
CDH 6.3.2 集成 kylin 的部署与使用
标签(空格分隔): 大数据运维专栏
- 一:关于kylin的介绍
- 二:安装环境介绍与软件包的准备
- 三: 配置kylin 与 CDH 6.3.2集成
- 四: kylin 的测试
- 五: kylin 自建表导入数据测试
一:关于kylin的介绍
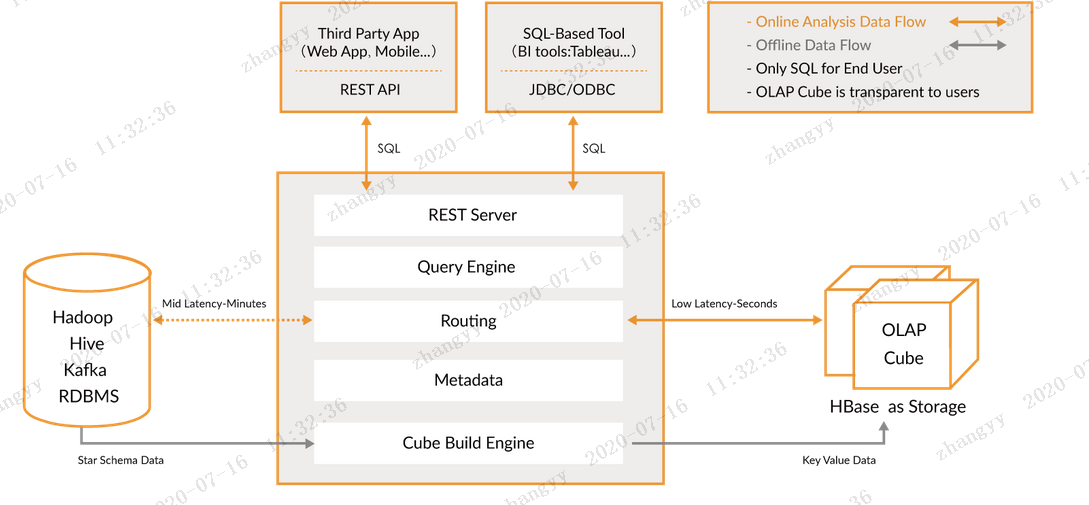
1.1 Apache Kylin™ 概览
Apache Kylin™是一个开源的、分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区。它能在亚秒内查询巨大的表。
Apache Kylin™ 令使用者仅需三步,即可实现超大数据集上的亚秒级查询。
1 定义数据集上的一个星形或雪花形模型
2 在定义的数据表上构建cube
3 使用标准 SQL 通过 ODBC、JDBC 或 RESTFUL API 进行查询,仅需亚秒级响应时间即可获得查询结果
Kylin 提供与多种数据可视化工具的整合能力,如 Tableau,PowerBI 等,令用户可以使用 BI 工具对 Hadoop 数据进行分析。
参考官网:
http://kylin.apache.org/cn/
##二:安装环境介绍与软件包的准备
2.1 安装系统环境
系统:CentOS7.5x64
CDH 版本: cdh 6.3.2
jdk 版本: jdk1.8
cat /etc/hosts
---
192.168.11.37 test01.lanxintec.cn
192.168.11.38 test02.lanxintec.cn
192.168.11.40 test03.lanxintec.cn
---
2.2 kylin 版本
2.2.1 kylin v3.1.0
v3.1.0
这是 3.0.0 版本后的一个主要版本,包含10个新功能和142个问题的修复以及各种改进。关于具体内容请查看发布说明.
发布说明, 安装指南 and 升级指南
源码下载: apache-kylin-3.1.0-source-release.zip [asc] [sha256]
Hadoop 2 二进制包:
for HBase 1.x (includes HDP 2.3+, AWS EMR 5.0+, Azure HDInsight 3.4 - 3.6) - apache-kylin-3.1.0-bin-hbase1x.tar.gz [asc] [sha256]
