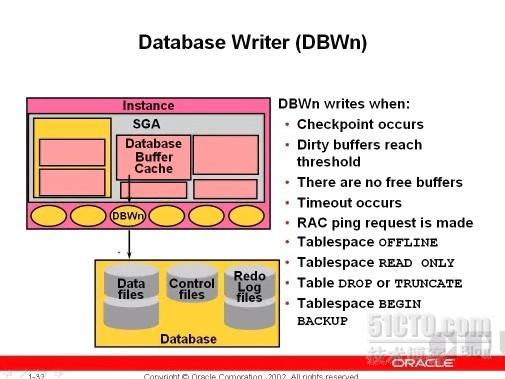
LGWR:
把log_buffer中的日志条目从log_buffer中写入日志文件,写完后,释放log_buffer空间,server进程负责把每一个用户的sql命令写入log buffer,日志条目并不是简单sql语句,而是oracle会把他用户的一些sql或命令翻译成日志条目,
检查点发生的时候会导致DBWR写,从而导致LGWR写
另外由于REDO LOG 在磁盘上是连续的块,所以LGWR写的时候是顺序写,而DBWR写数据文件是离散写,比较慢!寻道比较多!!
log file sync事件 -AWR

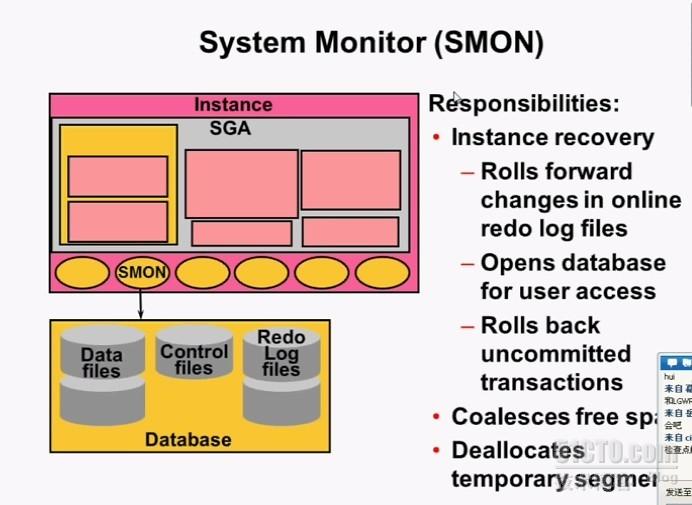
SMON:
实例恢复:实例异常中断、主机断电、shutdown abort
首先前滚,重做应用redo log files里的操作 ,然后open 数据库,再回滚(回滚那些未提交的事务)
介质恢复:磁盘损坏、磁道损坏、阵列损坏、数据文件误删
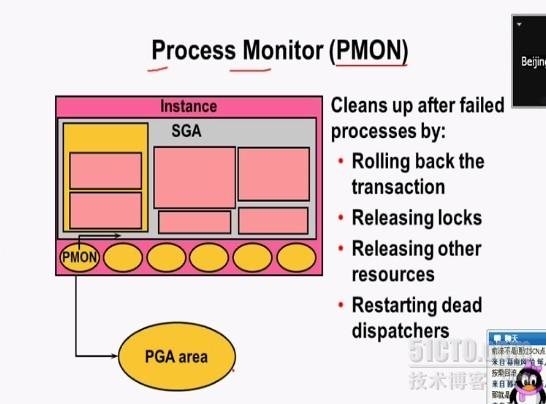
PMON:
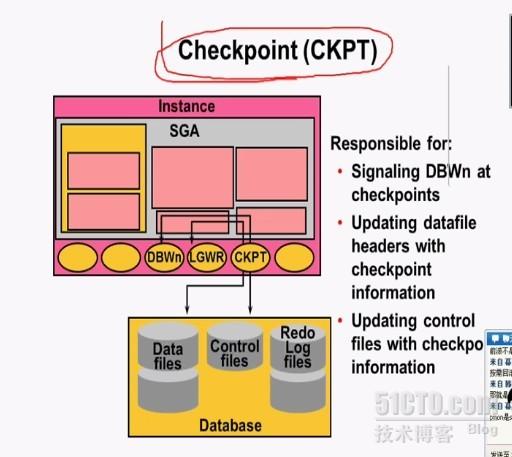
CKPT:检查点,oracle用它来定位从什么地方开始做recovery,实例恢复从上一次发生检查点(在redo log file中从目前的start SCN开始)的地方开始做recovery。检查点进程周期性运行,主要用来把数据库当前状态信息写入控制文件中与数据文件头部。
1、完全检查点:会触发DBWR把所有脏块写入磁盘(一般在正常关闭数据时会发生)
2、增量检查点:发生时,CKPT进程会把检查点队列对应的第一个最早的脏块所对应的LRBA日志地址记录到控制文件中(3秒发生一次)
RBA:修改块所产生的重做日志地址
LRBA:脏块第一次(最早)被脏的日志地址
HRBA:块被脏了很多次,最后一次(最近)被脏的日志地址
on disk rba:cruuent日志里最新的日志地址
检查点队列与增量检查点,它们的主要目的就是让DBWn沿检查点队列的顺序刷新脏块。还有,就是实例恢复。
