
资源限制
概念
- 当定义 Pod 时可以选择性地为每个容器设定所需要的资源数量。最常见可设定资源是 CPU 和内存大小,以及其他类型的资源
- 当为 Pod 中的容器指定了 request资源时,调度器就使用该信息来决定将 Pod 调度到哪个节点上。当还为容器指定了limit资源时,kubelet 就会确保运行的容器不会使用超出所设的 limit 资源量。kubelet 还会为容器预留所设的 request 资源量,供该容器使用
- 如果 Pod 运行所在的节点具有足够的可用资源,容器可以使用超出所设置的 request 资源量。不过,容器不可以使用超出所设置的 limit 资源量
- 如果给容器设置了内存的 limit 值,但未设置内存的 request 值,Kubernetes 会自动为其设置与内存 limit 相匹配的 request值。类似的,如果给容器设置了 CPU 的 limit 值但未设置CPU 的 request 值,则 Kubernetes 自动为其设置 CPU 的 request 值 并使之与CPU 的 limit 值匹配
- 官网示例 https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/
补充:
request 和 limit
request
- 容器使用的最小资源需求, 作为容器调度时资源分配的判断依赖。
- 只有当前节点上可分配的资源量 >= request 时才允许将容器调度到该节点。
- request参数不限制容器的最大可使用资源
limit
- 容器能使用资源的最大值
- 设置为0表示对使用的资源不做限制, 可无限的使用
request 和 limit 关系
request能保证pod有足够的资源来运行, 而limit则是防止某个pod无限制的使用资源, 导致其他pod崩溃. 两者的关系必须满足:
0 <= request <= limit如果limit=0表示不对资源进行限制, 这时可以小于request。
目前CPU支持设置request和limit,memory只支持设置request, limit必须强制等于request, 这样确保容器不会因为内存的使用量超过request但是没有超过limit的情况下被意外kill掉。
Pod和容器的资源请求和限制
spec.containers[].resources. requests.cpu #定义创建容器时预分配的CPU资源
spec.containers[].resources.requests.memory #定义创建容器时预分配的内存资源
spec.containers[].resources.limits.cpu #定义 cpu 的资源上限
spec.containers[].resources.limits.memory #定义内存的资源上限
CPU资源单位
- CPU 资源的 request 和 limit 以 cpu 为单位。Kubernetes 中的一个 cpu 相当于1个 vCPU(1个超线程)
- Kubernetes 也支持带小数 CPU 的请求。spec.containers[].resources.requests.cpu 为0.5的容器能够获得一个 cpu 的一半 CPU资源(类似于Cgroup对CPU资源的时间分片)。表达式0.1等价于表达式 100m(毫核),表示每1000毫秒内容器可以使用的CPU时间总量为0.1*1000 毫秒
内存资源单位
- 内存的 request 和 limit 以字节为单位。 可以以整数表示,或者以10为底数的指数的单位(E、P、T、G、M、K)来表示,或者以2为底数的指数的单位(Ei、Pi、Ti、Gi、Mi、Ki)来表示。如1KB=103=1000,1MB=106=1000000=1000KB,1GB=10^9=1000000000=1000MB 1KiB=2^10=1024, 1MiB=2^20=1048576=1024KiB
- PS∶在买硬盘的时候,操作系统报的数量要比产品标出或商家号称的小一些,主要原因是标出的是以 MB、GB为单位的,1GB 就是1,000,000,000Byte,而操作系统是以2进制为处理单位的,,因此检查硬盘容量时是以MiB、GiB为单位,1GB=2^30=1,073,741,824,相比较而言,1GiB要比1GB多出1,073,741,824-1,000,000,000=73,741,824Byte,所以检测实际结果要比标出的少—些
实例
1.kubectl run nginx1 --image=nginx --port=80 --replicas=2 --dry-run -o yaml > demo1.yaml
#直接导出一个yaml模板进行修改,对cpu和内存进行预设和限制
2.vim demo1.yaml
==========================================================
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
run: nginx1
name: nginx1
spec:
replicas: 2
selector:
matchLabels:
run: nginx1
template:
metadata:
labels:
run: nginx1
spec:
containers:
- image: nginx
name: nginx1
ports:
- containerPort: 80
resources:
requests:
memory: "100Mi"