for Cloudera CDH 5.7+ - apache-kylin-3.1.0-bin-cdh57.tar.gz [asc] [sha256]
Hadoop 3 二进制包:
for Hadoop 3.1 + HBase 2.0 (includes Hortonworks HDP 3.0) - apache-kylin-3.1.0-bin-hadoop3.tar.gz [asc] [sha256]
for Cloudera CDH 6.0/6.1 (check KYLIN-3564 first) - apache-kylin-3.1.0-bin-cdh60.tar.gz [asc] [sha256]
三: 配置kylin 与 CDH 6.3.2集成
3.1 下载kylin
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kylin/apache-kylin-3.1.0/apache-kylin-3.1.0-bin-cdh60.tar.gz
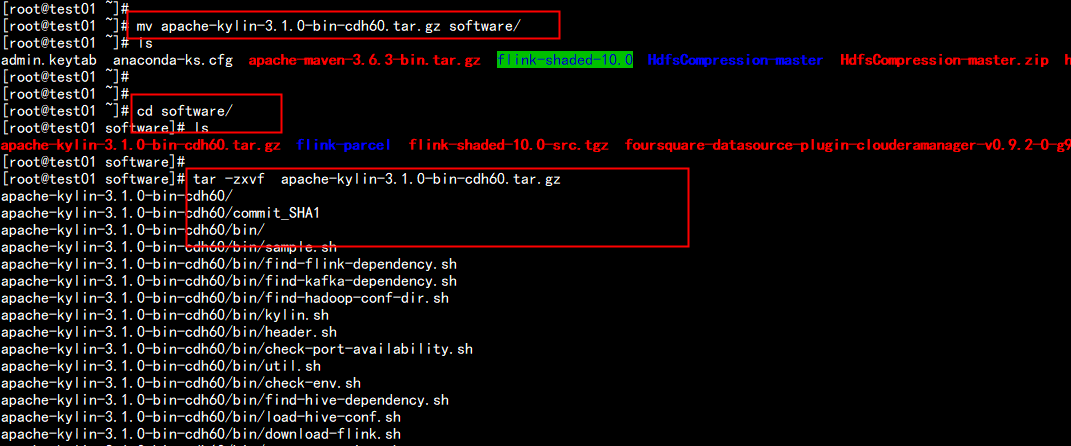
mv apache-kylin-3.1.0-bin-cdh60.tar.gz software/
3.2 安装启动kylin
mkdir -p /opt/bigdata/
cd software
tar -zxvf apache-kylin-3.1.0-bin-cdh60.tar.gz
mv apache-kylin-3.1.0-bin-cdh60 /opt/bigdata/
cd /opt/bigdata/apache-kylin-3.1.0-bin-cdh60
bin/kylin.sh start
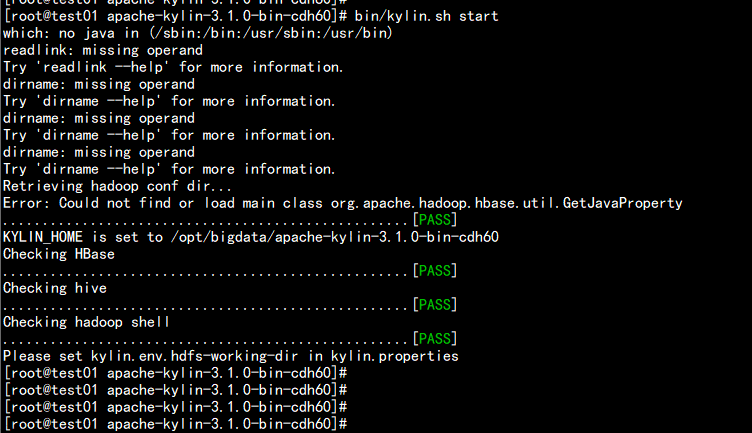
报错:
Error: Could not find or load main class org.apache.hadoop.hbase.util.GetJavaProperty
解决:
vim /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hbase/bin/hbase
----
在169 行: 加上hbase lib
CLASSPATH="${HBASE_CONF_DIR}"