因为每次完全的checkpoint都需要把buffer cache所有的脏块都写入到数据文件中,这样就是产生一个很大的IO消耗,频繁的完全checkpoint操作很对系统的性能有很大的影响,为此Oracle引入的增量checkpoint的概念,buffer cache中的脏块将会按照BCQ队列的顺序持续不断的被写入到磁盘当中,同时CKPT进程将会每3秒中检查DBWn的写入进度并将相应的RBA信息记录到控制文件中。
有了增量checkpoint之后在进行实例恢复的时候就不需要再从崩溃前的那个完全checkpoint开始应用重做日志了,只需要从控制文件中记录的RBA开始进行恢复操作,这样能节省恢复的时间。
SCN与checkpoint number:
SCN:system change number 用来标识事务的先后顺序,在oracle中,一般的号都来自SCN号,检查点号也来自SCN号,当检查点发生的时候,那个点的检查点号就等于那个点的SCN号,
1、select dbms_flashback.get_system_change_number() from dual;
select current_scn from v$database; 查询系统当前SCN命令
2、select name,checkpoint_change# from v$datafile; 当前数据文件SCN.在控制文件中。即checkpoint scn,表示该数据文件最近一次执行检查点操作时的SCN
3、select name,last_change# from v$datafile; 数据文件结束SCN,在控制文件中。LAST_CHANGE#,如果数据库非正常关闭值为NULL.正常关闭是关闭时的SCN. 实例恢复就是在打开数据库时检查此参数确定是否需要恢复。 数据库OPEN时LAST_CHANGE#也为NULL,因为不确定SCN多少时关闭。
4、select dbid,checkpoint_change# from v$database;数据库全局-检查点 SCN,在控制文件中
5、select name,checkpoint_change# from v$datafile_header; 查询数据文件头SCN,在数据文件头
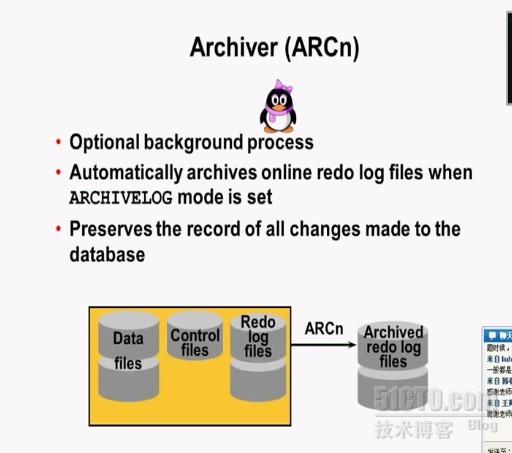
Archiver(ARCn):归档进程
DBWn:把数据缓冲区里的脏数据块写入数据库文件