除光标所在的接下来的n行,不设置n代表删除光标所在行: ndd
复制光标所在的接下来的n行,不设置n代表复制光标所在行: nyy
粘贴在光标下一行: p
粘贴在光标上一行: P
将光标所在行与下一行拼接,在光标所在行最后加一个空格然后把下一行拼接起来: J
撤销与还原
撤销上一个动作: u
还原上一个动作: ctrl + r
重做上一个动作(可以是删除也可以是粘贴等等): .(小数点)
区块选择
选择整行 从当前行开始选择,之后可以上下移动光标扩大区块范围: V
选择列 :ctrl + v 选择之后可以进行删除(命令d)、复制(命令y)、粘贴(命令p)等
windows下的换行是CRLF,linux下的换行是LF,所以如果需要转换的时候,可以先安装dos2unix这个软件,然后使用下面命令进行转换:
unix2dos [-kn] file [newfile]dos2unix [-kn] file [newfile]
其中-k代表保留原文件的时间属性; -n代表保留原文件,输出到newfile中
编码格式的转换 iconv
iconv -f type -t type oldfile > newfile 可以先使用iconv --list查看支持的编码类型 -f 是from, -t 是to
查看语系设置: locale 编辑语系设置:vim /etc/default/locale
Shell & Bash
ctrl+u shell 输入小技巧 删除光标以前的所有内容; ctrl+k 删除光标以后的所有内容
bash变量定义 var=value 等号两边不能有空格
引号
双引号: 特殊字符如$会被转义
单引号: 特殊字符保持原样
反单引号(Tab上面的那个按键): 用于引用另一条指令,例如 version=`uname -r`,然后echo $version, 可以得到uname -r的输出结果
export VAR=valu 如果该变量需要在其他子程序中执行,需要export来成为环境变量。
unset var 取消变量
$( command ) 把一个或一串命令的返回值赋给一个变量
read [-pt] var 从键盘读取变量
-p: 后面接输入的提示字符串,如果没有-p那么显示空白行等待输入
-t: 后面接最大等待输入的时间,超过时间之后就会跳过这个指令
declare / typeset 设置变量的类型,二者功能用法一样
如果declare / typeset 后面没有接任何参数,就会相当于执行set,显示所有的变量(环境变量等)
declare [-aixr] var-a:把var定义为数组(array)类型
-i: 把var定义为整型(int)
declare -i var=var1+var2可以让var1和var2的值相加得到数字
$(($var1*$var2))这种用法等效于上面那种-x:把var设置为环境变量,相当于
export var-r: 把var设置为readonly类型,同时也不能unset
declare +x var:把‘-’换成'+'可以取消动作。但是如果设置了-r只读属性,只能退出bash再登录,不能取消只读属性。
数组
定义数组
arr=(val1 val2 val3)一次过定义数组的值
arr[1]=val1; arr[3]=val2为单个下标定义值,下标不需要连续。输出数组:
echo ${arr[1]}输出单个下标对应的值
echo ${arr[@]}或echo ${arr[*]}输出整个数组的值
echo ${#arr[@]}获取数组长度
echo ${#arr[n]}获取下标为n的数组元素的长度
ulimit 约束用户的行为,比如可以创建的最大容量文件、可以运行的进程数
变量删除
echo ${var#/*/}从变量var的前面开始删除两个‘/’之间的字符,#表示最短匹配,从前面开始匹配
echo ${var##/*/}跟上一个命令一样,##表示最长匹配
echo ${var%/*/}跟上一个命令类似,%表示从后面开始匹配,最短匹配
echo ${var%%/*/}跟上一个命令一样, %%表示最长匹配
变量替换
echo ${var/old/new}把var变量中遇到的第一个符合old的字符串替换成new
echo ${var//old/new}把var变量中遇到的所有符合old的字符串替换成new
变量测试与内容替换
var1=${var2-value}如果不存在var2那么var1赋值成value
var1=${var2:-value}如果不存在var2或者var2为空字符串,那么var1赋值为value
var1=${var2+value}
var1=${var2:+value}
var1=${var2=value}
var1=${var2:=value}
var1=${var2?value}
var1=${var2:?value}
命令别名
alias newCommand='oldCommand'可以用于命令简化
unalias aliasCommand用于取消命令别名 命令的执行顺序:alias > builtin > $PATH
终端历史 由于bash会在退出的时候把内存中的命令记录写入到history中,所以最后一个退出的bash的内存中的history会覆盖掉前面的