CLASSPATH=${CLASSPATH}:$JAVA_HOME/lib/tools.jar:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hbase/lib/*
----

vim /etc/profile
到最后加上:
---
### set spark home and kylin home and kafka home
export SPARK_HOME=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark
export KAFKA_HOME=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/kafka
export FLINK_HOME=/opt/cloudera/parcels/FLINK/lib/flink
export KYLIN_HOME=/opt/bigdata/apache-kylin-3.1.0-bin-cdh60
---
若没有集成请集成安装 flink 与安装 kafka
cd /opt/bigdata/apache-kylin-3.1.0-cdh60/
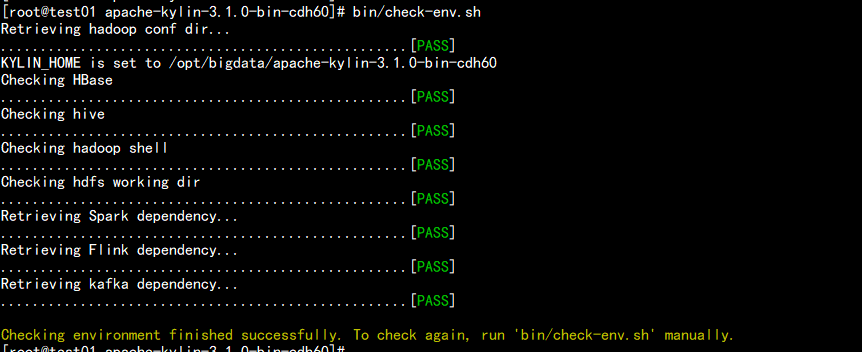
bin/check-env.sh
保证所有环境都是pass 状态
启动kylin
bin/kylin.sh start
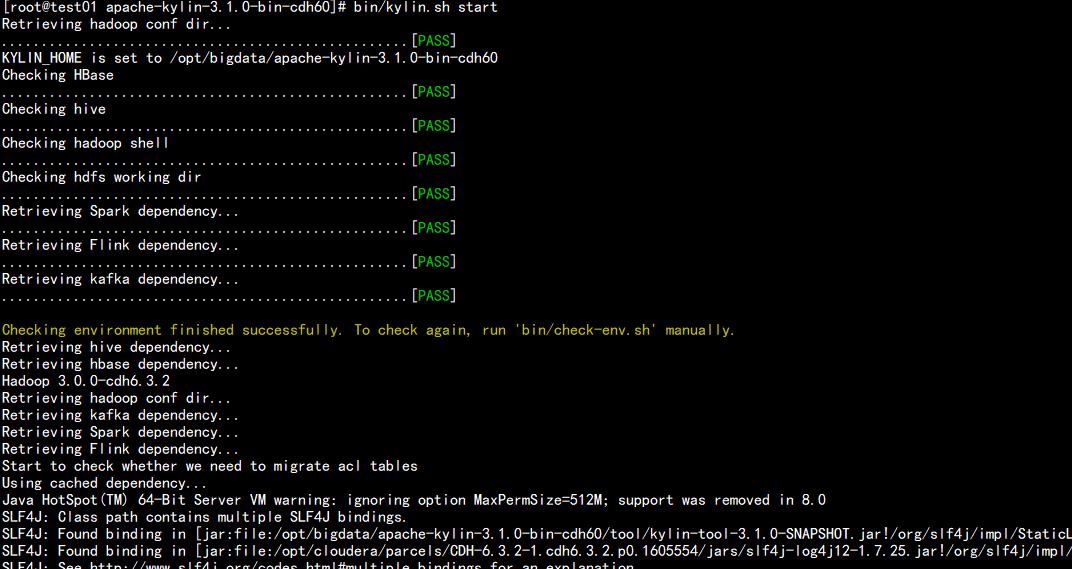
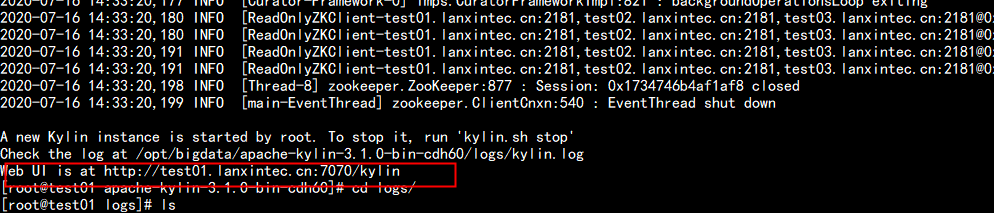
查看logs目录
cd /opt/bigdata/apache-kylin-3.1.0-cdh60/logs/
tail -f kylin.log
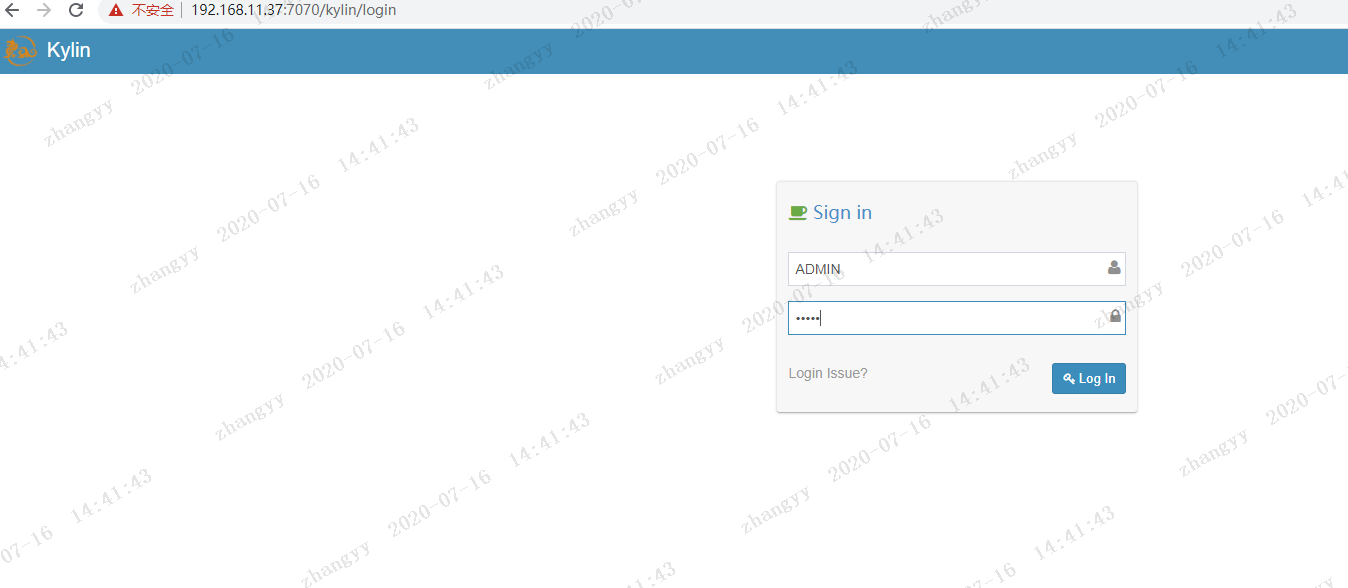
打开web 也没
http://192.168.11.37/kylin/
用户名:ADMIN 密码:KYLIN (用户名密码都是大写)
四:运行kylin 的测试用列
4.1: 运行kylin的用列
4.1.1 启动sample.sh
cd /opt/bigdata/apache-kylin-3.1.0-cdh60/bin/
./sample.sh
从启kylin
cd /opt/bigdata/apache-kylin-3.1.0-cdh60/bin
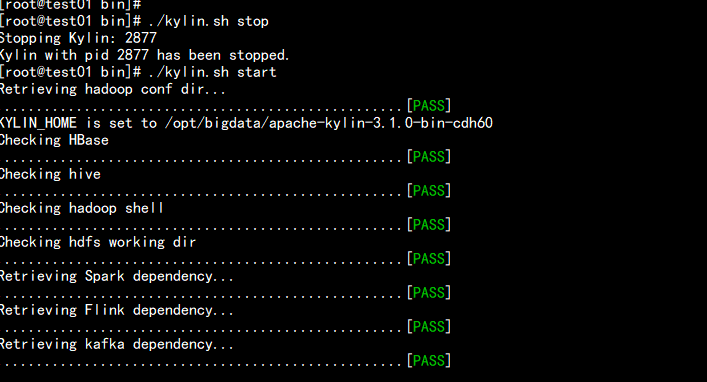
./kylin.sh stop
