
系列文章
前言
实际应用中除了基于 Metrics 告警, 往往还有基于日志的告警需求, 可以作为基于 Metrics 告警之外的一个补充. 典型如基于 NGINX 日志的错误率告警.本文将介绍如何基于 Loki 实现基于日志的告警.
本文我们基于以下 2 类实际场景进行实战演练:
- 基于 NGINX 日志的错误率告警
- 基于 Nomad 日志的心跳异常告警(关于 Nomad 的介绍, 可以参见这篇文章: 《大规模 IoT 边缘容器集群管理的几种架构 -2-HashiCorp 解决方案 Nomad》)
基于日志告警的应用场景
基于日志告警的广泛应用于如下场景:
黑盒监控
对于不是我们开发的组件, 如云厂商/第三方的负载均衡器和无数其他组件(包括开源组件和封闭第三方组件)支持我们的应用程序,但不会公开我们想要的指标。有些根本不公开任何指标。 Loki 的警报和记录规则可以生成有关系统状态的指标和警报,并通过使用日志将组件带入我们的可观察性堆栈中。这是一种将高级可观察性引入遗留架构的极其强大的方法。
事件告警
有时,您想知道某件事情是否已经发生。根据日志发出警报可以很好地解决这个问题,例如查找身份验证凭据泄露的示例:
- name: credentials_leak
rules:
- alert: http-credentials-leaked
annotations:
message: "{{ $labels.job }} is leaking http basic auth credentials."
expr: 'sum by (cluster, job, pod) (count_over_time({namespace="prod"} |~ "http(s?)://(\\w+):(\\w+)@" [5m]) > 0)'
for: 10m
labels:
severity: critical
关于 Nomad 的就属于这类场景.
技术储备
Loki 告警
Grafana Loki 包含一个名为 ruler 的组件。Ruler 负责持续评估一组可配置查询并根据结果执行操作。其支持两种规则:alerting 规则和 recording 规则。
Loki Alering 规则
Loki 的告警规则格式几乎与 Prometheus 一样. 这里举一个完整的例子:
groups:
- name: should_fire
rules:
- alert: HighPercentageError
expr: |
sum(rate({app="foo", env="production"} |= "error" [5m])) by (job)
/
sum(rate({app="foo", env="production"}[5m])) by (job)
> 0.05
for: 10m
labels:
severity: page
annotations:
summary: High request latency
- name: credentials_leak
rules:
- alert: http-credentials-leaked
annotations:
message: "{{ $labels.job }} is leaking http basic auth credentials."
expr: 'sum by (cluster, job, pod) (count_over_time({namespace="prod"} |~ "http(s?)://(\\w+):(\\w+)@" [5m]) > 0)'
for: 10m
labels:
severity: critical
Loki LogQL 查询
Loki 日志查询语言 (LogQL) 是一种查询语言,用于从 Loki 中检索日志。LogQL 与 Prometheus 非常相似,但有一些重要的区别。
LogQL 快速上手
所有 LogQL 查询都包含日志流选择器(log stream selector)。如下图:

可选择在日志流选择器后添加日志管道(log pipeline)。日志管道是一组阶段表达式,它们串联在一起并应用于选定的日志流。每个表达式都可以过滤、解析或更改日志行及其各自的标签。
以下示例显示了正在运行的完整日志查询:
{container="query-frontend",namespace="loki-dev"}
|= "metrics.go"
| logfmt
| duration > 10s
and throughput_mb < 500
该查询由以下部分组成:
- 日志流选择器
{container="query-frontend",namespace="loki-dev"},其目标是loki-dev命名空间中的query-frontend容器。 - 日志管道
|= "metrics.go" | logfmt | duration > 10s and throughput_mb < 500它将过滤掉包含单词metrics.go的日志,然后解析每个日志行以提取更多标签并使用它们进行过滤。
解析器表达式
为了进行告警, 我们往往需要在告警之前对非结构化日志进行解析, 解析后会获得更精确的字段信息(称为label), 这就是为什么我们需要使用解析器表达式.