history [n]显示最近的n条命令
history -c清空当前shell中所有history记录
history [-raw] filename-a:把当前shell新增的历史加入到filename中
-r:把filename中的内容读入到当前shell的history
-w:把当前shell的记录写入到filename
!n 执行history中第n条命令 !command 执行history中最后一次出现的以command开头的命令 !!执行上一条命令
shell配置文件
配置文件的读取顺序
读取 /etc/profile
读取 ~/.bashrc
不重启直接应用新的配置文件
source 配置文件名,例如
source /etc/profile
正则表达式
[abcd]只要存在abcd中的任意一个,就接受
[0-9]从0-9的所有都接受
[^abc]只要存在不是a、b、c的任意一个字符,都接受
bash中应用到的特殊符号
#注释
|管线pipe,用于将前一个命令的输出作为后一个命令的输入
;分隔命令
&在命令最后加上这个符号可以把命令变成后台运行
>输出重定向,覆盖掉所有内容
1>把正确消息重定向输出,覆盖
2>把错误消息重定向输出,覆盖
>>输出重定向,在最后面添加
1>>把正确消息重定向输出,追加
2>>把错误消息重定向输出,追加
2>&1同时把正确消息和错误消息重定向到一个文件中
find . -name 'dota' > file 2>&1
1>&2将1>转到2>
echo "kjh" 2> /dev/null 1>&2
<输入重定向
<<输入重定向,后面接一个字符串,当输入遇到这个字符串的时候就结束
''单引号里的全部内容都视为字符
""双引号里面的内容可以进行转义,比如$是读取变量`` Tab上面的那个反撇号括住的内容为先执行的子命令
/dev/null 这个设备文件,任何写入到其中的信息都会没掉。可以用来简单的把输出消息隐藏
shell中命令的拼接
cmd1 ; cmd2在执行完cmd1后马上执行cmd2
cmd1 && cmd2若cmd1正确执行则执行cmd2判断上一条命令是否正确执行:
echo $?若正确执行返回0
cmd1 || cmd2若cmd1正确执行则不执行cmd2
管线pipe( | )
cmd1 | cmd2管线机制,把cmd1的输出作为cmd2的输入撷取命令 cut 和 grep
cut -c start-end用于排列信息,只截取第start个字符到第end个字符,如果为空表示从start=开头或者end=结束。20- 表示从第20个字符到结束, 10-20表示截取第10到第20个字符
cut -f '分割字符' -f fields按照'分割字符'为标准进行分割,选取fields中的段数。 -f 3 表示选取第3段, -f 3,5 表示选取第3和第5段
grep [-acinv] 'string' filename-a:将binary文件按照text文件的方式搜索
-c:计算找到的次数
-i :大小写不敏感
-n:输出行号
-v :反向选择,输出没有出现的行
排序、计数、去重
sort [-fbMnrtuk] [filename or stdin]-f: 大小写不敏感
-b: 忽略最前面的空白字符
-M: 以月份的名字排序
-n: 使用“纯数字”进行排序(默认使用文字体态排序)
-r: 反向排序
-u: 去重,相当于uniq
-t: 设置分隔符号,默认使用Tab
-k: 在指定区间进行排序
cat /etc/passwd | sort -t ':' -k 3数据以‘:’分隔,以第三段数据进行排序
uniq [-ic]去重
uniq -i大小写不敏感
uniq -c计数
wc [-lwm] filename文件中的内容计数
wc -l filename对filename中的内容计数,只显示行数
wc -w filename对filename中的内容计数,只显示单词数
wc -m filename对filename中的内容计数,只显示字符数
wc filename:显示行数、单词数、字符数
同时重定向输出和屏幕输出
tee [-a] file: 既在屏幕输出也重定向到file。如果加上 -a 参数,则是追加到file中
字符转换命令
tr [-ds] str1...-d: 删除信息中的str1这个字符串
-s: 取代重复的字符
last | tr '[a-z]' '[A-Z]'所有小写替换为大写
cat /etc/passwd | tr -d ':'删除所有‘ : ’
cat ms_file | tr -d '\r' > linux_file把DOS文件中的‘^M’符号删掉
文件分割
当文件容量太大时,可以使用split命令分割成几个小文件
split [-bl] file PREFIX-b:后面接容量单位(b, k, m, g等)
-l:不以容量为单位分割,以行数为单位进行分割
PREFIX:子文件的文件名前缀
split -b 300k file newfile把file按照300k一个子文件的标准进行分割,子文件前缀名为newfile,后缀默认为aa开始编号,ab>ac...