./kylin.sh start
从新刷新一下元数据(RELOAD METADATA)
点击:System ---> RELOAD METADATA
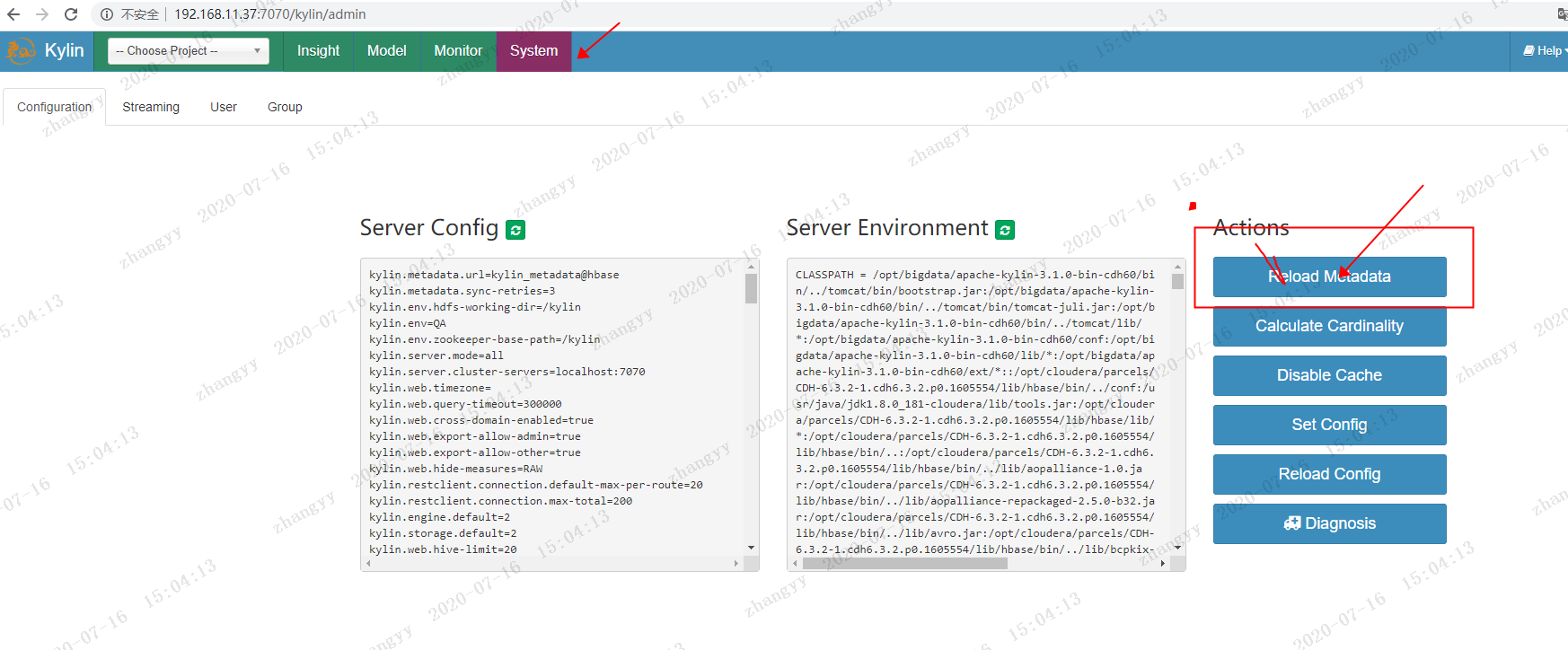
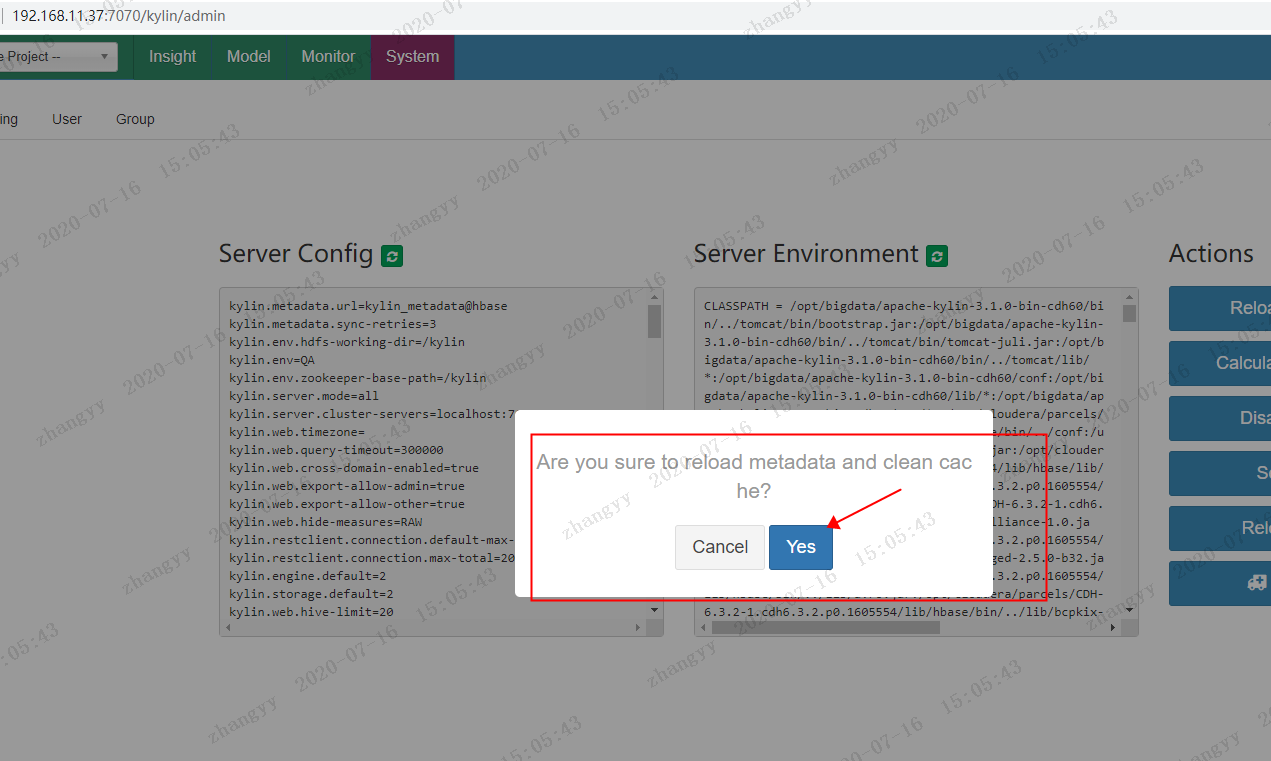
点击:YES
在右下角会有
Sucess cache reaload Sucessful
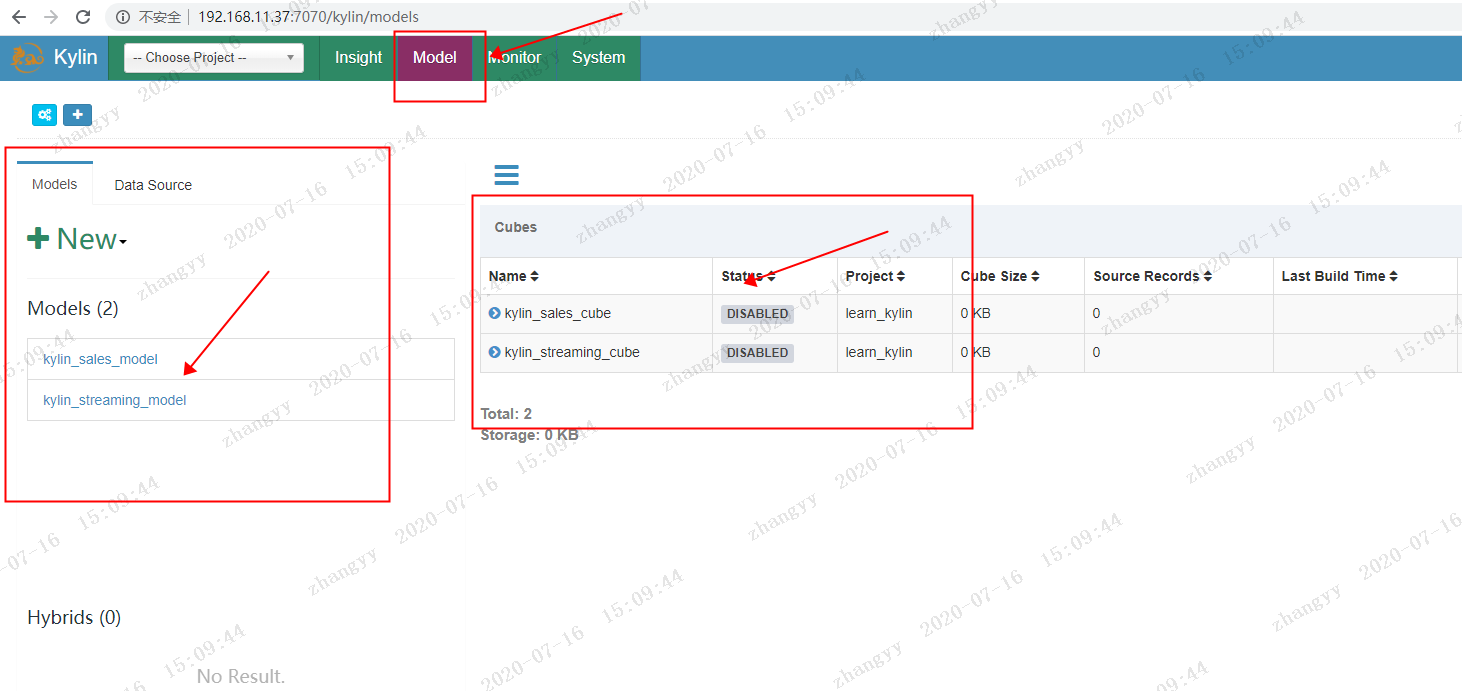
点击菜单栏上的 Model
会生成两个sample 表的模型
kylin_sales_model
kylin_streaming_model
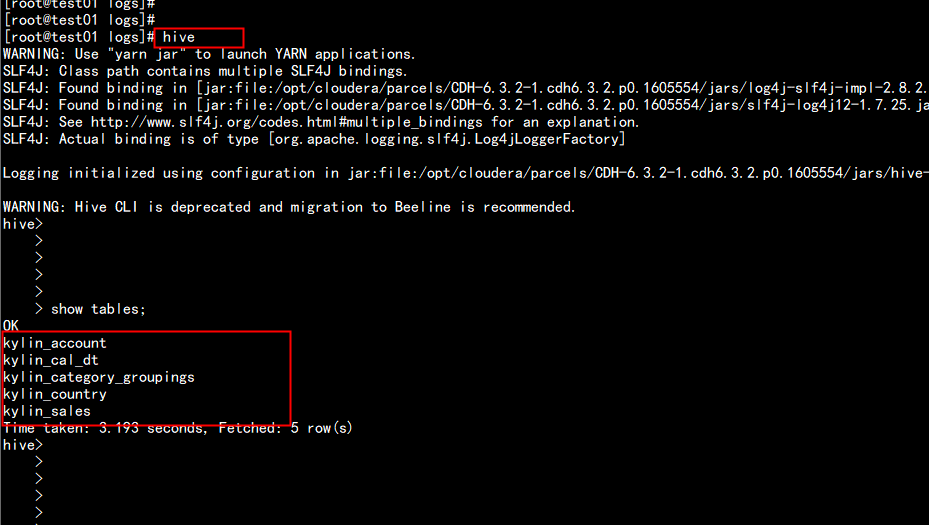
在hive中 查看表:
hive
hive > show tables;
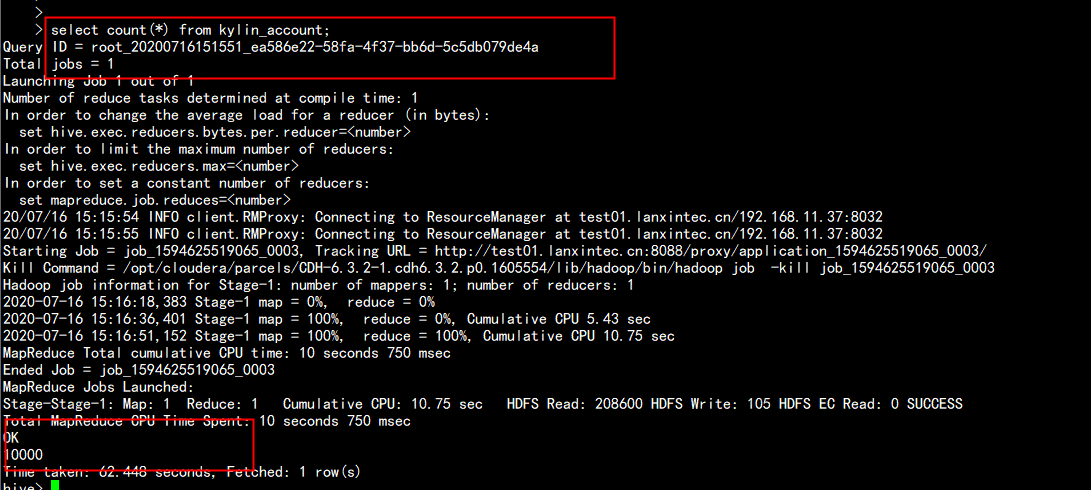
hive> select count(*) from kylin_account;
打开yarn的界面
http://192.168.11.37:8088

最后显示为10000 条 数据
将hive 中的表 刷新到 impala 当中
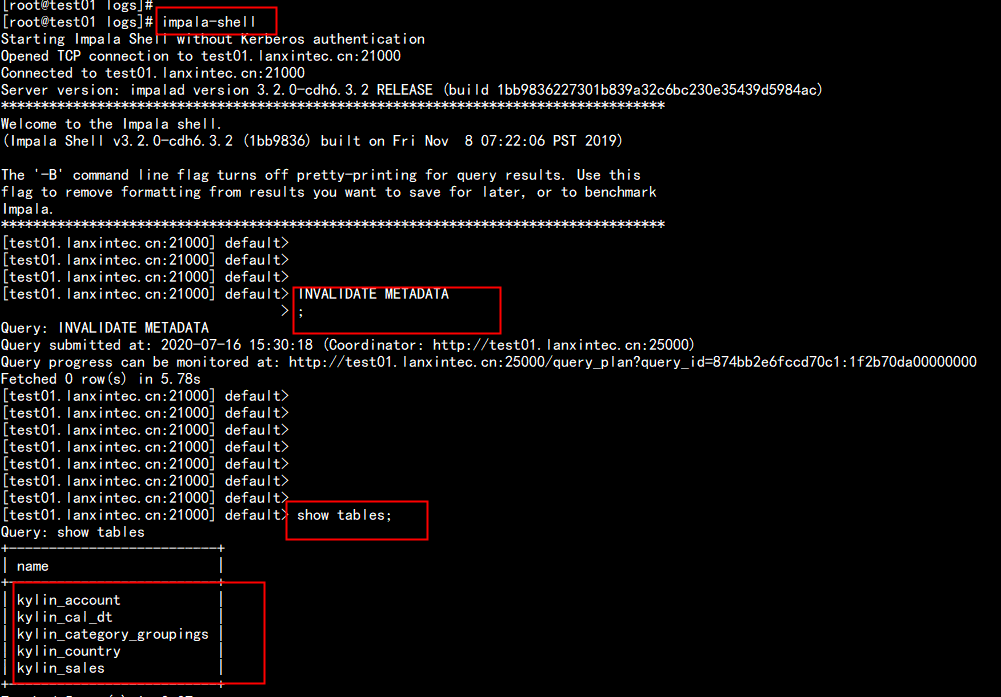
impala的加载表:
impala-shell -i "INVALIDATE METADATA"
单独刷新一张表:
refrash + 表名
hive 的default库 当中多了几张kylin的表
4.1.2 构建 表cube
以kylin 表 中 的 : kylin_sales_cube
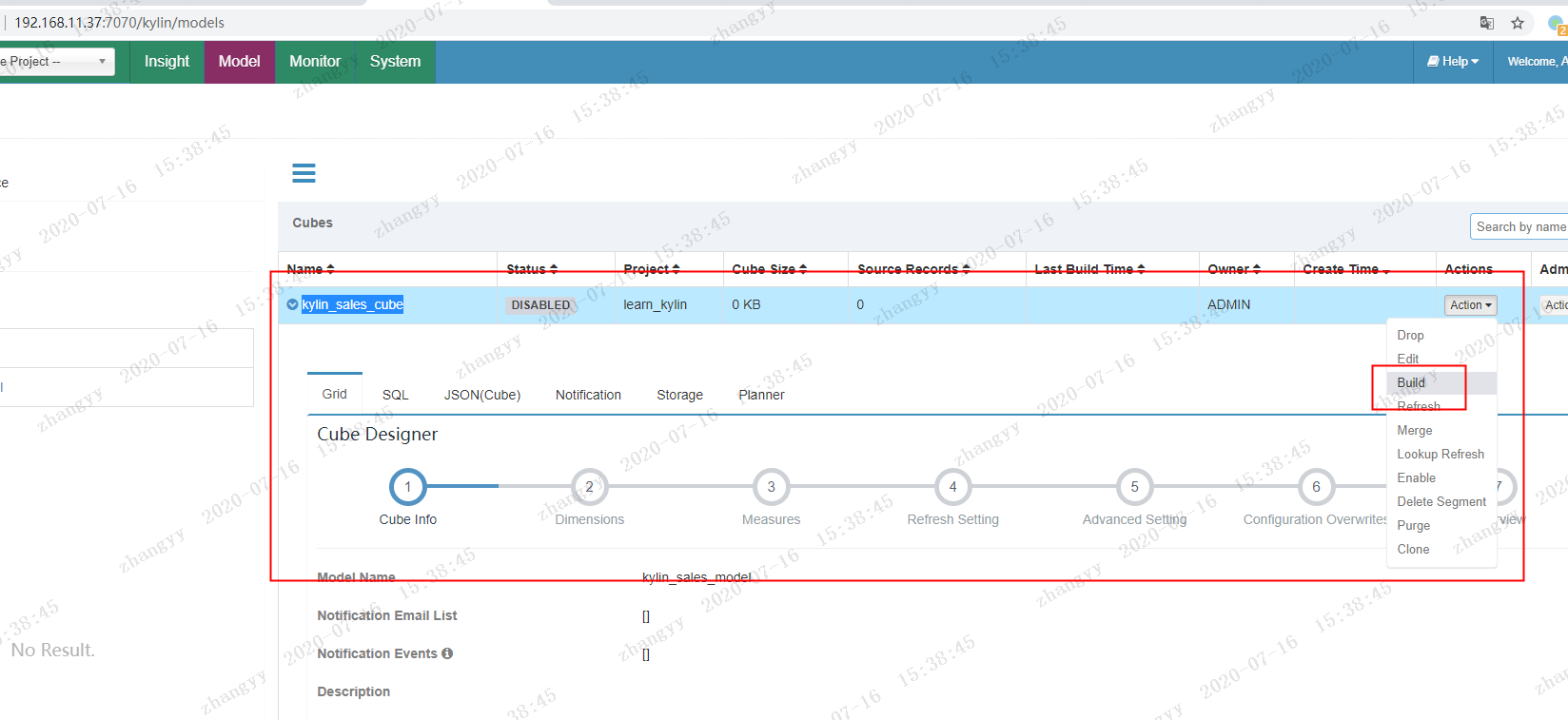
点击 YES
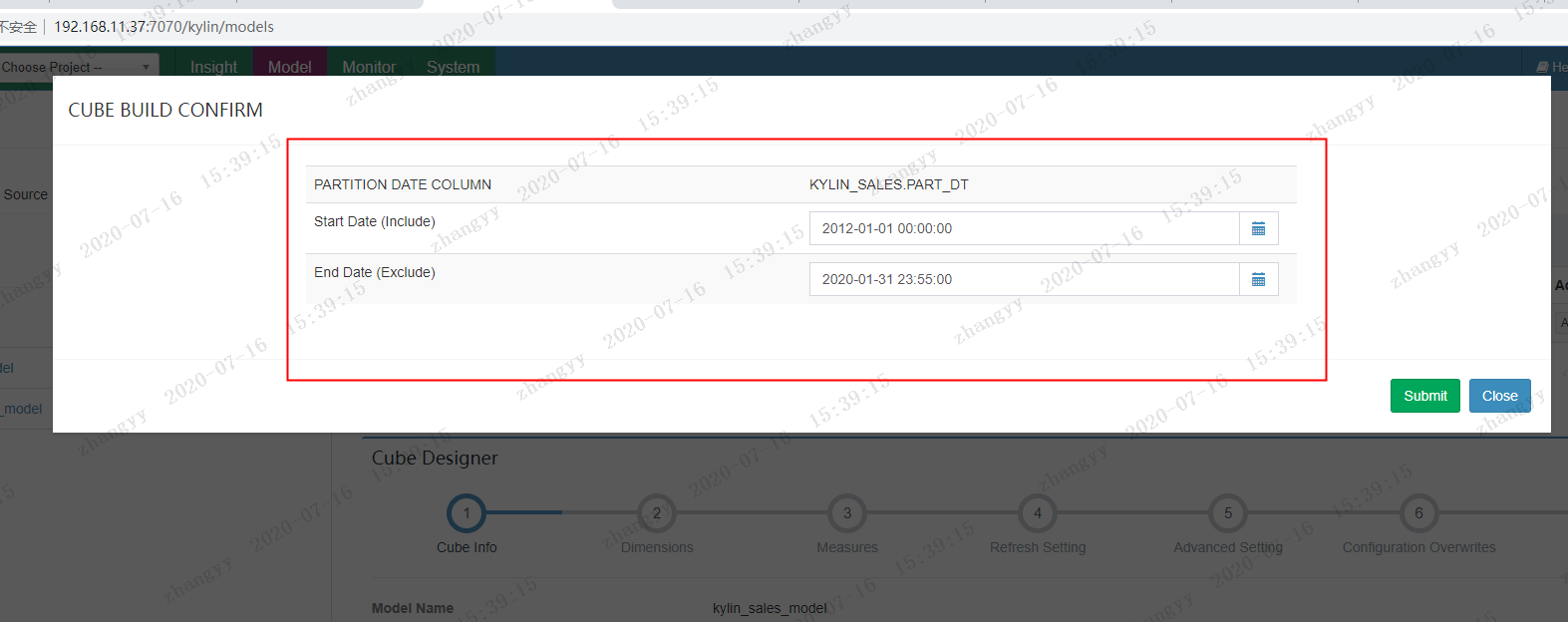
这边只构建 一个月维度的sales 不然硬件配置不够,此步会消耗巨大的硬件资源
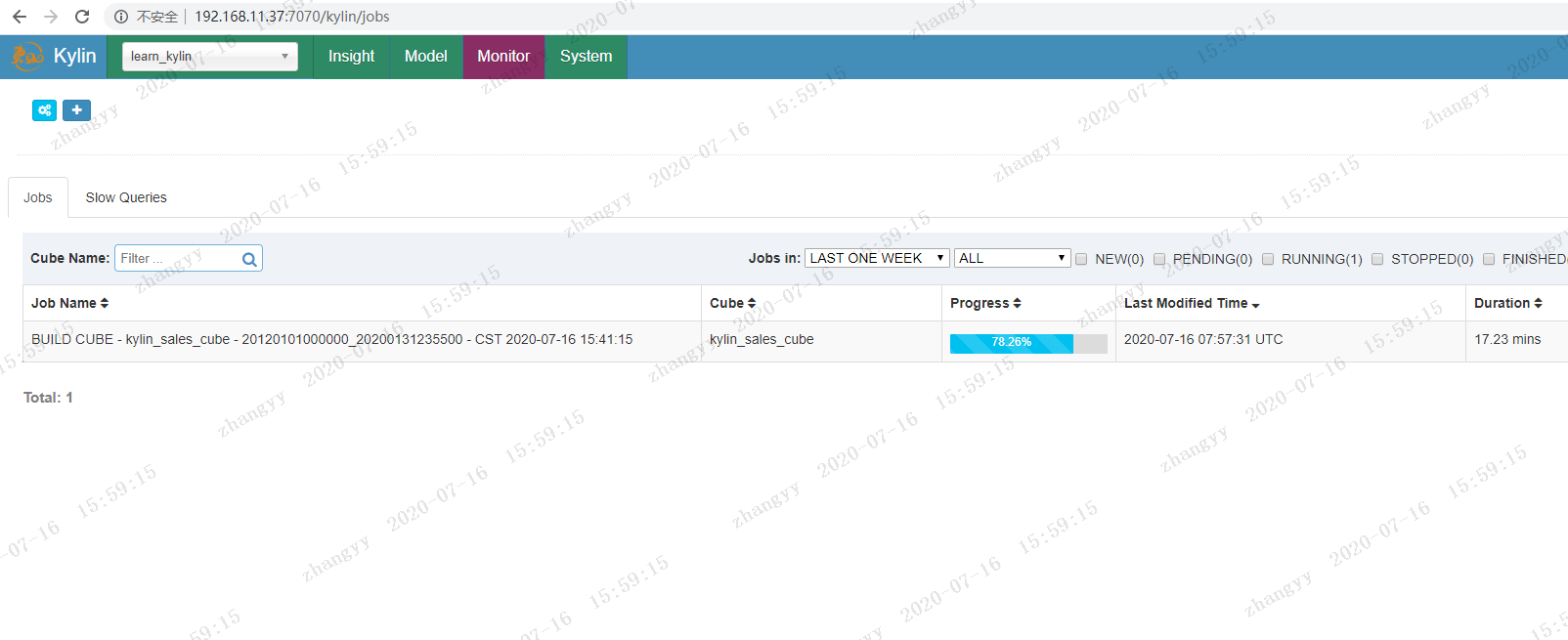
构建 点击monitor 查看build
可以不断的刷新网页 查看 job 的 构建 进度
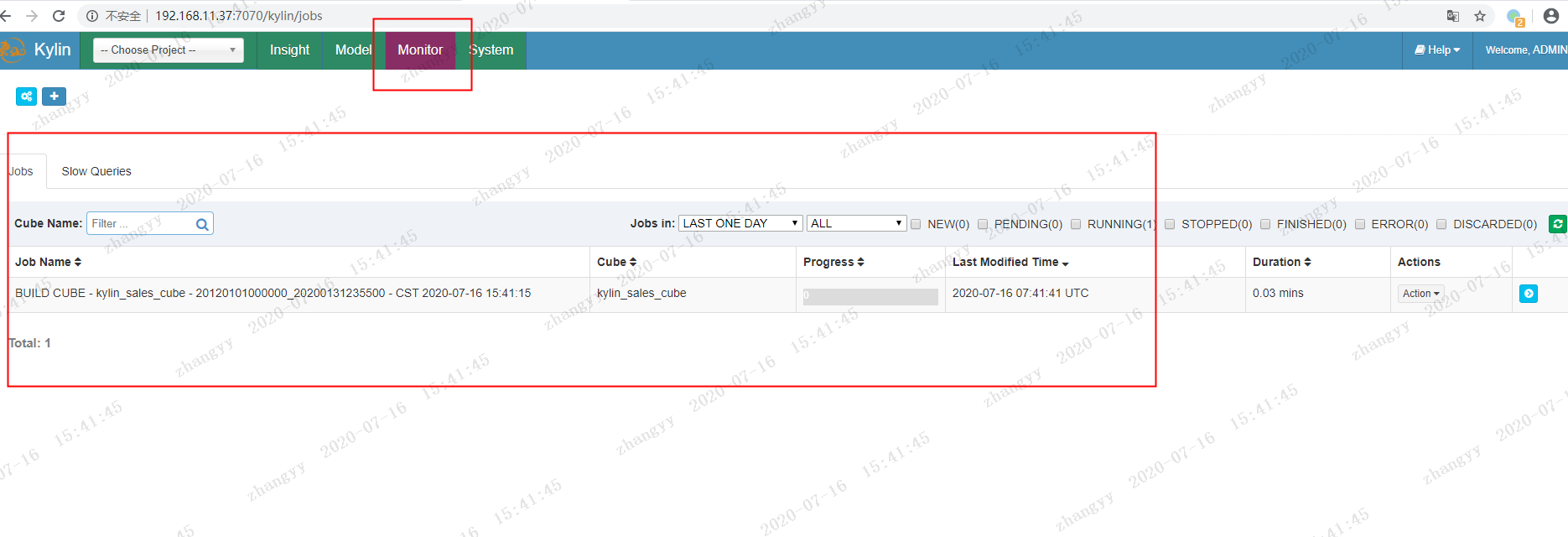

这边默认 走的是Hadoop 的mapreduce 所以比较慢

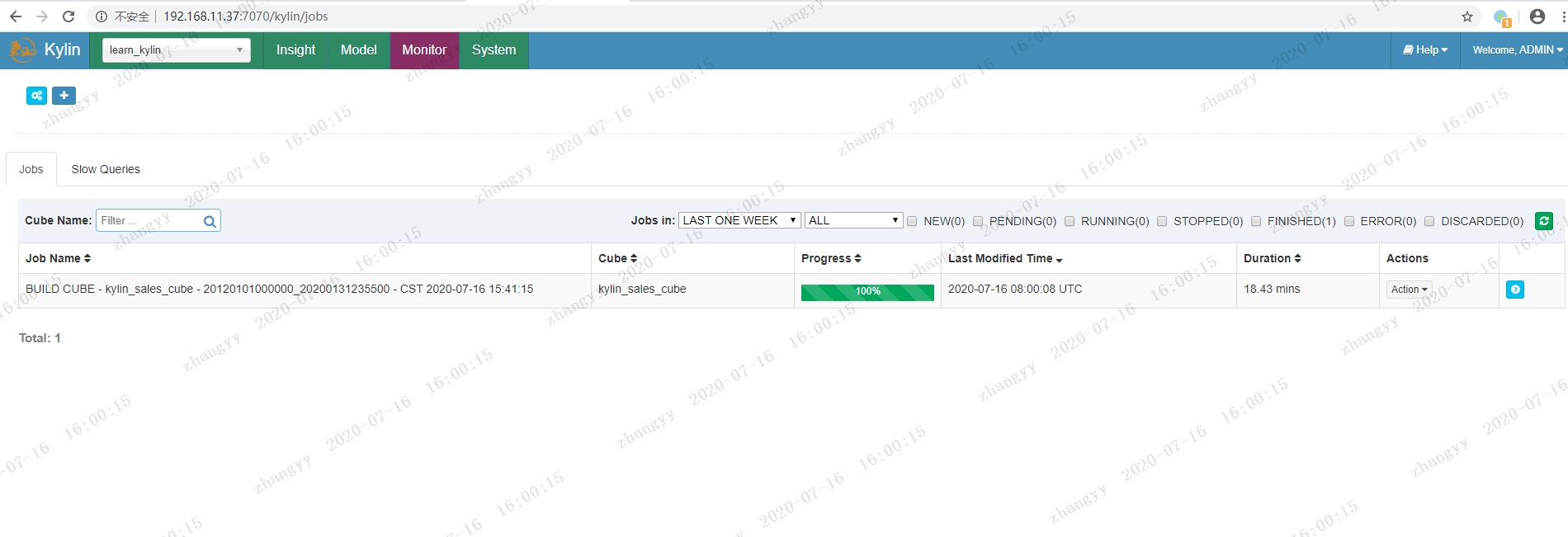