cpu: "250m"
limits:
memory: "200Mi"
cpu: "500m"
此例子中的 Pod 有两个容器。每个容器的 request 值为 0.25 cpu 和 100MiB 预设内存,每个容器的 limit 值为 0.5 cpu 和 200MiB 内存。那么可以认为该 Pod 的总的资源 request 为 0.5 cpu 和 200 MiB 内存,总的资源 limit 为 1 cpu 和 400MiB 内存。
3.kubectl apply -f demo1.yaml
4.kubectl describe pods
5.kubectl describe node node01
kubectl describe node node02




实例2
======示例2:======
vim pod2.yaml
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: web
image: nginx
env:
- name: WEB_ROOT_PASSWORD
value: "password"
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- name: wp
image: wordpress
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
kubectl apply -f pod2.yaml
kubectl describe pod frontend
kubectl get pods -o wide
kubectl describe nodes node02 #由于当前虚拟机有2个CPU,所以Pod的CPU Limits一共占用了50%




重启策略
Pod 在遇到故障之后重启的动作 1.Always:当容器终止退出后,总是重启容器,默认策略 2.OnFailure:当容器异常退出(退出状态码非0)时,重启容器;正常退出则不重启容器 3.Never:当容器终止退出,从不重启容器
注:K8S 中不支持重启 Pod 资源,只有删除重建
======示例======
vim pod3.yaml
apiVersion: v1
kind: Pod
metadata:
name: foo
spec:
containers:
- name: busybox
image: busybox
args:
- /bin/sh
- -c
- sleep 30; exit 3
kubectl apply -f pod3.yaml
======查看Pod状态,等容器启动后30秒后执行exit退出进程进入error状态,就会重启次数加1======
kubectl get pods
kubectl delete -f pod3.yaml
vim pod3.yaml
apiVersion: v1
kind: Pod
metadata:
name: foo
spec:
containers:
- name: busybox
image: busybox
args:
- /bin/sh
- -c
- sleep 30; exit 3
restartPolicy: Never
#注意:跟container同一个级别
kubectl apply -f pod3.yaml
//容器进入error状态不会进行重启
kubectl get pods -w
健康检查∶又称为探针(Probe)
探针的三种规则
1.livenessProbe(存活探针) ∶判断容器是否正在运行。如果探测失败,则kubelet会杀死容器,并且容器将根据 restartPolicy 来设置 Pod 状态。如果容器不提供存活探针,则默认状态为Success
2.readinessProbe(就绪探针) ∶判断容器是否准备好接受请求。如果探测失败,端点控制器将从与 Pod 匹配的所有 service endpoints 中剔除该Pod的IP地址。初始延迟之前的就绪状态默认为Failure。如果容器不提供就绪探针,则默认状态为Success
3.startupProbe (启动探针)(这个1.17版本增加的)∶判断容器内的应用程序是否已启动,主要针对于不能确定具体启动时间的应用。如果配置了startupProbe 探测,在则在 startupProbe 状态为 success 之前,其他所有探针都处于无效状态,直到它成功后其他探针才起作用。如果startupProbe 失败,kubelet 将杀死容器,容器将根据 restartPolicy 来重启。如果容器没有配置 startupProbe,则默认状态为 Success
4.注∶以上规则可以同时定义。在readinessProbe检测成功之前,Pod的running状态是不会变成ready状态的
livenessProbe:存活检测。探测失败,kubelet会杀死容器,且容器服从其重启策略。不设该字段,默认Success
readinessProbe:就绪探测。探测失败,端点控制器将从与pod匹配的所有svc端点中删除pod的ip地址。
startupProbe:探测容器内应用是否已启动。如果启用startupProbe,则禁用其他探测,知道它成功为止。探测失败,kubelet将杀死容器,容器服从重启策略
Probe支持三种检查方法(探针使用的三种方式)
1.exec :在容器内执行指定命令。如果命令退出时返回码为0则认为诊断成功
2.tcpSocket :对指定端口上的容器的IP地址进行TCP检查(三次握手)。如果端口打开,则诊断被认为是成功的