sed用法
sed [-nefr] [动作]-n:只在屏幕中输出sed处理的行,不显示其他东西。(silent模式)
-e: 在命令行中编辑sed动作,如果只有一个动作,可以不加-e参数,但如果有多个动作,动作之间需要用-e衔接
-f:把sed的动作写入一个文件内。
-f filename可以执行filename内的sed动作-r: 使用正则表达式
-i: 从文件中获取输入而非从屏幕中通过管线获取
动作说明: [n1[,n2]]function 代表对n1-n2区间的行执行function动作
function动作包含:
a:添加[add],在指定行的下一行添加
cat file | sed '1a new content'在第一行后面添加new content内容使之成为第二行c:替换,把指定区间的内容替换掉
d:删除
cat file | sed '2,5d'删除2-5行i:插入,在指定行插入内容
p:打印,显示在屏幕中。通常与-n一起使用
cat file | sed -n '2,6p'打印2-6行s:替换,查找指定的字符串进行替换
cat file | sed '1,5s/old/new/g'类似vim的替换命令,如果没有指定行数,将进行全局的替换
sed -i ‘$a add something to the end’ file由于$代表最后一行,所以这个命令表示往file文件中的末尾添加一行,内容是'add something to the end'
这里用到了 -i 用于直接对文件操作而非通过管线机制从屏幕输入
printf格式化打印输出
printf '%s\t %10s\t %8.2f %5i \n' $ (cat file)
%10s 表示长度为10个字符的字符串
%5i 表示长度为5个字符的数字
%8.2f 表示长度为8个字符的有两位小数的浮点数
注意,print和printf不一样,print不能控制输出格式
awk用法
sed常使用于整行的处理,awk常用于把一行分成几个字段处理。
awk的命令可以理解为对每一行的数据执行命令,每一行的数据输入之后都会重新运行一次awk命令,每一行都是独立的
awk '条件类型1{动作1} 条件类型2{动作2} ...' filenameawk 内置变量
NF: 每一行(也就是$0)拥有的字段总数
NR: 目前awk所处理的是第几行的数据
FS: 目前的分隔字符,默认是空格
awk默认使用的是单引号括住所有动作,动作需要用{}括住,条件可以为空
last -n 5 | awk '{print $1 "\t" $3}'这个命令把指定的字段打印出来,是常用用法之一。$1代表第一个变量,$0代表整行
cat /etc/passwd | awk '{FS=":"} $3 < 10 {print $1 "\t" $3}'这里用到了条件$3 < 10,如果是判断相等,像c语言一样用两个'='这里第一行的分隔符还是用了默认的空格,从第二行才开始使用“:”作为分隔符
cat /etc/passwd | awk 'BEGIN {FS=":"} $3 < 10 {print $1 "\t" $3}'把BEGIN作为条件,可以初始化一些变量,同理,可以把END作为条件如果在动作中有多个命令,可以使用分号';'进行分隔
文件差异比对
diff
用于比较文本差异,逐行对比。
diff [-bBi] from_file to_filefrom_file 原始比对文本
to_file 目的比对文本
-b:多个空格当作一个,所以如果是两个单词之间的空格数量不同,那么在这个模式下是没有差异的
-B:忽略空白行的差异
-i:大小写不敏感
cmp
cmd用于对字节进行比对,可以用于binary文件的比对
cmp [-l] file1 file2-l : 把所有不同的字节列出来。如果没有的话默认只输出第一个发现的不同点。
Shell脚本语言
echo用法