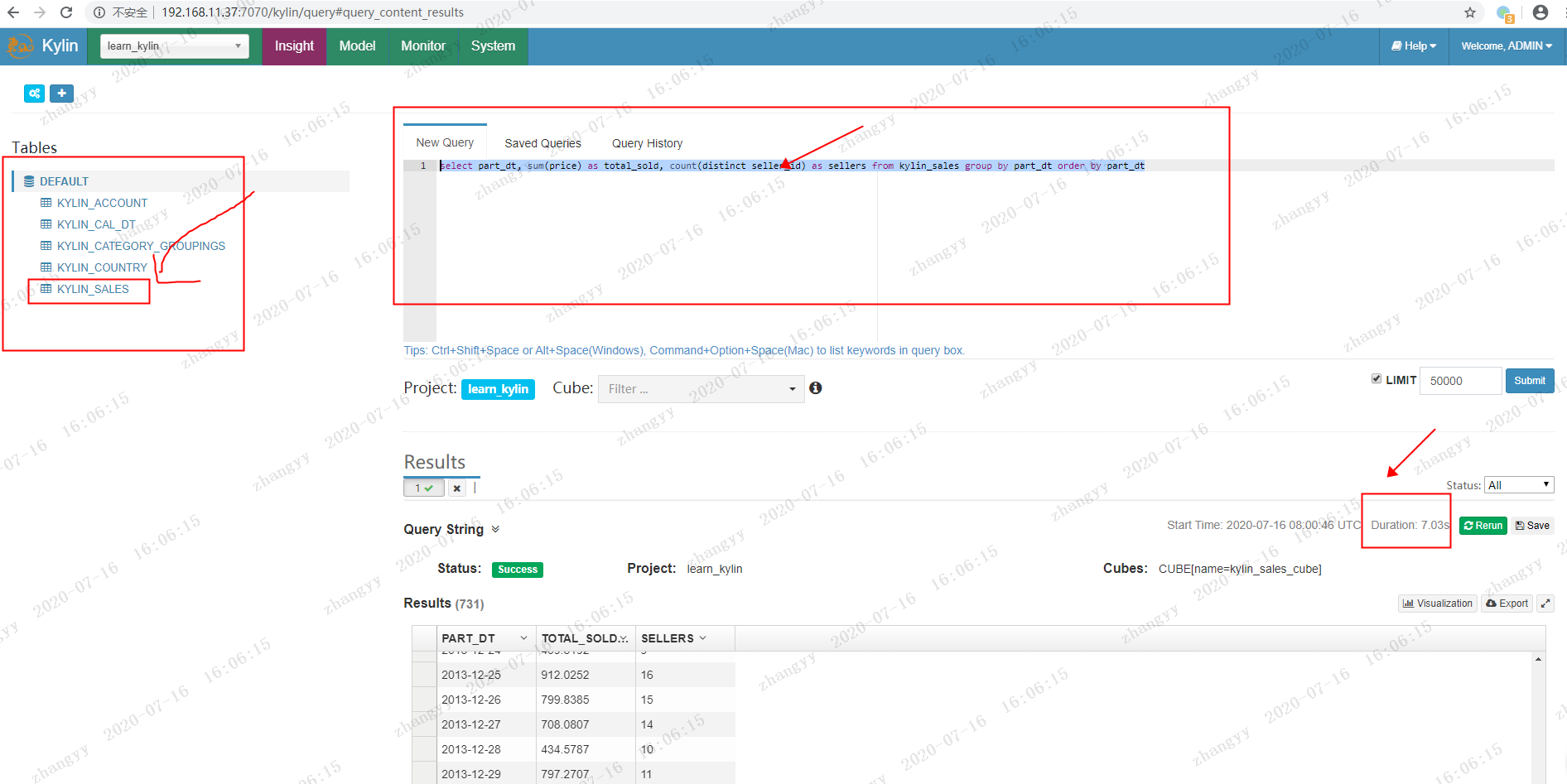
构建查询:
点击:insight
New Query:
select part_dt, sum(price) as total_sold, count(distinct seller_id) as sellers from kylin_sales group by part_dt order by part_dt
在hive 中查询
select part_dt, sum(price) as total_sold, count(distinct seller_id) as sellers from kylin_sales group by part_dt order by part_dt
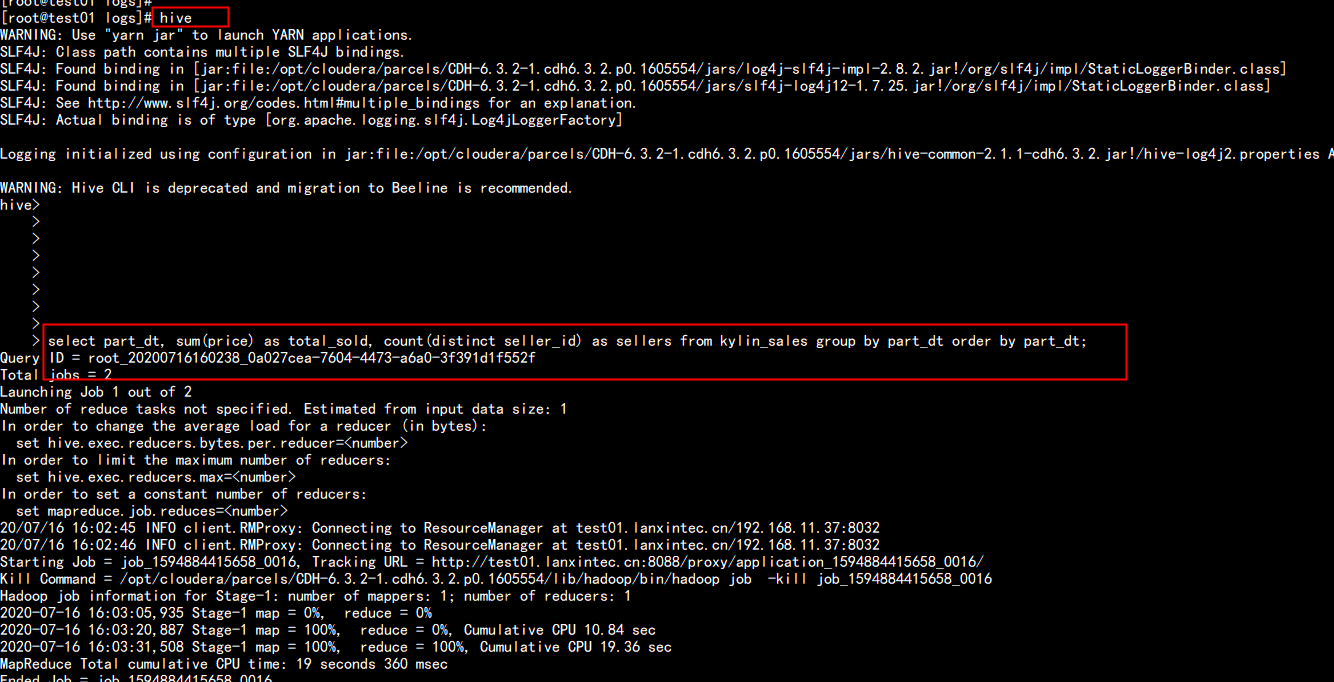
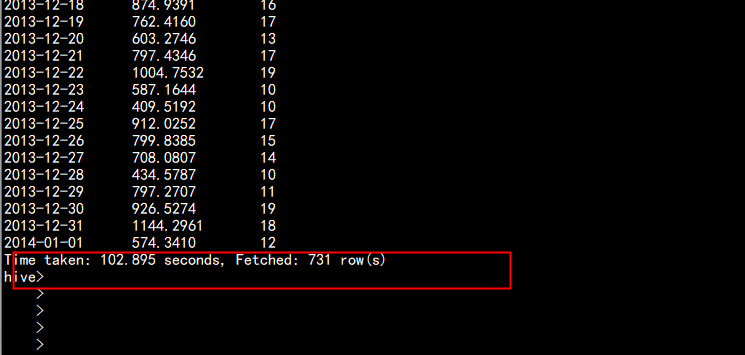
在kylin 中查询只要 7.09s 而在hive 中查询 要 102.895s
执行一个复杂的查询:
select sum(KYLIN_SALES.PRICE)
as price_sum,KYLIN_CATEGORY_GROUPINGS.META_CATEG_NAME,KYLIN_CATEGORY_GROUPINGS.CATEG_LVL2_NAME
from KYLIN_SALES inner join KYLIN_CATEGORY_GROUPINGS
on KYLIN_SALES.LEAF_CATEG_ID = KYLIN_CATEGORY_GROUPINGS.LEAF_CATEG_ID and
KYLIN_SALES.LSTG_SITE_ID = KYLIN_CATEGORY_GROUPINGS.SITE_ID
group by KYLIN_CATEGORY_GROUPINGS.META_CATEG_NAME,KYLIN_CATEGORY_GROUPINGS.CATEG_LVL2_NAME
order by KYLIN_CATEGORY_GROUPINGS.META_CATEG_NAME asc,KYLIN_CATEGORY_GROUPINGS.CATEG_LVL2_NAME desc
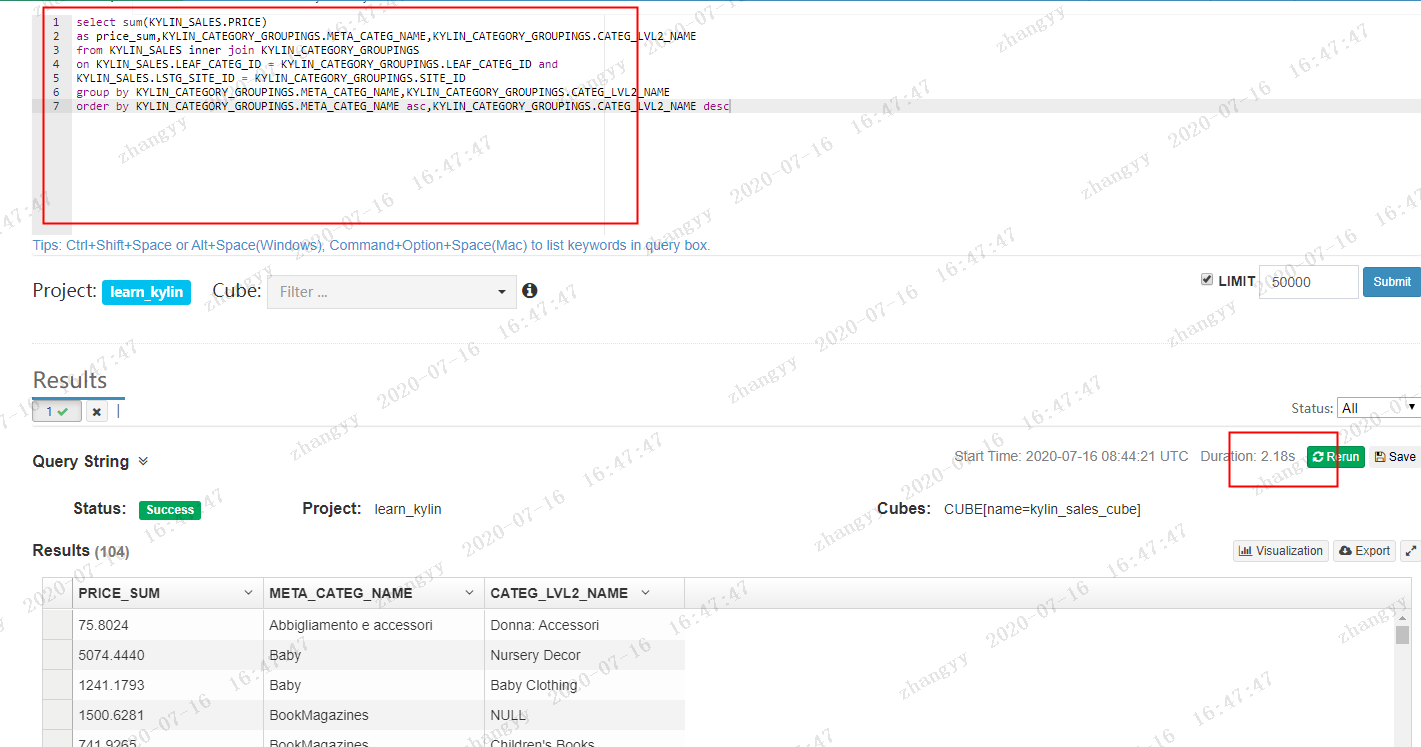
在hive 中查询:
select sum(KYLIN_SALES.PRICE)