3.httpGet :对指定的端口和路径上的容器的IP地址执行HTTPGet请求。如果响应的状态码大于等于200且小于400,则诊断被认为是成功的
每次探测都将获得以下三种结果
- 成功:容器通过了诊断
- 失败:容器未通过诊断
- 未知:诊断失败,因此不会采取任何行动
- 官网示例: https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
示例1∶exec方式
vim demo2.yaml
==========================================================
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 60
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
failureThreshold: 1
initialDelaySeconds: 5
periodSeconds: 5
==========================================================
#initialDelaySeconds∶指定 kubelet 在执行第一次探测前应该等待5秒,即第一次探测是在容器启动后的第6秒才开始执行。默认是 0 秒,最小值是 0。
#periodSeconds∶指定了 kubelet 应该每 5 秒执行一次存活探测。默认是 10 秒。最小值是 1。
#failureThreshold∶当探测失败时,Kubernetes 将在放弃之前重试的次数。存活探测情况下的放弃就意味着重新启动容器。就绪探测情况下的放弃 Pod 会被打上未就绪的标签。默认值是 3。最小值是 1。
#timeoutSeconds∶探测超时后等待多少秒。默认值是 1 秒。最小值是 1。(在 Kubernetes 1.20 版本之前,exec 探针会忽略timeoutSeconds 探针会无限期地持续运行,甚至可能超过所配置的限期,直到返回结果为止。)
可以看到 Pod 中只有一个容器。kubelet 在执行第一次探测前需要等待 5 秒,kubelet 会每 5 秒执行一次存活探测。kubelet在容器内执行命令 cat /tmp/healthy 来进行探测。如果命令执行成功并且返回值为 0,kubelet 就会认为这个容器是健康存活的。当到达第31 秒时,这个命令返回非 0 值,kubelet会杀死这个容器并重新启动它。
==========================================================
kubectl apply -f demo2.yaml
#查看在探测失败后重新拉取容器
kubectl describe pod liveness-exec


示例2∶httpGet方式
vim demo3.yaml
==========================================================
apiVersion: v1
kind: Pod
metadata:
name: liveness-httpget
namespace: default
spec:
containers:
- name: liveness-httpget-container
image: nginx
imagePullPolicy: IfNotPresent
ports:
- name: nginx
containerPort: 80
livenessProbe:
httpGet:
port: nginx #指定端口,这里使用的是之前的ports里的name,也可以直接写端口
path: /index.html #指定路径
initialDelaySeconds: 1
periodSeconds: 3
timeoutSeconds: 10
==========================================================
在这个配置文件中, 可以看到 Pod 也只有一个容器。initialDelaySeconds 字段告诉 kubelet 在执行第一次探测前应该等待 3秒。periodSeconds 字段指定了 kubelet 每隔 3 秒执行一次存活探测。 timeoutSeconds字段指定了超时等待时间为10S,kubelet 会向容器内运行的服务(服务会监听 80端口)发送一个HTTP GET 请求来执行探测。如果服务器上/index.html路径下的处理程序返回成功代码,则 kubelet 认为容器是健康存活的。如果处理程序返回失败代码,则 kubelet 会杀死这个容器并且重新启动它。
任何大于或等于 200 并且小于 400 的返回代码标示成功,其它返回代码都标示失败。
==========================================================
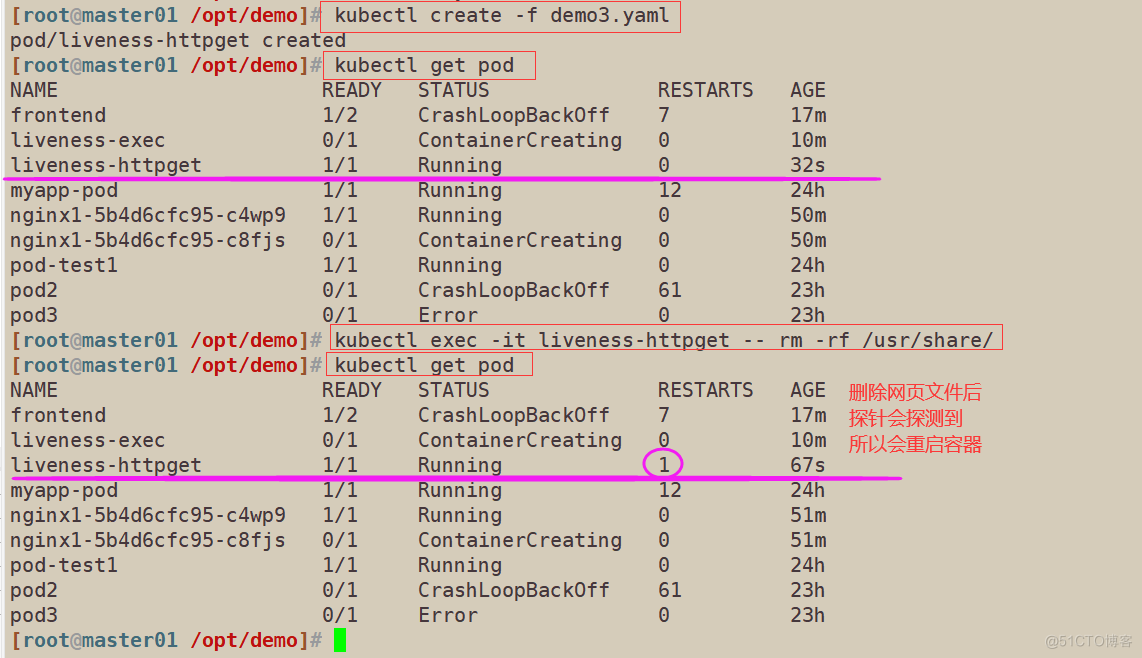
#加载yaml文件
kubectl create -f demo3.yaml
#进入容器删除网页文件进行测试
kubectl exec -it liveness-httpget -- rm -rf /usr/share/
nginx/html/index.html
#查看pod的详细参数
kubectl get pod
kubectl describe pod liveness-httpget


示例3∶tcpSocket方式
vim demo4.yaml