echo -e "format output\n" 加上-e后可以格式化输出
算术运算
echo "123.456*456.123" | bc 用于把计算结果保留3位小数
time echo "scale=100;4*a(1)" | bc -l
计算圆周率PI,当scale很大的时候可以让CPU高负载
bash脚本的执行方法
sh script.sh或bash script.sh或./script.sh都是在终端中另外开启一个bash程序执行。最后一个./ 是运行当前目录的script.sh的意思
source script.sh直接在当前终端中运行脚本,脚本中的变量可以在终端中找到
test 判断
测试结果为真,返回0,否则返回非0
test -[efdbcSpL] filename-e:测试filename是否存在
-f:测试filename是否存在且是不是一个文件
-d:测试filename是否存在且为一个目录
-b:测试filename是否存在且为一个block device设备
-c:测试filename是否存在且为一个character device 设备
-S:测试filename是否存在且为一个Socket文件
-p:测试filename是否存在且为一个FIFO(pipe)文件
-L:测试filename是否存在且为一个链接文件
test -[rwxugks] filename-r:测试filename是否存在且具有可读权限
-w:测试filename是否存在且具有可写权限
-x:测试filename是否存在且具有可执行权限
-u:测试filename是否存在且具有SUID的属性
-g:测试filename是否存在且具有SGID的属性
-k:测试filename是否存在且具有Sticky bit的属性
-s:测试filename是否存在且为非空文件
test file1 [option] file2option有以下3种-nt:测试file1是否比file2新
-ot:测试file1是否比file2旧
-ef:测试file1和file2是否为同一文件。根据两个文件是否指向同一个inode
test num1 [option] num2option有以下6种-eq:测试num1和num2是否相等(equal)
-ne:测试num1和num2是否不相等(not equal)
-gt:测试num1是否大于num2(greater than)
-lt:测试num1是否小于num2(less than)
-ge:测试num1是否大于等于num2(greater than or equal)
-le:测试num1是否小于等于num2(less than or equal)
字符串的判定
test -z $string$string为空,不存在,返回0
$string非空,返回1
test $string$string非空,返回0
$string为空,不存在,返回1
test $str1 == $str2$str1和$str2相等,返回0
$str1和$str2不相等,返回1
变量和'=='之间需要有空格
test $str1 != $str2$str1和$str2不相等,返回0
$str1和$str2相等,返回1
变量和'!='之间需要有空格
test -r filename -a -x filename多个条件“与”之间使用-a连接(and)
test -r filename -o -x filename“或” 使用 -o 连接
test !-r filename使用‘!’取反
使用判断符号'[]',代替test关键字
[ -z "${HOME}" ]中括号与命令之间一定要有空格
变量最好使用双引号括起来,以防变量内容包含空格
脚本运行参数
/path/to/scriptname opt1 opt2 opt3 opt4
$0 -> /path/to/scriptname
$1 -> opt1
$2 -> opt2
...