as price_sum,KYLIN_CATEGORY_GROUPINGS.META_CATEG_NAME,KYLIN_CATEGORY_GROUPINGS.CATEG_LVL2_NAME
from KYLIN_SALES inner join KYLIN_CATEGORY_GROUPINGS
on KYLIN_SALES.LEAF_CATEG_ID = KYLIN_CATEGORY_GROUPINGS.LEAF_CATEG_ID and
KYLIN_SALES.LSTG_SITE_ID = KYLIN_CATEGORY_GROUPINGS.SITE_ID
group by KYLIN_CATEGORY_GROUPINGS.META_CATEG_NAME,KYLIN_CATEGORY_GROUPINGS.CATEG_LVL2_NAME
order by KYLIN_CATEGORY_GROUPINGS.META_CATEG_NAME asc,KYLIN_CATEGORY_GROUPINGS.CATEG_LVL2_NAME desc
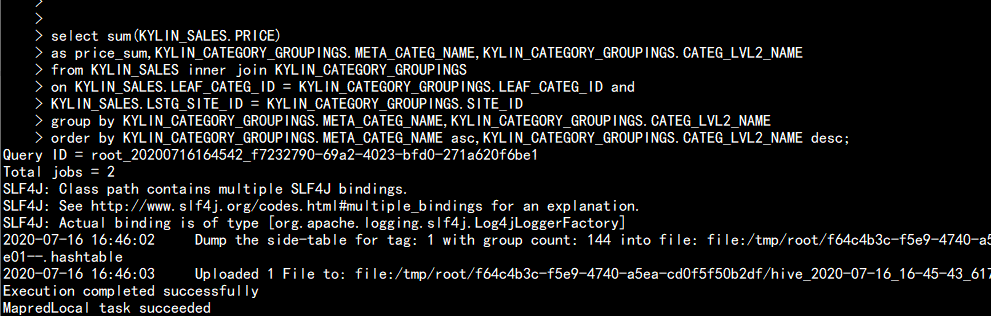
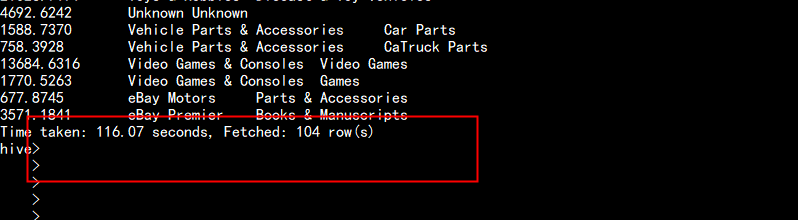
在kylin 中查询 只要 2.18s hive 中查询 要 116.07s
五: kylin 自建表导入数据测试
5.1 自建数据准备文件
create_table.sql department.csv employee.csv
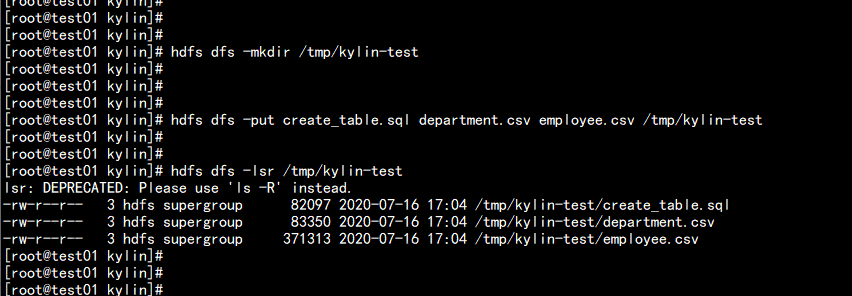
将这三个文件传到 hdfs 上面
hdfs dfs -mkdir /tmp/kylin-test
hdfs dfs -put create_table.sql department.csv employee.csv /tmp/kylin-test
vim create-table.sql
---
DROP TABLE IF EXISTS employee;
CREATE TABLE employee(
id int,
name string,
deptId int,
age int,
salary float
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
DROP TABLE IF EXISTS department;
CREATE TABLE department(