==========================================================
apiVersion: v1
kind: Pod
metadata:
name: probe-tcp
spec:
containers:
- name: tcpnginx
image: nginx
ports:
- containerPort: 80
readinessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 15
periodSeconds: 20
==========================================================
#加载yaml文件
kubectl create -f demo4.yaml
#查看pod的信息
kubectl get pod
kubectl describe pod probe-tcp



容器启动、退出动作
vim demo1.yaml
==========================================================
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: soscscs/myapp:v1
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", " echo '333333' >> /var/log/nginx/message"]
preStop:
exec:
command: ["/bin/sh", "-c", " echo '222222' >> /var/log/nginx/message"]
volumeMounts:
- name: message-log
mountPath: /var/log/nginx/
readOnly: false
initContainers:
- name: init-myservice
image: soscscs/myapp:v1
command: ["/bin/sh", "-c", "echo '111111' >> /var/log/nginx/message"]
volumeMounts:
- name: message-log
mountPath: /var/log/nginx/
readOnly: false
volumes:
- name: message-log
hostPath:
path: /data/volumes/nginx/log/
type: DirectoryOrCreate
==========================================================
kubectl apply -f demo1.yaml
kubectl get pods -o wide
在node01上节点上查看
cat /data/volumes/nginx/log/message
总结
1.k8s重启策略
Pod 在遇到故障之后重启的动作
1.Always:当容器终止退出后,总是重启容器,默认策略
2.OnFailure:当容器异常退出(退出状态码非0)时,重启容器;正常退出则不重启容器
3.Never:当容器终止退出,从不重启容器
注:K8S 中不支持重启 Pod 资源,只有删除重建
2. k8s探针(3 种)
1.livenessProbe(存活探针)∶判断容器是否正常运行,如果失败则杀掉容器(不是pod),再根据重启策略是否重启容器 2.readinessProbe(就绪探针)∶判断容器是否能够进入ready状态,探针失败则进入noready状态,并从service的endpoints中剔除此容器 3.startupProbe∶判断容器内的应用是否启动成功,在success状态前,其它探针都处于无效状态
3.k8s探测方式(3种)/probe检查方法(3种)
1.exec∶使用 command 字段设置命令,在容器中执行此命令,如果命令返回状态码为0,则认为探测成功 2.httpget∶通过访问指定端口和url路径执行http get访问。如果返回的http状态码为大于等于200且小于400则认为成功 3.tcpsocket∶通过tcp连接pod(IP)和指定端口,如果端口无误且tcp连接成功,则认为探测成功
4. k8s探针可选的参数
1.initialDelaySeconds∶ 容器启动多少秒后开始执行探测 2.periodSeconds∶探测的周期频率,每多少秒执行一次探测 3.failureThreshold∶探测失败后,允许再试几次 4.timeoutSeconds ∶ 探测等待超时的时间
5.k8s资源限制
spec.containers.resources. requests.cpu #定义创建容器时预分配的CPU资源 spec.containers.resources.requests.memory #定义创建容器时预分配的内存资源 spec.containers.resources.limits.cpu #定义 cpu 的资源上限 spec.containers.resources.limits.memory #定义内存的资源上限
6. k8s pod中应用容器的启动,退出动作
spec.containers.lifecycle.postStart 配合 exec.command
spec.containers.lifecycle.preStop 配合 exec.command


