特殊变量
$#:代表执行脚本后面带有的参数个数,上例的 $# 为4
$@:代表
"$1" "$2" "$3" "$4"其中各个变量独立的,使用双引号括起来$*:代表
"$1"<u>c</u>"$2"<u>c</u>$3<u>c</u>$4其中<u>c</u>是分隔符,默认是空格
shift n去掉前n个参数在脚本中直接输入而不使用中间变量:
--stdin例如:
echo 'password' | passwd --stdin username可以把屏幕输出的password读入到stdin中作为username的密码
条件语句
如果是简单的条件语句,可以使用 && 或者 ||即可,其中&&表示当前面一条命令的执行结果$?为0(前一条命令成功执行)时执行后面的命令, ||相反
if [ condition ]; then statements;fi
条件判别式的写法与前面介绍test的一样,可以在一个中括号里面写多个条件,使用-a 或者 -o 来连接,此外,还可以用多个中括号,中括号之间使用 && 和 || 进行连接
[ condition1 -a condition2 ]
[ condition1 ] && [ condition2 ]
if [ condition1 ]; then statements;elif [ condition2 ]; then statements;else statements;fi
case $var in case1) statements; ;; case2) statements; *) statements; exit 1; ;;esac
function f() { }函数要先定义后使用,因为bash 脚本是从上到下运行的解释型语言
调用的时候直接使用函数名,不需要括号。如果有参数,就像执行bash脚本的时候一样,直接在函数名之后空格然后加参数。例如: f opt1 opt2; 函数的参数也是以函数名为$0,然后递推
while [ condition ]do statements;done
while循环是当条件成立时,继续
until [ condition ]do statements;done
until循环是当条件成立时,结束
for $var in con1 con2 con3 ...do statements;done
第一次循环时,$var=con1 第二次循环时,$var=con2 第三次循环时,$var=con3
对1-100进行循环:
for num in $ (seq 1 100)do statements;done
对a-g进行循环:
for ch in {a..g}do statementsdone对于连续的,可以用seq,也可以用两个点'.'
另一种for循环
for (( init; condition; process ))do statements;done
获取随机数:${RANDOM}
shell 脚本的debug
bash [-nvx] script.sh-n:不执行script.sh,仅仅查询语法问题
-v:先把script.sh的内容输出到屏幕中再执行
-x:将使用到的scrpit内容显示到屏幕中,会把每一行执行到的命令显示出来
用户管理
添加用户、移除用户
useradd username其他复杂的设置暂时不管了
passwd [username]创建完用户之后需要赋予密码才可以使用。如果username留空,则修改当前用户的密码
usermod修改用户信息
userdel [-r] username删除用户, -r 参数可以把该用户的主文件夹也删除
RAID
RAID1+0
先组成RAID1,两两一组,作为镜像,然后组成RAID0,用于stripe(平均分摊存储任务)
RADI0+1
先组成组成RAID0,用于stripe(平均分摊存储任务),然后一共两组,作成一个RAID1,作为镜像
RAID1+0和RAID0+1性能一样,不过容错率1+0更高,因为0+1只有2个组,如果各有一个磁盘损坏就无法修复;1+0有多个组(两两一组),容错率更高
进程管理
ps 静态查看进程状况
ps -ef | grep processname查看进程名为processname的状况
top 动态查看进程状况
top -d num [-bnp]
-d num:num秒刷新一次
-p pid1 pid2 ...: 指定观察PID在top中可以使用以下按键指令:
?:显示可以下达的按键指令
P:以CPU占用排序
M:以内存占用排序
N:以PID排序
T:以占用CPU时间排序
q:退出
资源查看
内存资源查看
free [-hbkmg]-h:以人类最舒服的形式显示(看的最舒服的)
-m:以MB单位显示
网络资源查看
netstat -[atunlp]-a:将目前系统上所有的连线、监听、Socket数据列出来