id int,
name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
LOAD DATA INPATH '/tmp/kylin-test/employee.csv' OVERWRITE INTO TABLE employee;
LOAD DATA INPATH '/tmp/kylin-test/department.csv' OVERWRITE INTO TABLE department;
---
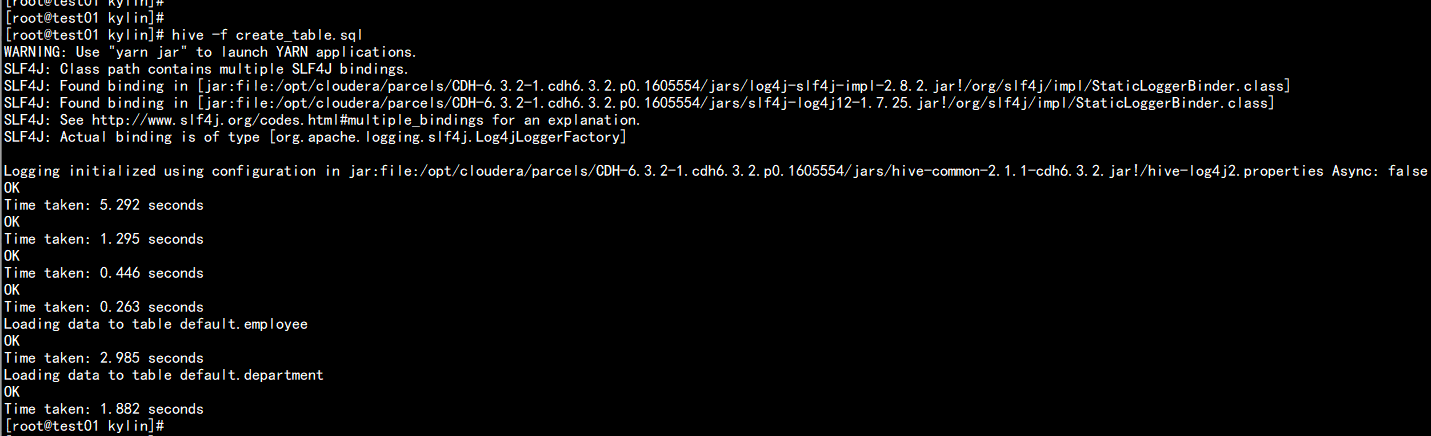
向hive 中 到如数据
hive -f create_table.sql
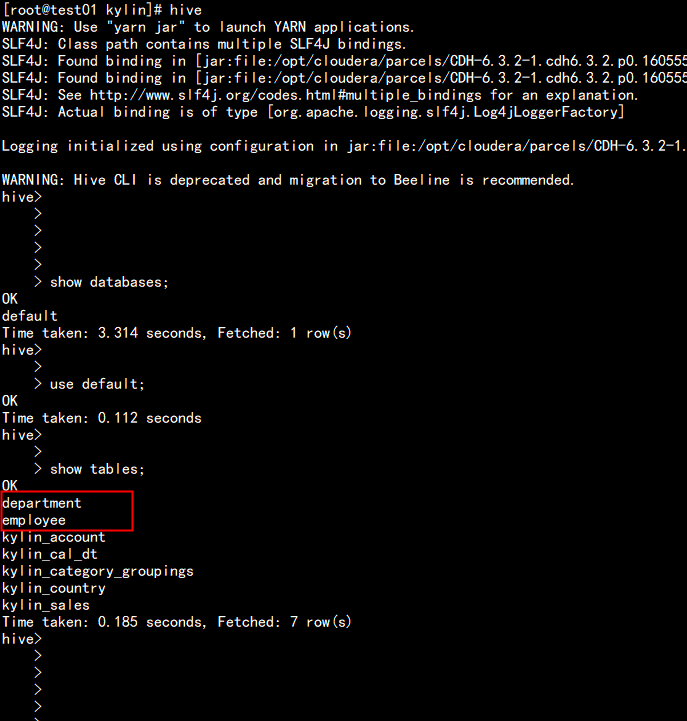
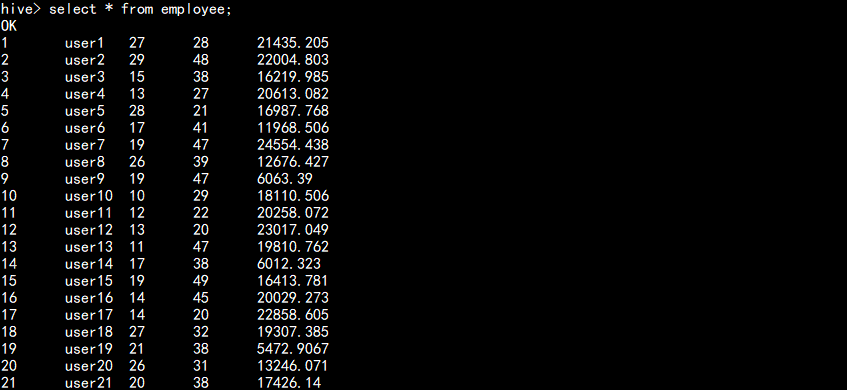
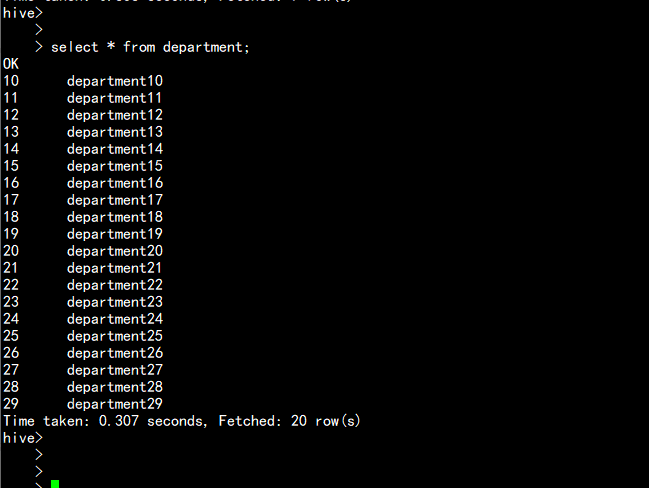
5.2 在kylin 中创建demo
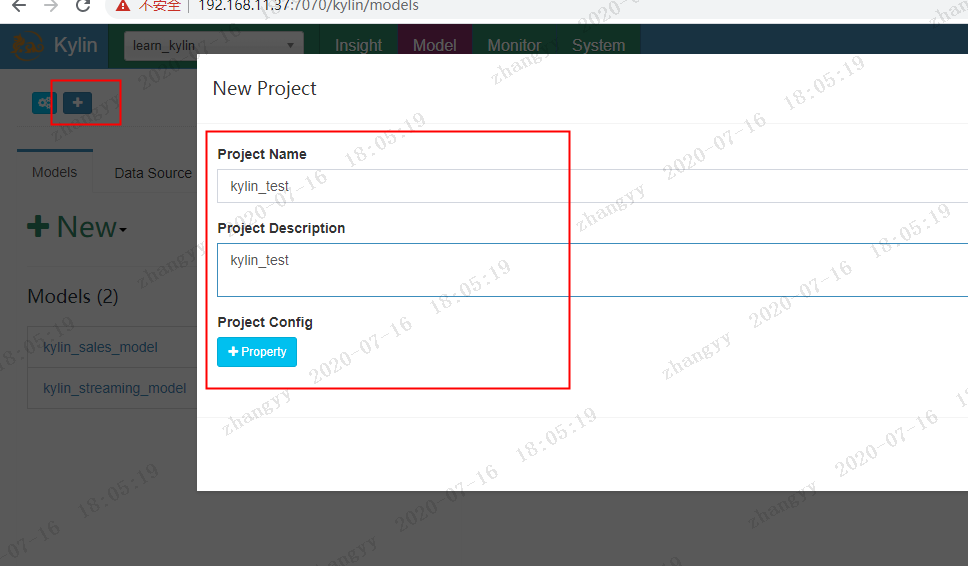
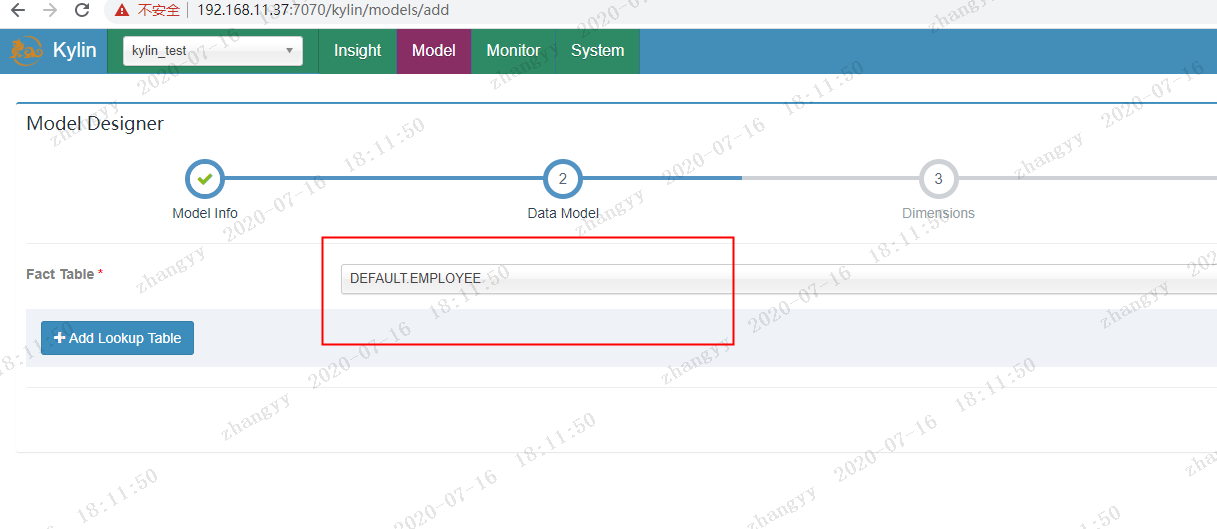
点击 Data_Source 加载 hive 中的 表
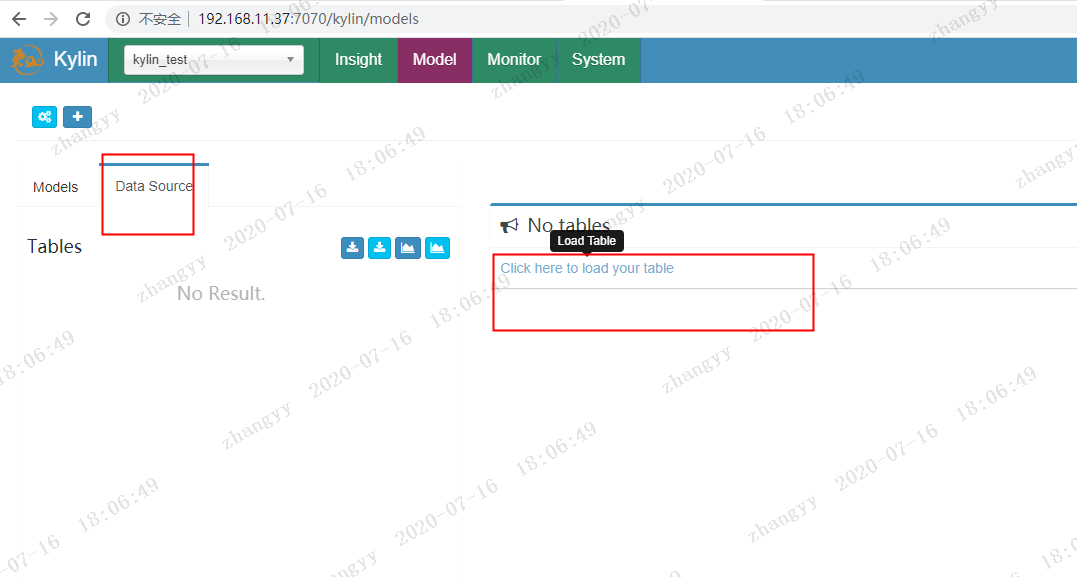
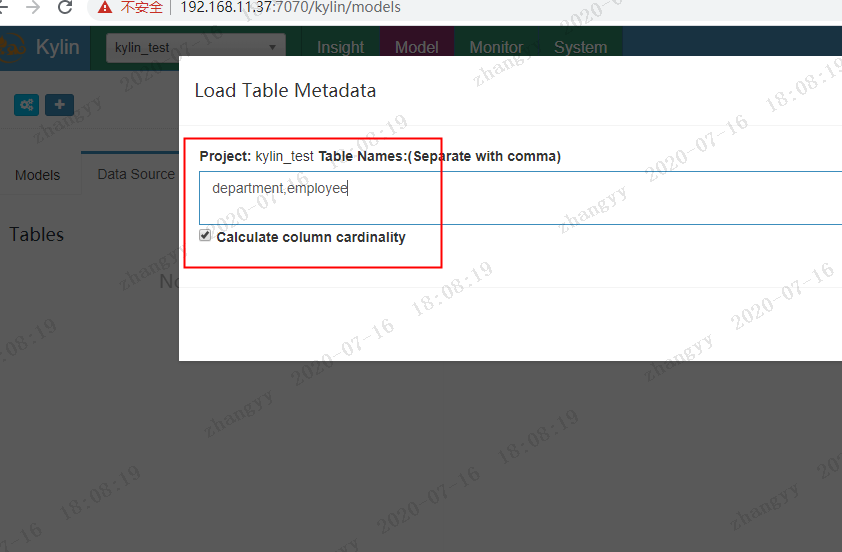
加载 department,employee 表
点击:sync 同步表
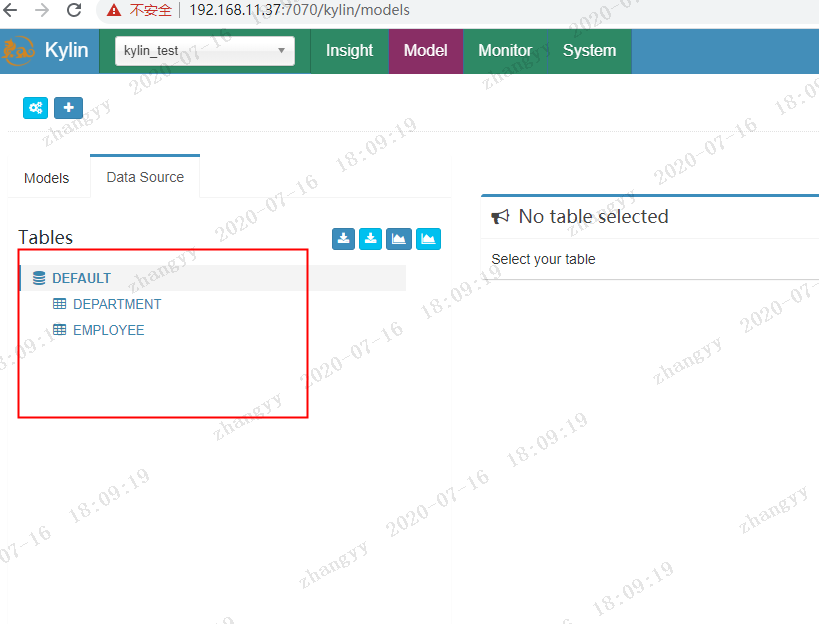
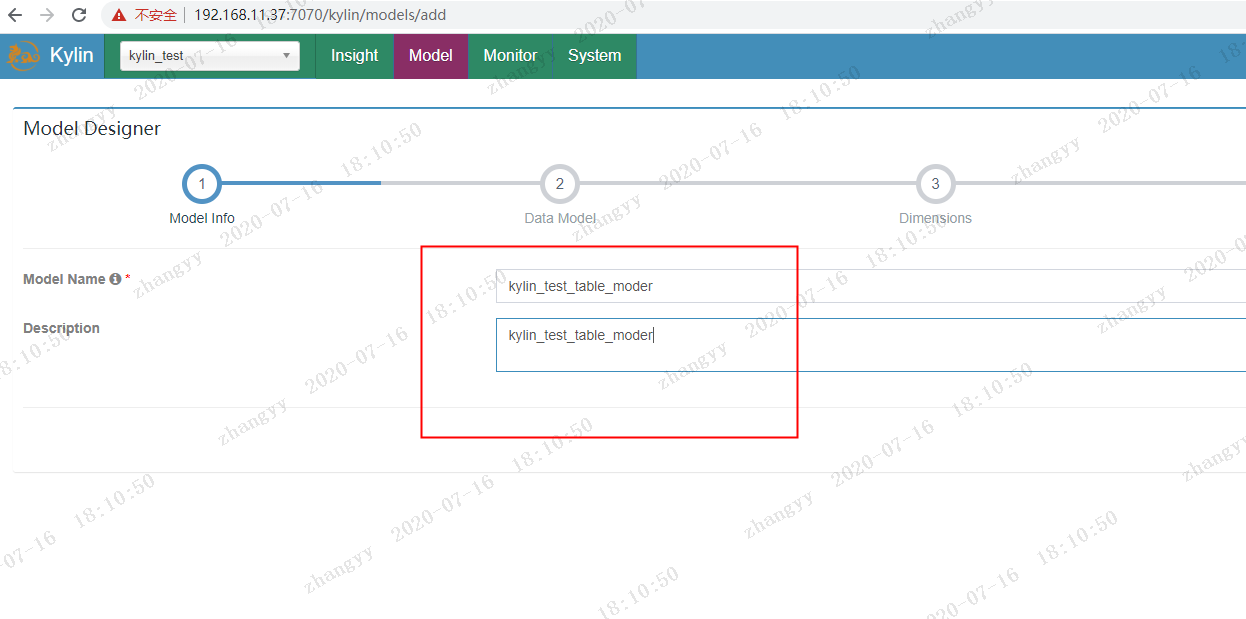
创建model,入project的名称和描述:
kylin_test_table_moder
选择创建moder 的表
与lookup table
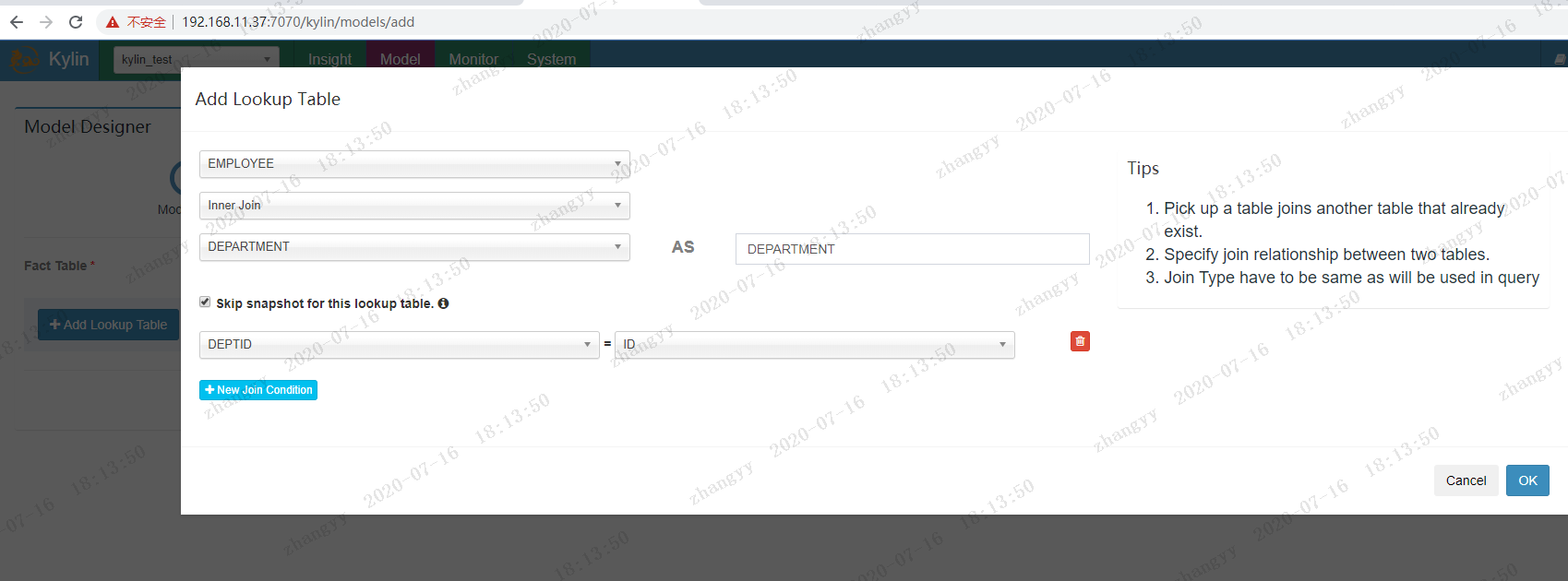
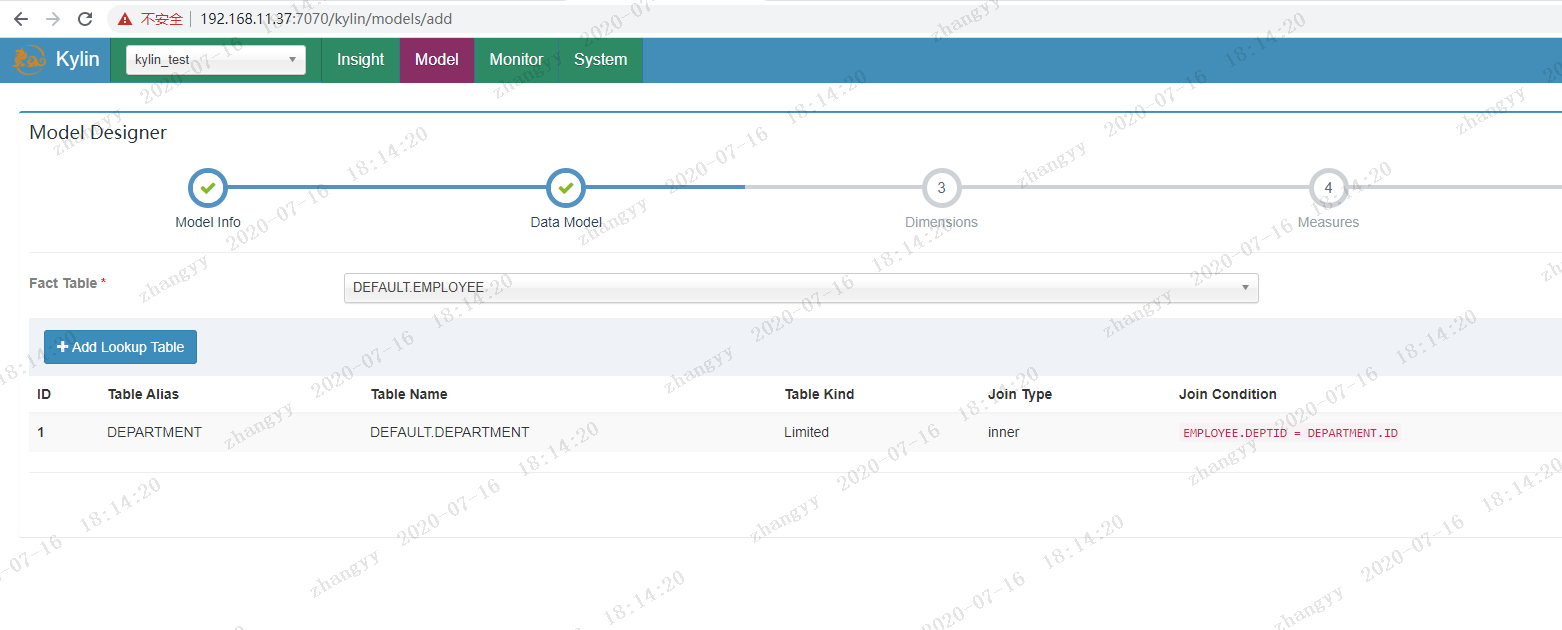
选择维度字段
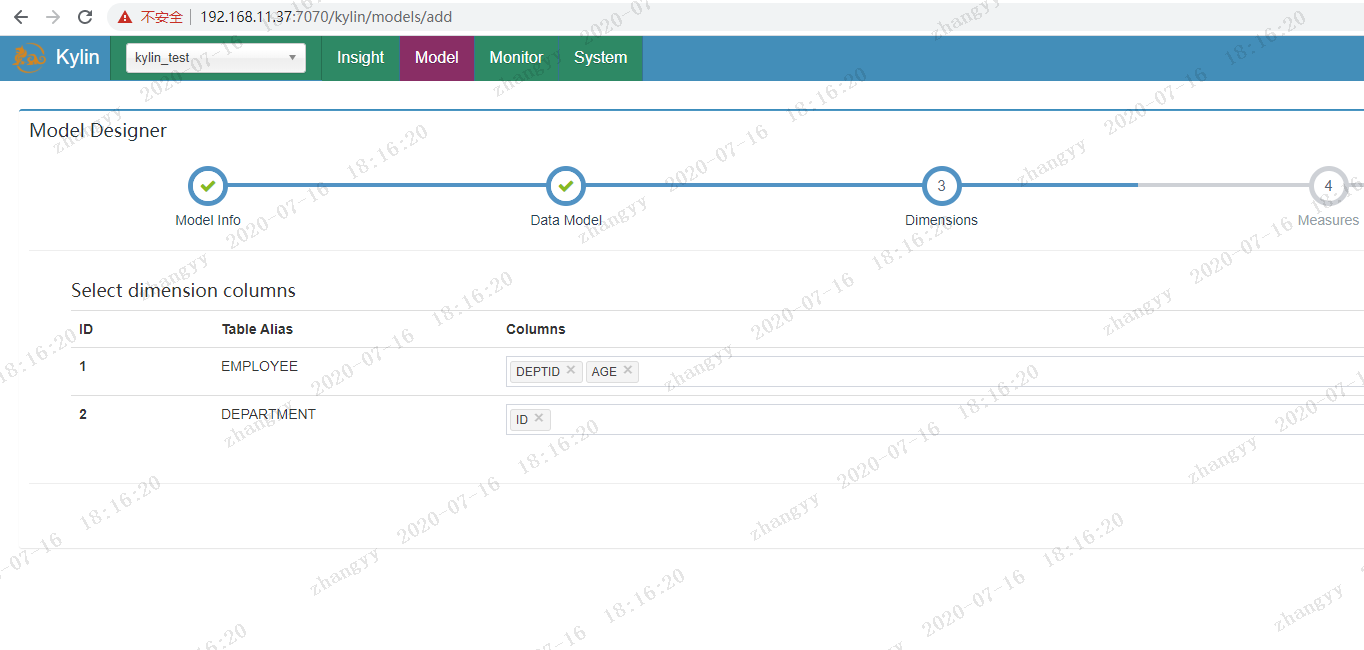
保存模型moder
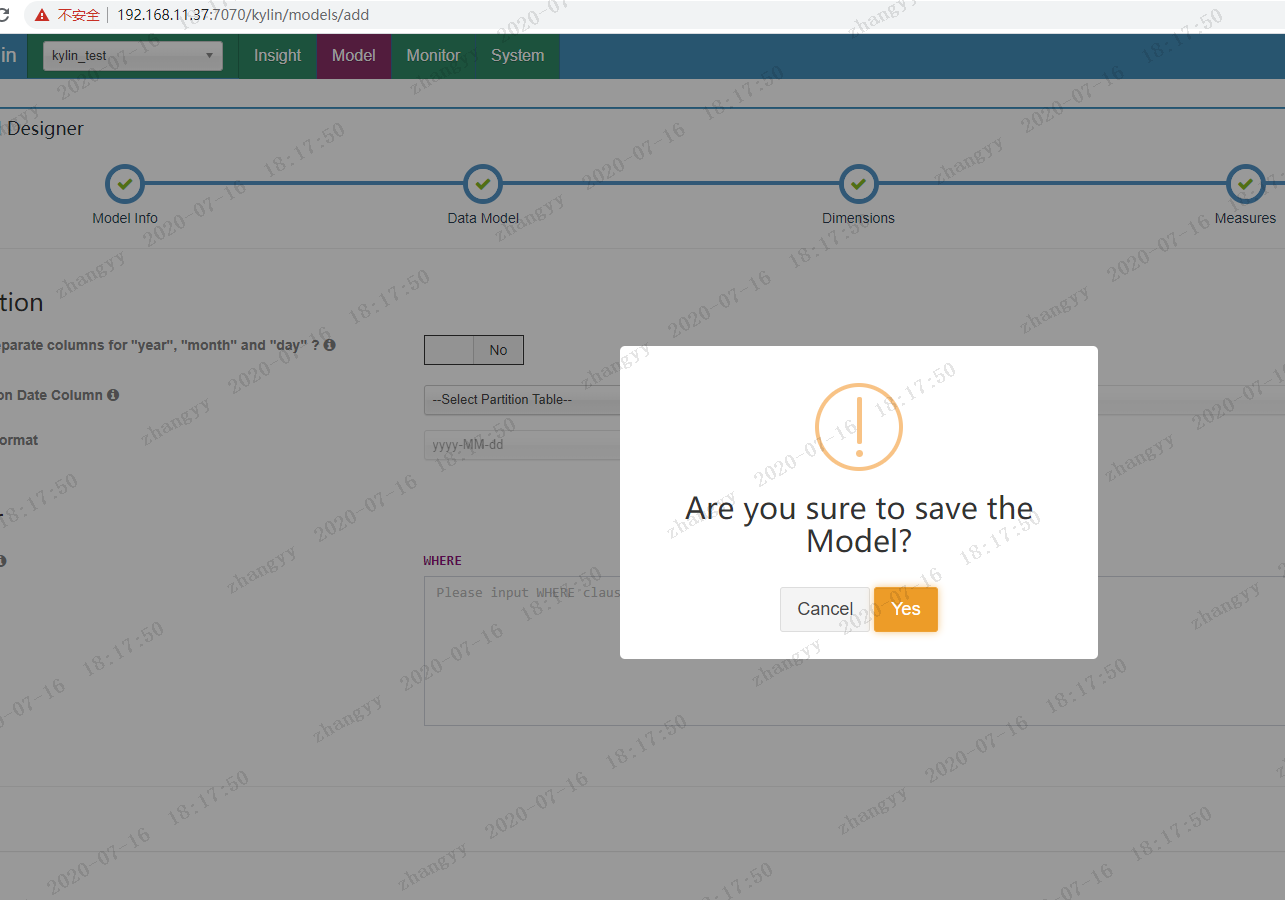
创建cube
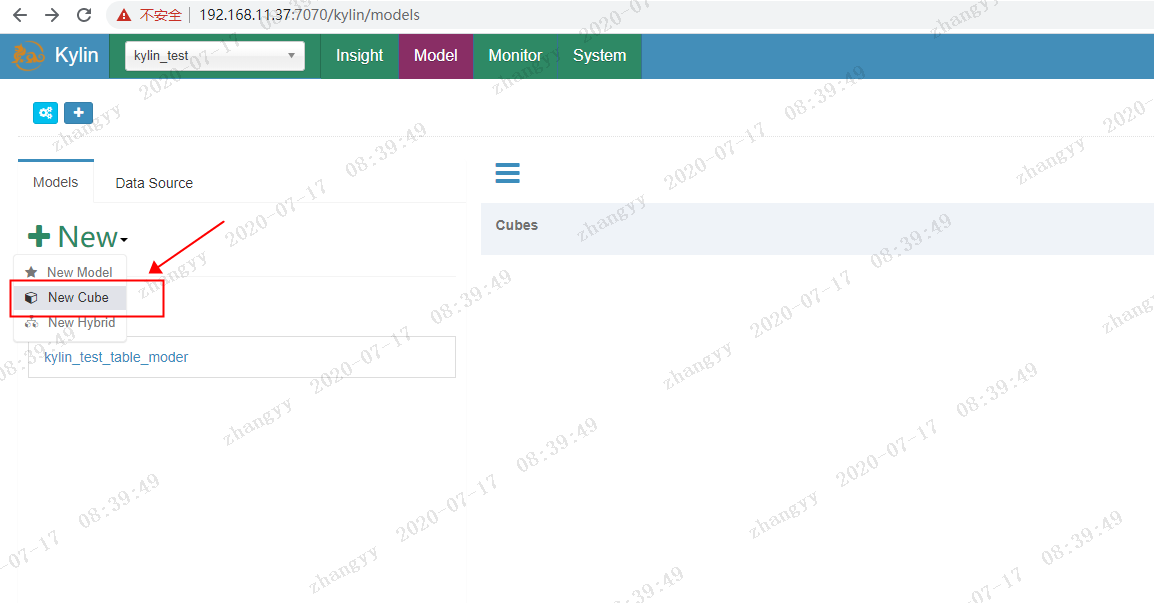