-t:列出tcp数据
-u:列出udp数据
-n:以端口号显示,不以程序的服务名称显示
-l:列出目前正在listen的服务
-p:列出PID
查看内核产生的信息
dmesg | less
查看系统资源变化
vmstat [-a] [多少秒更新一次 [一共侦测几次]]显示CPU/内存等信息-a:使用inactive/active 代替 buffer/cache (内存输出信息)
如果没有多少秒更新一次,则只更新1次
如果没有一共侦测几次,则一直侦测下去
vmstat [-fs]内存相关-f:开机到目前为止,系统复制(fork)的进程数
-s:将开机到现在的内存变化情况 列表说明
vmstat [-S 单位]设置显示数据的单位-S:默认为Bytes,可以设置为K / M
vmstat [-d]磁盘相关-d:列出磁盘的读写总量统计表
vmstat [-p 分区1 分区2...]磁盘相关-p:后面列出分区,课显示改分区的读写总量统计表
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 6684 1003384 693016 2557356 0 0 27 23 97 372 2 1 97 0 0
各字段意义:
procs(程序字段)
r:等待运行的程序数量
b:不可被唤醒的程序数量
memory字段
swpd:虚拟内存使用容量
free:未使用的内存容量
buff:用于缓冲的内存
cache:用于高速缓存的内存
swap字段
si:由磁盘中将程序取出的量
so:由于内存不足而需要将暂未使用的程序写入到磁盘swap的容量
如果si/so比值太大,表示内存中的数据经常在磁盘和内存之间传来传去,系统性能低下
io字段
bi:由磁盘读入的区块数量
bo:写入到磁盘去的区块数量
这两个值越高,系统的I/O越忙碌
system字段
in:每秒被中断的程序次数
cs:每秒钟进行的事件切换次数
这两个数值越大,代表系统与周边设备(磁盘、网卡、时间钟等)的沟通越频繁
cpu字段
us:非内核层的CPU使用状态
sy:内核层使用的CPU状态
id:限制的状态
wa:等待I/O所耗费的CPU状态
st:被虚拟机占用的CPU使用状态
/proc 文件夹
内存当中的数据写入到/proc文件夹。其中
数字为目录名: 数字就是PID
在PID目录下的cmdline保存的是启动这个进程使用的命令
在PID目录下的environ保存的是这个进程的环境变量
查询目录被占用情况
fuser [-umv] filename/dirname可以用于解决在umount的时候遇到 ‘device is busy’-u:除了列出正在使用当前文件/目录的PID外,同时列出该程序的拥有者
-m:后面接的文件名会主动的上提到该文件系统的最顶层(如果umount失败常用)
-v:可以列出每个文件与程序还有指令的完整相关性
lsof [-aUu] [+d]-a:多项数据需要同时成立才显示出结果
-U:仅列出Unix like系统的socket 文件类型
-u:后面接username,列出该使用者相关程序所打开的文件
+d:后面接目录,用于找出该目录下已经被打开的文件
lsof: 列出目前系统上面所有已经被打开的文件与设备
查询进程的PID
pidof [-sx] program_name
-s:仅列出一个PID
-x:同时列出该program_name 可能的PPID
主要用于知道一个程序的名字想要知道pid,也可以用ps -ef | grep program_name 代替
SELinux ( Security Enhanced Linux )
SELinux 控制的主体是程序,而目标是该程序是否能够读取的“文件资源”
可以为程序对文件目录另外设置权限,而非只针对用户和群组
ps -eZ查看程序的权限情况unconfined 代表不受限
SELinux的三种运行模式
Enforcing 正常开启
Permissive 仅仅给出警告,不会进行限制
Disabled 关闭
系统服务daemons(读作'd mens)
damon就是在后台运行的service
daemon是一个程序A执行后得到的程序B,程序A的命名是(服务名+d),就如httpd。d代表daemon的意思
服务的启动脚本全部放于
/etc/init.d/下面,基本都是bash脚本。/etc/init.d/daemon start
/etc/init.d/daemon restart
/etc/init.d/daemon stop
/etc/init.d/daemon status
服务的启动等级为0-6,S,对应到/etc/rcx.d 其中x为级别
rcS.d的服务脚本只在开机的时候运行一次,其他可以手动运行停止
systemctl这个命令很复杂,可以用来管理服务、系统,要用的时候再看帮助
systemctl status service_name查看是否开启,还可以使用start/stop/restart操作systemd 的服务类型
.service : 一般的服务类型,主要是系统服务
.socket : socket服务,一般开机会延迟启动
.target : 服务的集合,执行一个.target就是执行了一个服务的集合
.mount / .automount : 文件系统挂载相关服务
.path : 侦测特定目录,比如打印的时候需要侦测打印伫列目录来启动打印功能
.timer : 循环执行的服务
查看当前启动的服务
service --status-all查看所有服务的启动状态
systemctl list-units --type-service --all查看所有服务的启动状态
systemctl status service_name.service查看service_name的启动状态第二行的最后一个字段enabled代表开机启动,disabled代表开机不启动
查看服务之间的依赖
systemctl list-dependencies [--reverse]--reverse 反向追踪使用情况,父项目会被子项目使用
systemctl list-dependencies graphical.target [--reverse]查看graphical.target使用了多少服务,加了 --reverse 就是反过来
对系统进行重启、关机、休眠、进入救援模式等
systemctl reboot具体看帮助查看端口与服务的对应关系
cat /etc/service
日志记录
日志保存在/var/log目录下
boot.log 本次开机启动的时候的记录
dmesg 开机时候内核侦测过程产生的记录
为避免日志过大,系统会自动把大文件重命名,然后创建一个新文件用于记录日志,旧日志保存一段时间后删除。也可以手动进行这项工作:
logrotete
logger -p syslog.info "content"用于把content这个内容保存到syslog中,日志等级为info
系统启动
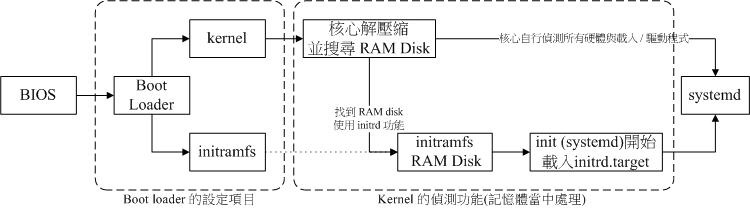
开机后读取磁盘第一个扇区的boot loader (grub2):BIOS通过INT 13 这条信道来读取boot loader
boot loader 读取内核,启动内核一般命名为: /boot/vmliunz-*
内核通过挂载虚拟文件系统来载入驱动(磁盘驱动等)
Initial RAM Disk(initrd):使用的文件名为
/boot/initrd-\*Initial RAM Filesystem(initramfs):使用的文件名为
/boot/initramfs上面这两个文件可以通过boot loader载入到内存中,然后仿真成一个根目录,然后在这个文件系统中有一个可执行程序用来载入开机需要的内核模块(UBS、RAID、LVM、SCSI等文件系统与磁盘接口的驱动程序),载入完成后帮助内核重新调用systemd来开始后续的正常开机流程
模块
/etc/modules-load.d/*.conf这里的配置文件仅仅只能让内核载入模块,不能添加载入模块的附加参数
/etc/modprobe/*.conf可以加上模块参数
lsmod查看加载成功的模块
/lib/modules/version/kernel存放内核模块
/usr/src/linux-存放内核的源码如果内核成功加载
cat /proc/version查看内核版本
ls /proc/sys/kernel查看系统内核的功能内核模块的载入与移除 (insmod / modprobe)
insmod [/absolute/path/module_name] [parameters]载入模块,必须要是绝对路径
rmmod [-fw] module_name移除模块-f:强制移除
modprobe [-cfr] module_name不需要路径,只需要模块名-c:列出目前系统所有的模块
-f:强制加载
-r:移除
如果不带参数就是用一般的方式加载
Boot loader (grub2)
由于boot loader 安装在磁盘第一个扇区,大小有限,所以boot loader的启动分成两个阶段
执行boot loader 主程序,主程序安装在boot sector (磁盘第一个扇区)
boot loader 主程序加载配置文件(grub.cfg)以及其他相关的文件,一般都放置于 /boot。与grub2相关的文件放置于 /boot/grub
grub2对磁盘的识别方法
(hd0,1) 识别到的第一块硬盘是0 (对应sda),第一个分区是1
(hd0,msdos1) MBR模式的分区
(hd0,gpt1) GPT模式的分区
如果需要配置grub,在