选择保存好moder
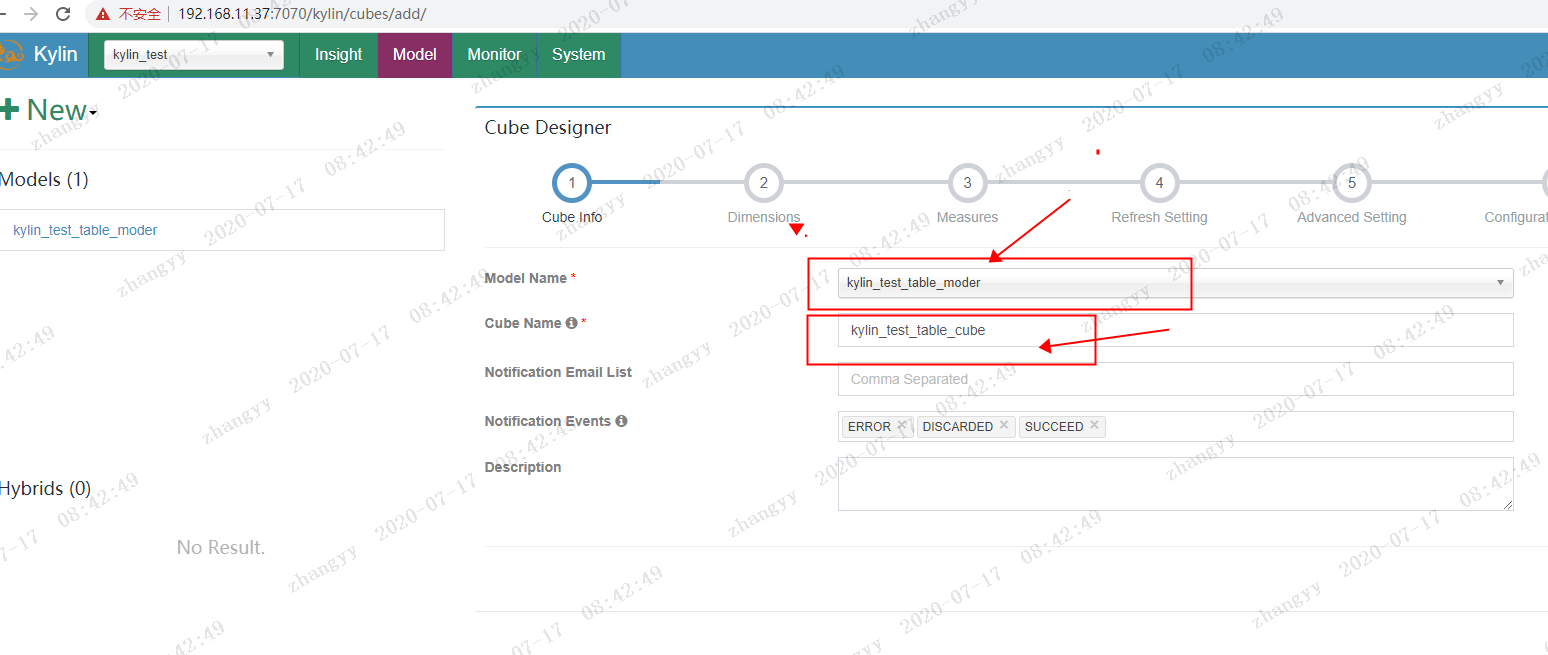
next -> add Dimensions
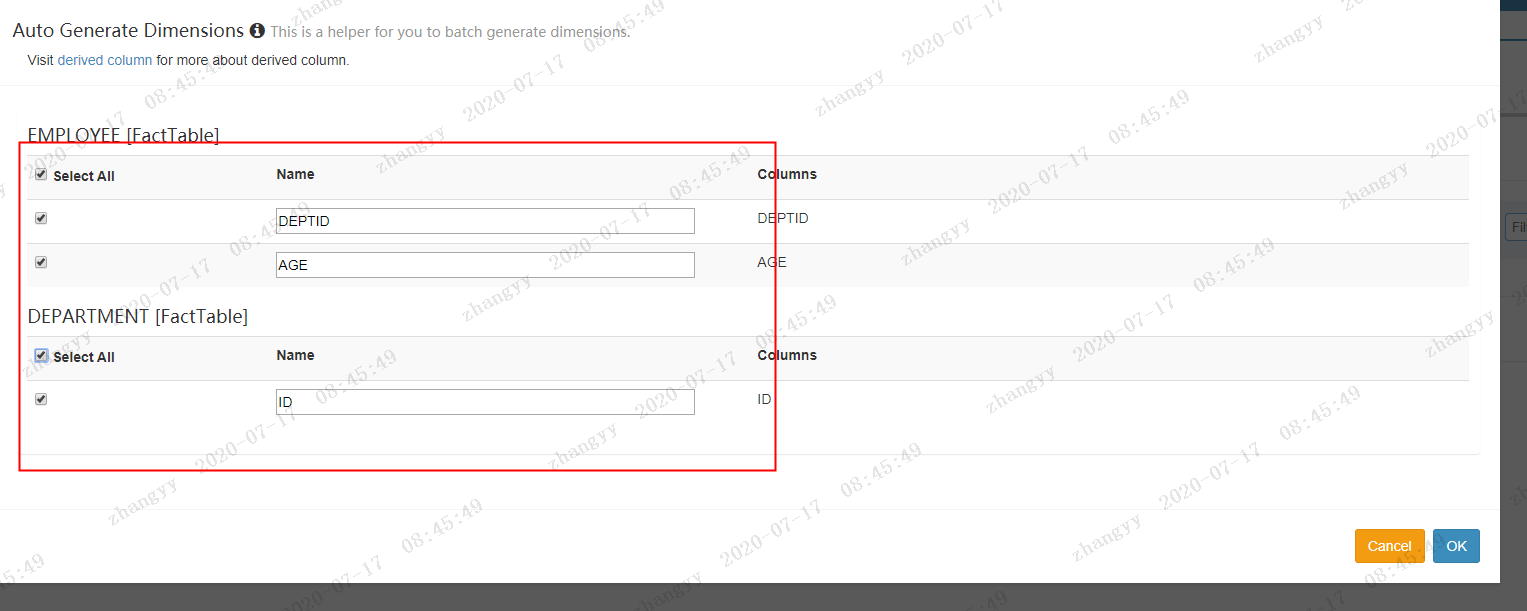
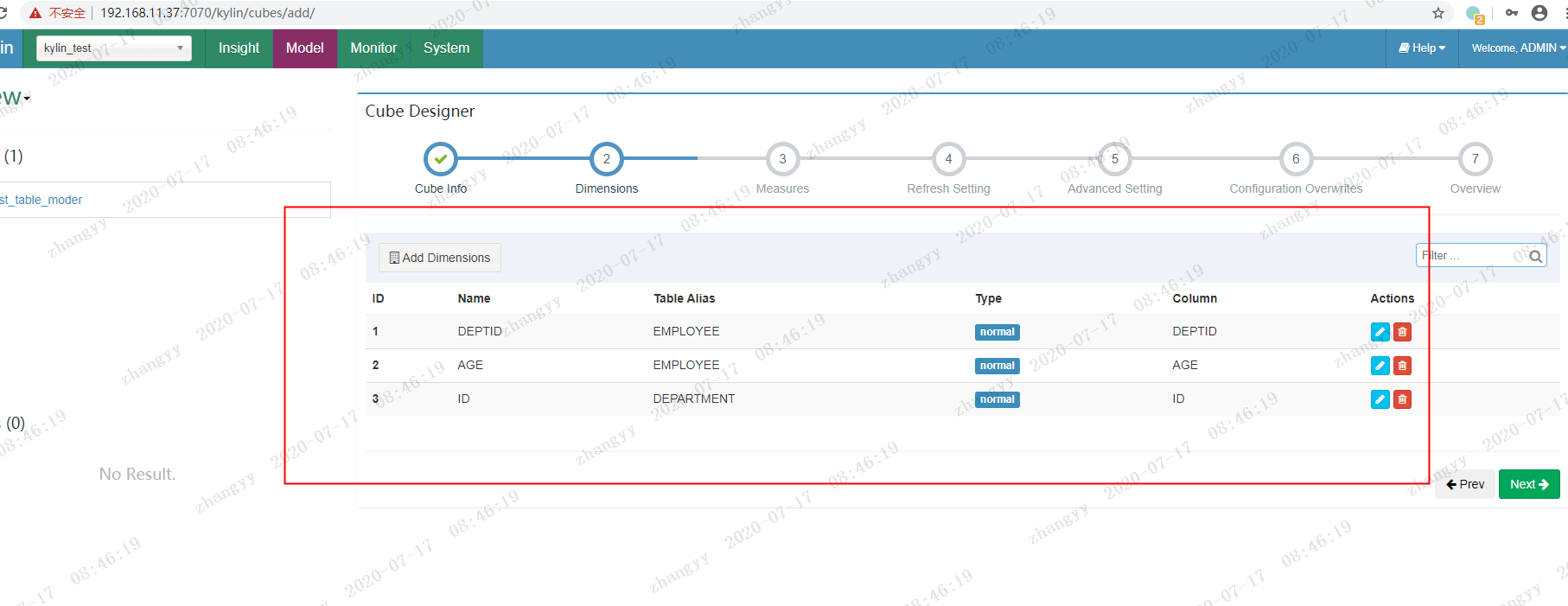
next--> 添加 bluk add Measure
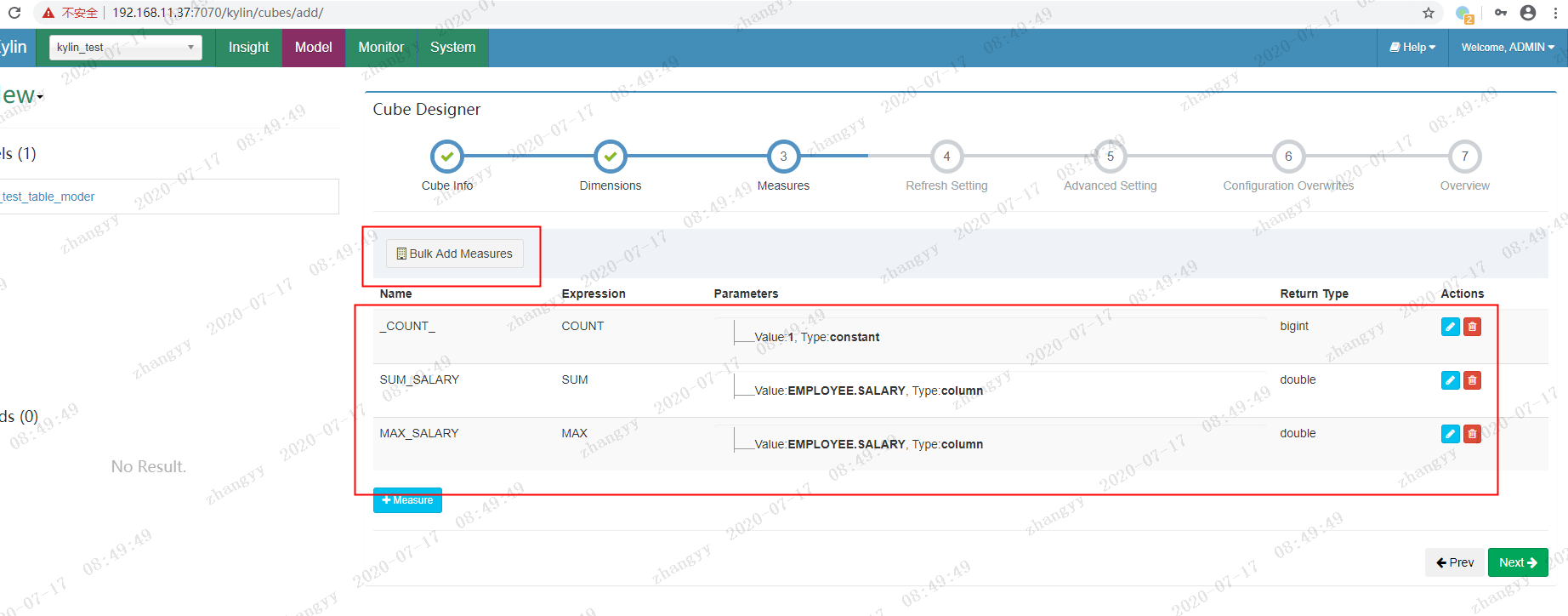
next
next
next
save ---> yes

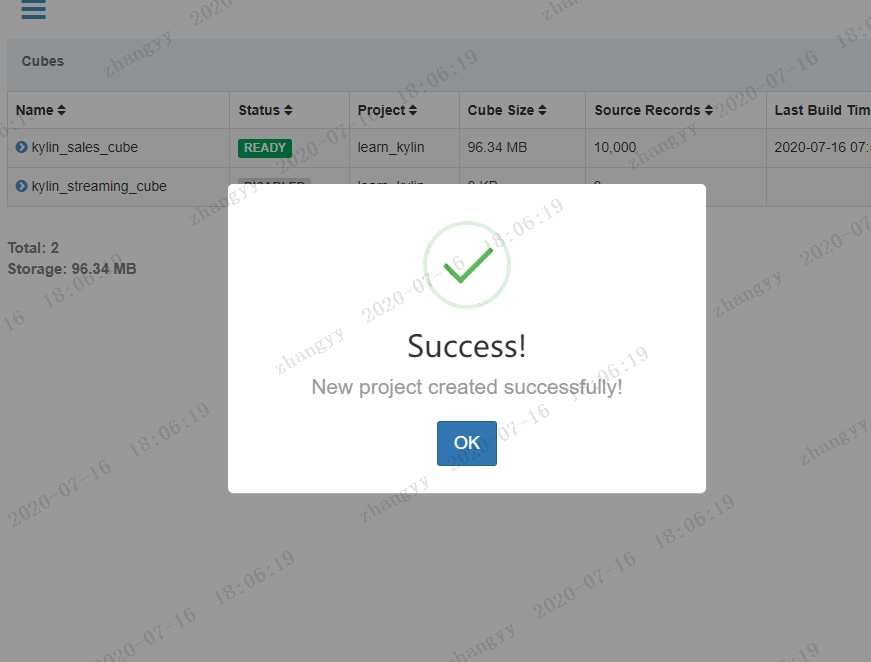
build --->构建cube
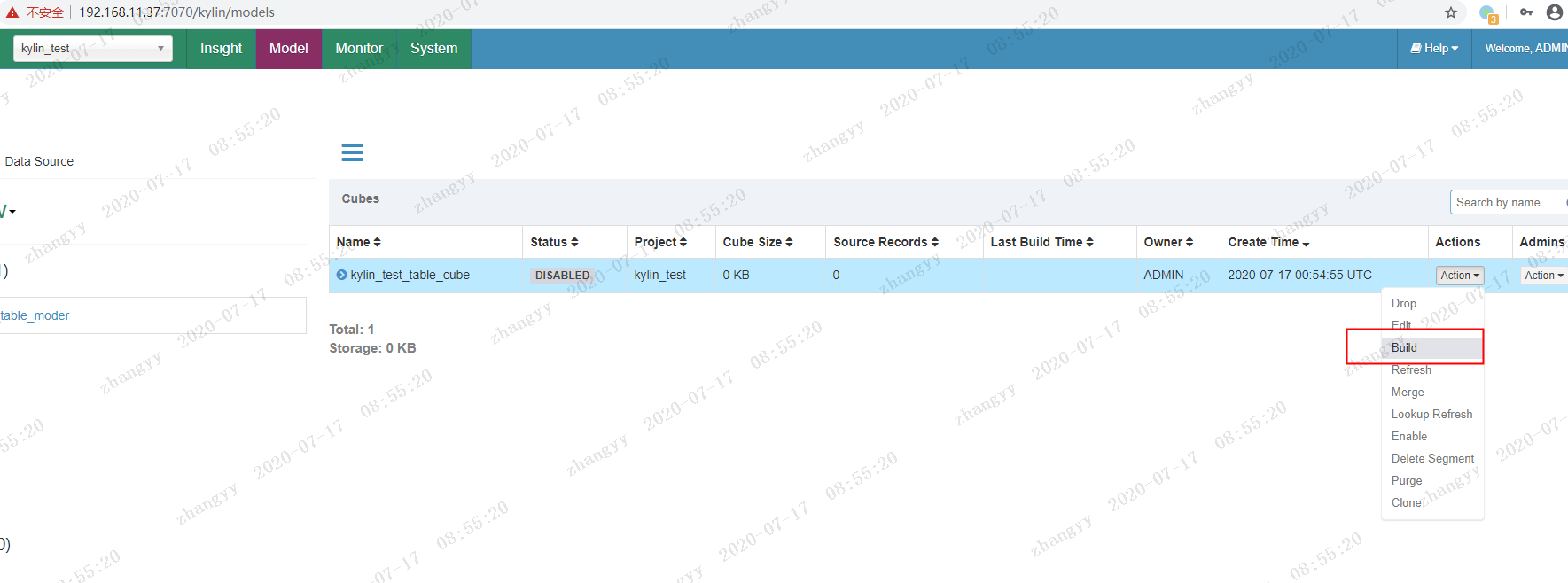
yes
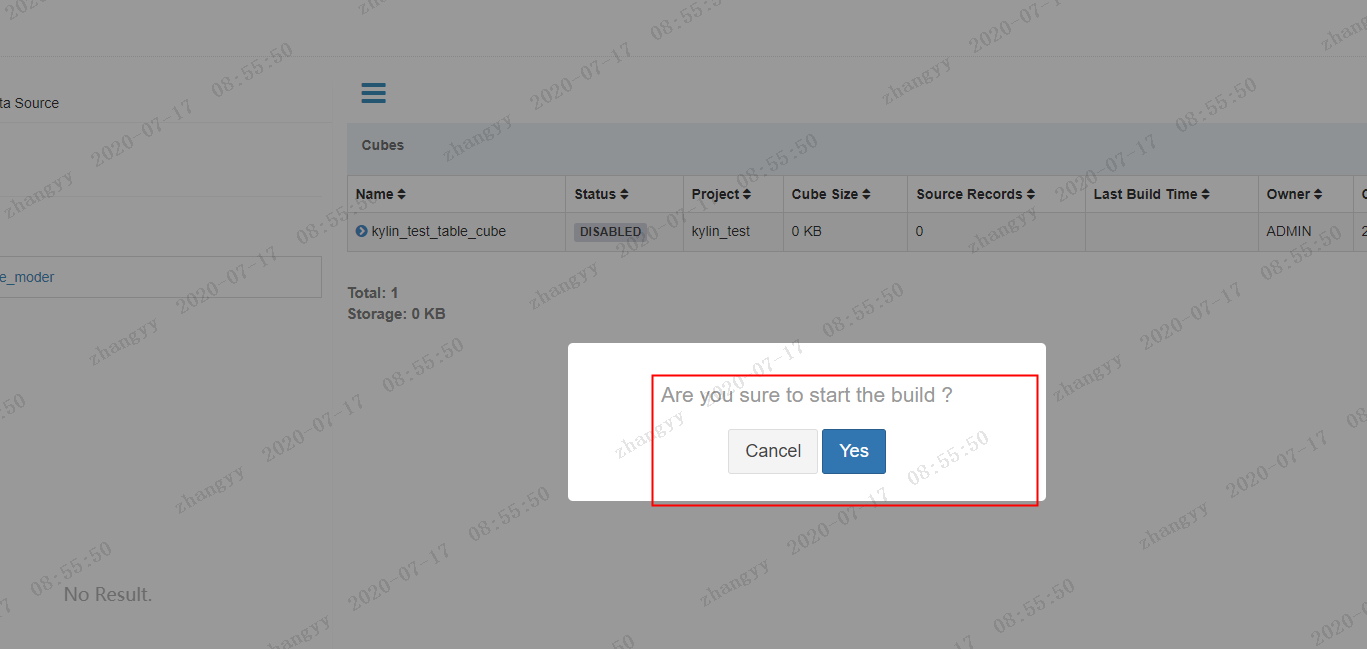
开始构建cube
这步 要消耗很长时间,具体 看 硬件配置
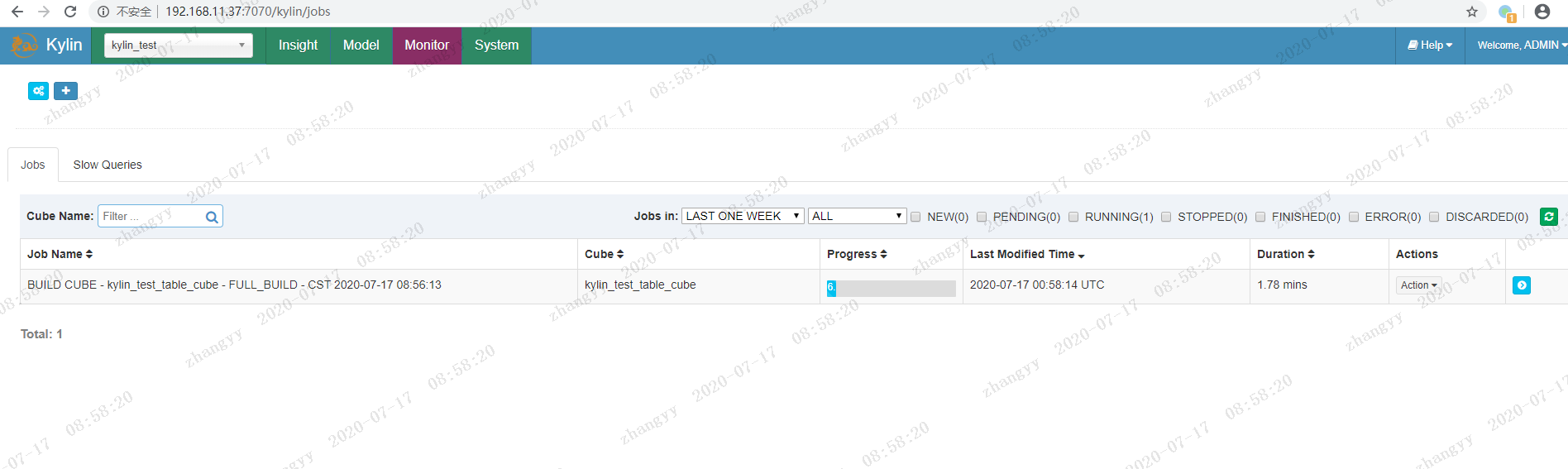

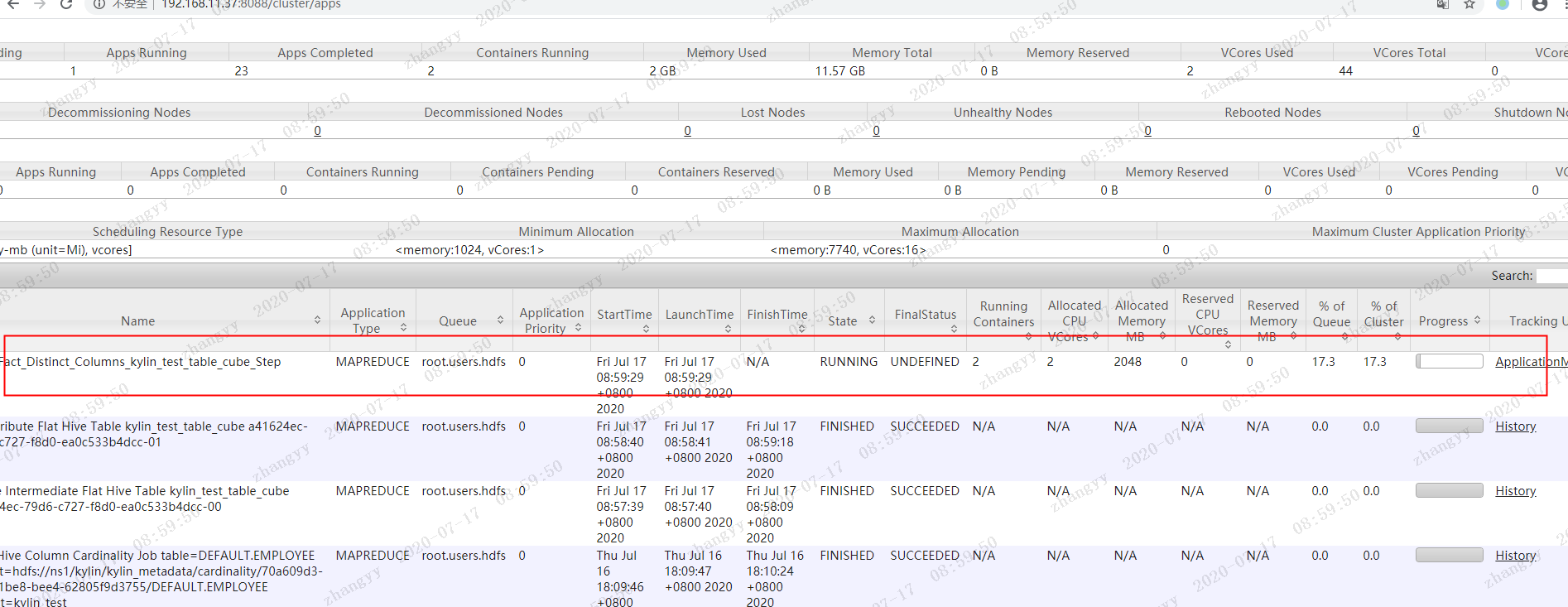
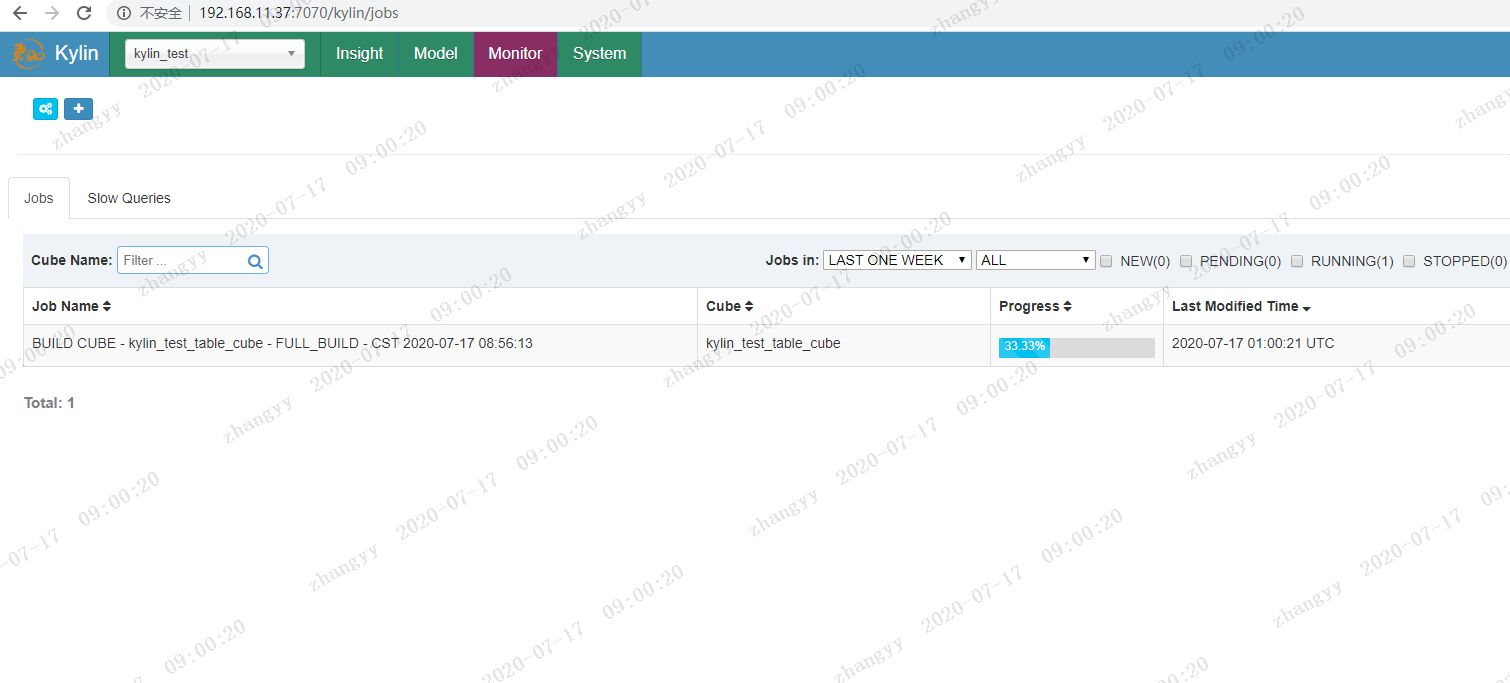
构建完成
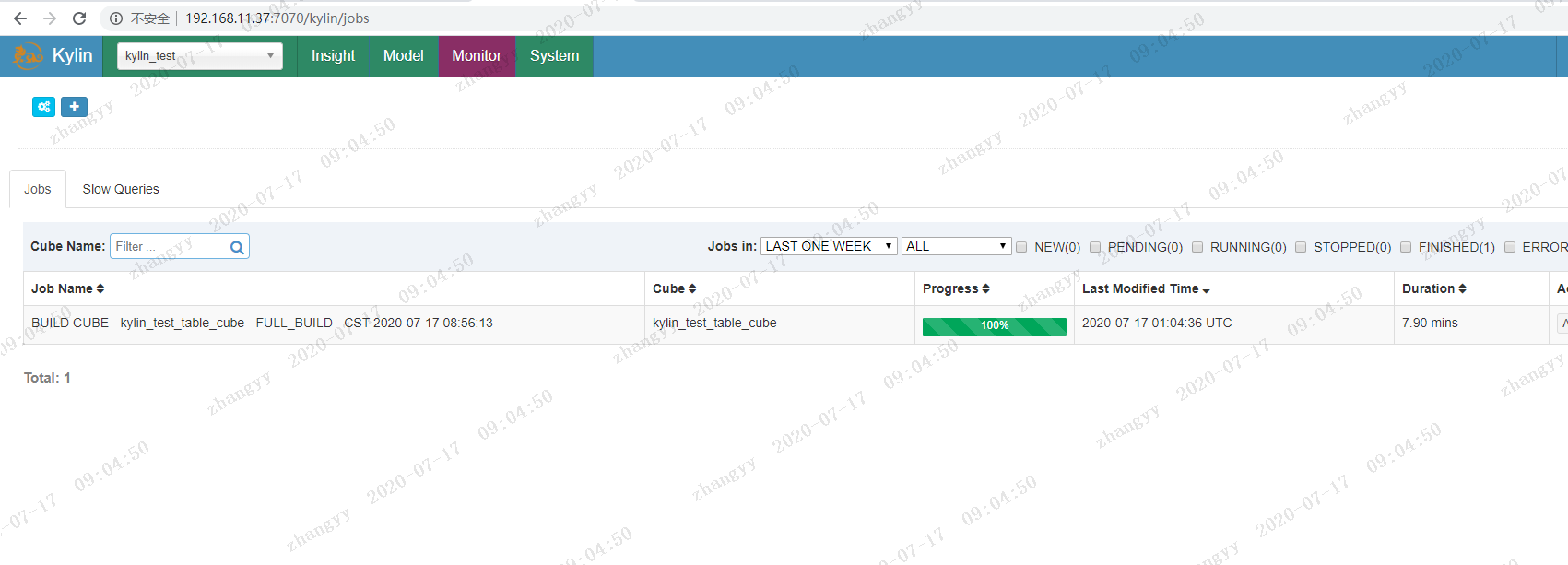
点击:insight
进行查询测试:
查询测试:
select count(*) from department;
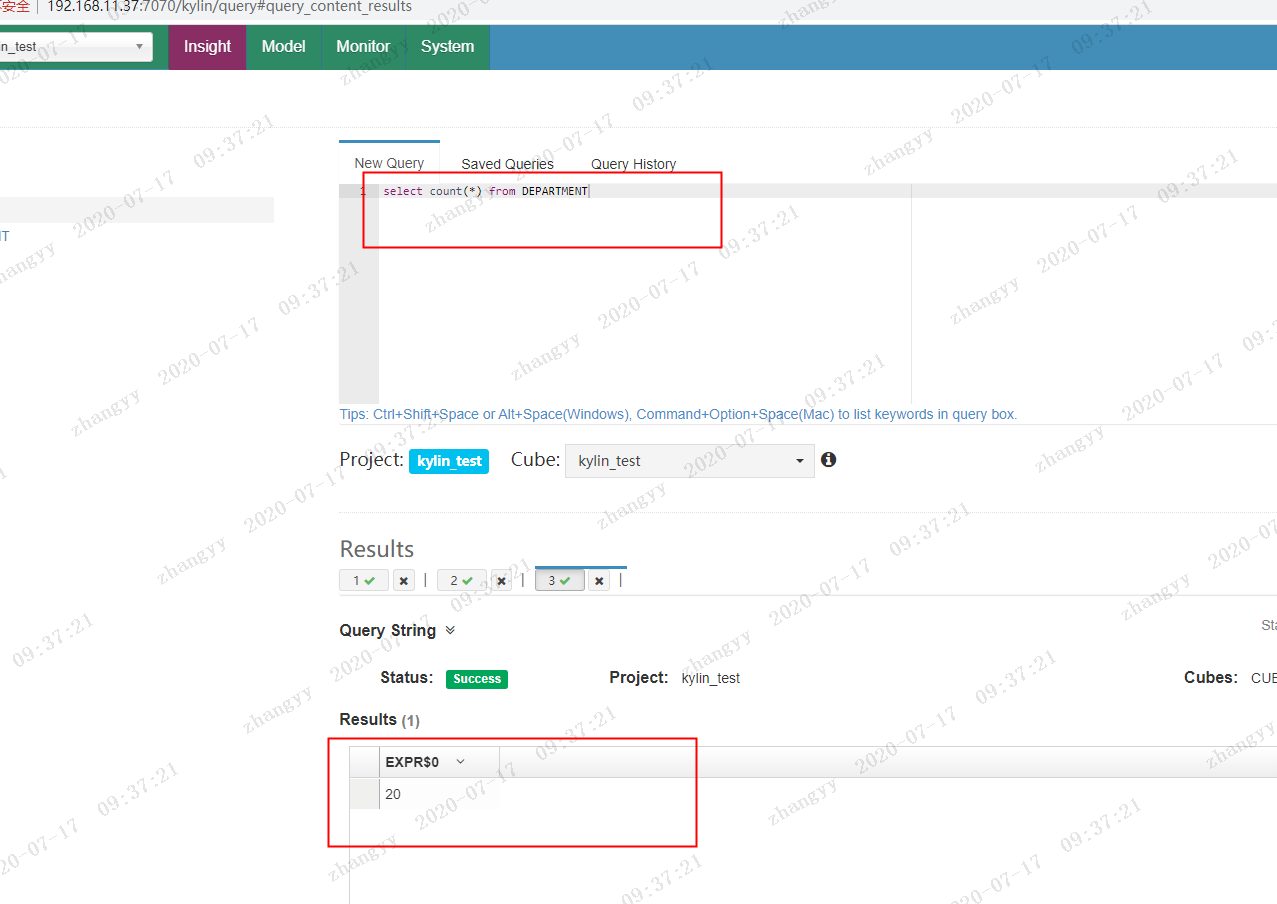
kylin 与hive 查询对比
统计各部门员工薪资总和:
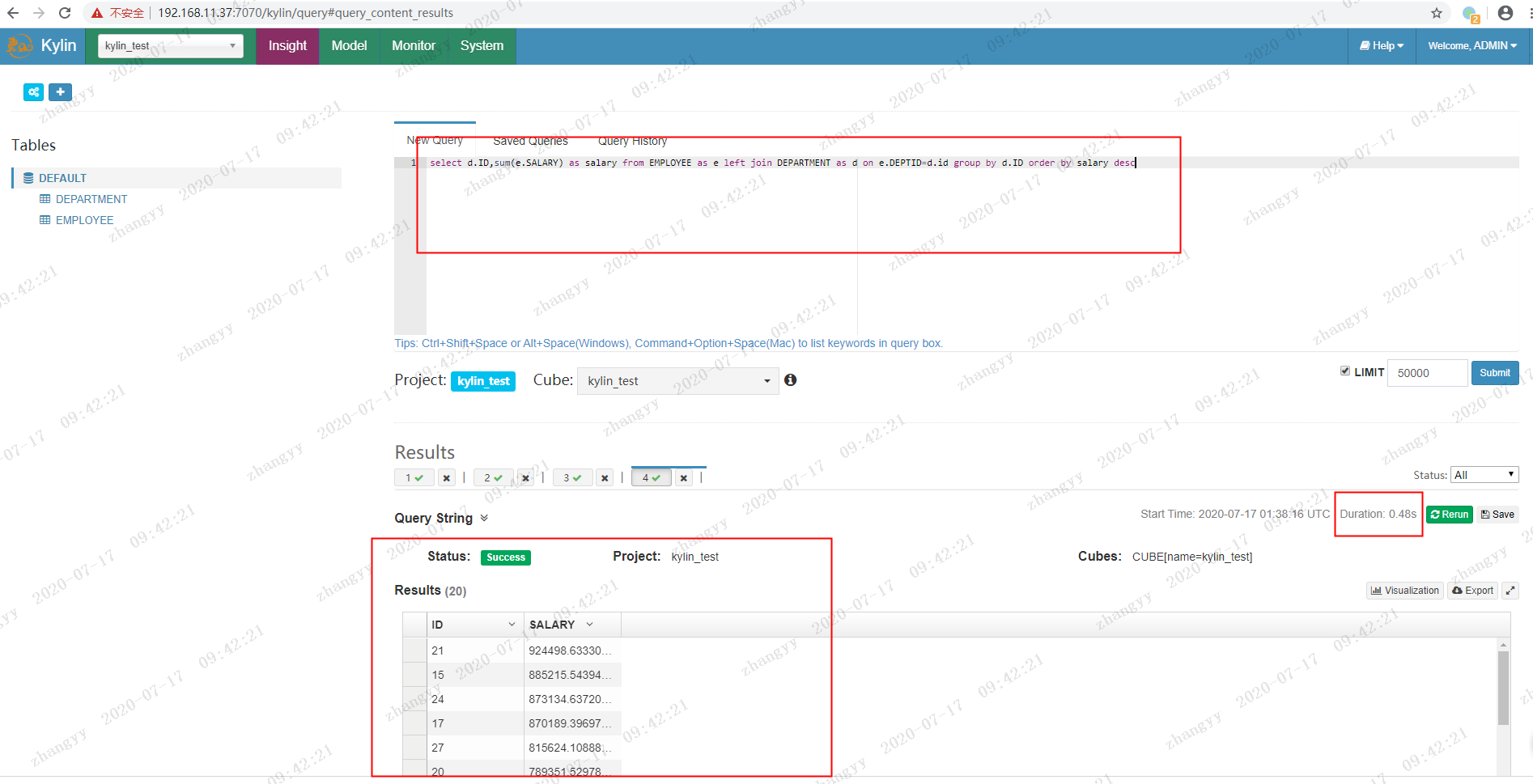
select d.ID,sum(e.SALARY) as salary from EMPLOYEE as e left join DEPARTMENT as d on e.DEPTID=d.id group by d.ID order by salary desc
kylin 查询
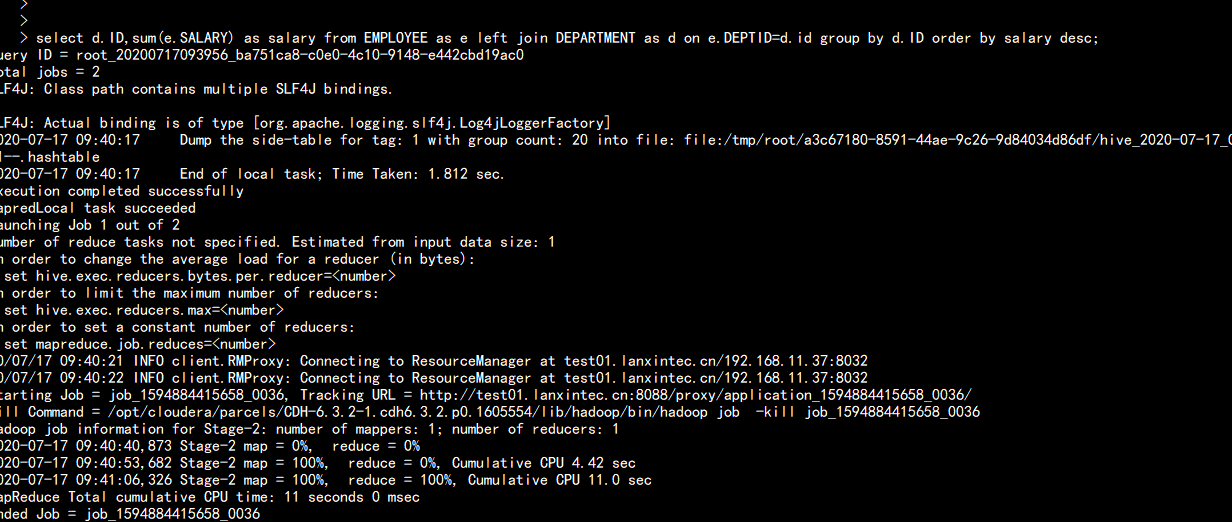
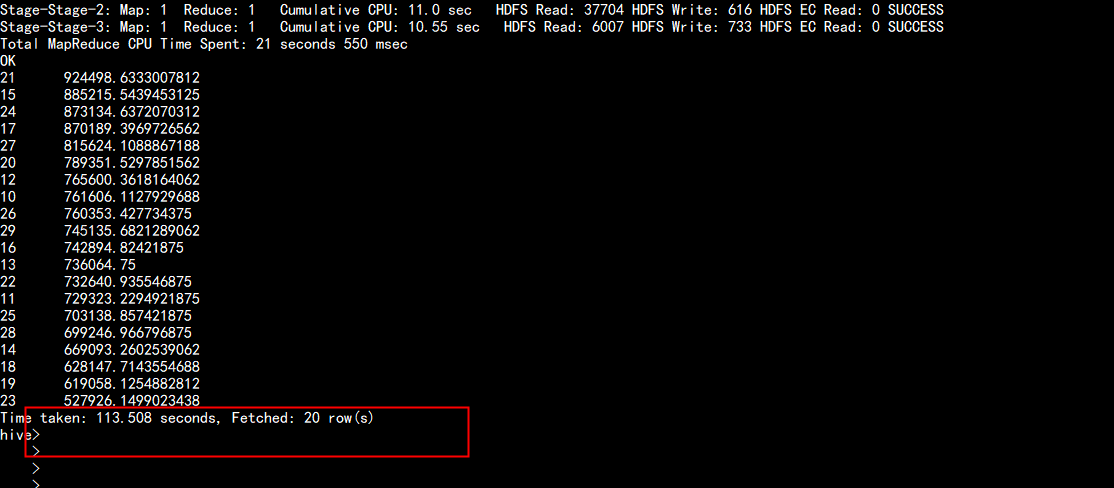
hive 查询
kylin 查询 只需要 0.48s
hive 查询 需要 113.508s




