/etc/default/grub中修改,然后使用update-grub更新到grub.cfg使用
update-grub之后,会调用/etc/grub.d里面的一些可执行文件用于生成新的grub.cfg00_header: 创建初始界面
10_linux: 分析 /boot 下面的文件,找到正确的linux内核与读取这个内核需要的文件系统模块与参数
30_os-prober: 寻找其他分区可能含有的操作系统,添加到操作系统选择菜单
40_custom: 自定义的菜单项目
/etc/default/grub在这里可以修改开机界面
[optional] 通过 chainloader 移交控制权
假设要从grub引导 windows 系统启动,那么可以通过 chainloader 让 grub 把控制权交给 windows 的 loader
grub2 安装
grub2-install [--boot-directory=DIR] INSTALL_DEVICE
--boot-directory=DIR表示在DIR(目录名,需要实际指定,默认值是/boot/grub/*)
INSTALL_DEVICE表示安装到哪个磁盘(/dev/sda)
软件安装
configure && make
调用configure 会生成一个 makefile, 然后使用make 进行编译
动态和静态函数库
静态函数库
文件扩展名(.a),通常文件名为 libxxx.a
使用静态函数库编译生成的文件比较大,是直接把函数库整合到可执行程序中
优点: 生成的可执行文件可以独立执行,不再需要读取函数库
动态函数库
文件扩展名(.so), 通常文件名为 libxxx.so
编译时通常是使用一个指针指向动态函数库,没有直接整合到可执行程序中,生成的文件比较小
生成的程序无法独立执行
一般会把动态函数库加载到内存中来加速动态函数库的读取速度
验证程序的正确性
常用的校验方法有
md5sum
sha1sum
sha256sum
md5sum/sha1sum/sha256sum [-bct] filename-b: 使用binary方式读取filename,默认为windows/DOS
-c: 校验文件指纹信息
-t: 以文本形式读取文件指纹
md5sum/sha1sum/sha256sum [--status || --warn] --check filename
X 图形界面
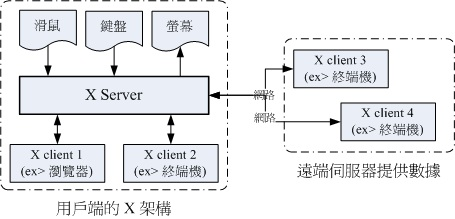
X Server: 硬件管理、屏幕绘制、提供字体功能
X Client: 负责处理 X Server 要求的事件。接收 X Server 的动作事件,返回产生绘图的数据。因此, X Client 也叫作 X Application
这种网络架构的好处: X Client 不需要知道怎么绘图,只需要传递数据
启动X
startx
X :1启动第一个X (从第0个开始计数)
xterm -display :1启动可以在X当中执行的虚拟终端机
配置 X
/etc/X11/xorg.conf.d/在这个目录下创建 .conf 文件进行配置
Section "section name" configurationEndSection
Xorg -configure生成一个新的 xorg.conf.new
xrandr测试目前屏幕搭配显卡能够处理的分辨率和刷新率
xrandr -s 1920x1080调整分辨率
gtf 1920 1080 75 [-xv]获得调整此分辨率和刷新率所需的命令-x: 使用Xorg配置文件的模式输出
-v: 显示过程
Modeline "1920x1080_75.00" 220.64 1920 2056 2264 2608 1080 1081 1084 1128 -HSync +Vsync返回值把gtf返回的命令写入到/etc/X11/*.conf 内的 Monitor 项目中 即可应用新分辨率和刷新率
Section "Monitor" Identifier "Monitor0" VendorName "Monitor Vendor" ModelName "Monitor Model" Modeline "1920x1080_75.00" 220.64 1920 2056 2264 2608 1080 1081 1084 1128 -HSync +VsyncEndSection
然后重新启动X
[alt] + [ctrl] + [backspace]
安装显卡驱动
lspci | grep -Ei 'vga | display | 3d controller'查看显卡型号
vim /etc/modprobe.d/blacklist.conf禁用nouveau在末尾添加
blacklist nouveauoptions nouveau modeset=0


