解析器表达式可从日志内容中解析和提取标签(label)。这些提取的标签可用于使用标签过滤表达式进行过滤,或用于 metrics 汇总。
如果原始日志流中已经存在提取的标签 key名称(典型如: level),提取的标签 key 将以 _extracted 关键字为后缀,以区分两个标签。你也可以使用标签格式表达式强行覆盖原始标签。不过,如果提取的键出现两次,则只保留第一个标签值。
Loki 支持 JSON、logfmt、pattern、regexp 和 unpack 解析器。
今天我们重点介绍下 logfmt, pattern 和 regexp 解析器。
logfmt 解析器
logfmt 解析器可以以两种模式运行:
不带参数
可以使用 | logfmt 添加 logfmt 解析器,并将从 logfmt 格式的日志行中提取所有键和值。
例如以下日志行:
at=info method=GET path=/ host=grafana.net fwd="124.133.124.161" service=8ms status=200
将提取到以下标签:
"at" => "info"
"method" => "GET"
"path" => "/"
"host" => "grafana.net"
"fwd" => "124.133.124.161"
"service" => "8ms"
"status" => "200"
带参数
与 JSON 解析器类似,在管道中使用 | logfmt label="expression", another="expression" 将导致只提取标签指定的字段。
例如, | logfmt host, fwd_ip="fwd" 将从以下日志行中提取标签 host 和 fwd :
at=info method=GET path=/ host=grafana.net fwd="124.133.124.161" service=8ms status=200
并将 fwd 重命名为 fwd_ip:
"host" => "grafana.net"
"fwd_ip" => "124.133.124.161"
Pattern 解析器
Pattern 解析器允许通过定义模式表达式(| pattern "<pattern-expression>")从日志行中明确提取字段。该表达式与日志行的结构相匹配。
典型如 NGINX 日志:
0.191.12.2 - - [10/Jun/2021:09:14:29 +0000] "GET /api/plugins/versioncheck HTTP/1.1" 200 2 "-" "Go-http-client/2.0" "13.76.247.102, 34.120.177.193" "TLSv1.2" "US" ""
该日志行可以用表达式解析:
<ip> - - <_> "<method> <uri> <_>" <status> <size> <_> "<agent>" <_>
提取出这些字段:
"ip" => "0.191.12.2"
"method" => "GET"
"uri" => "/api/plugins/versioncheck"
"status" => "200"
"size" => "2"
"agent" => "Go-http-client/2.0"
Pattern 表达式由捕获(captures )和文字组成。
捕获是以 < 和 > 字符分隔的字段名。<example> 定义字段名 example。未命名的捕获显示为 <_>。未命名的捕获会跳过匹配的内容。
Regular Expression 解析器
logfmt 和 json 会隐式提取所有值且不需要参数,而 regexp 解析器则不同,它只需要一个参数 | regexp "<re>",即使用 Golang RE2 语法的正则表达式。
正则表达式必须包含至少一个命名子匹配(例如 (?P<name>re) ),每个子匹配将提取不同的标签。
例如,解析器 | regexp "(?P<method>\\w+) (?P<path>[\\w|/]+) \\((?P<status>\\d+?)\\) (?P<duration>.*)" 将从以下行中提取:
POST /api/prom/api/v1/query_range (200) 1.5s
到这些标签:
"method" => "POST"
"path" => "/api/prom/api/v1/query_range"
"status" => "200"
"duration" => "1.5s"
实战演练
📝说明:
下面的这 2 个例子只是为了演示 Loki 的实际使用场景. 实际环境中, 如果你通过 Prometheus 已经可以获取到如:
- NGINX 错误率
- Nomad Client 活跃数/Nomad Client 总数
则可以直接使用 Prometheus 进行告警. 不需要多此一举.
基于 NGINX 日志的错误率告警
我们将使用 | pattern 解析器从 NGINX 日志中提取 status label,并使用 rate() 函数计算每秒错误率。
假设 NGINX 日志如下:
0.191.12.2 - - [10/Jun/2021:09:14:29 +0000] "GET /api/plugins/versioncheck HTTP/1.1" 200 2 "-" "Go-http-client/2.0" "13.76.247.102, 34.120.177.193" "TLSv1.2" "US" ""
该日志行可以用表达式解析:
<ip> - - <_> "<method> <uri> <_>" <status> <size> <_> "<agent>" <_>
提取出这些字段:
"ip" => "0.191.12.2"
"method" => "GET"
"uri" => "/api/plugins/versioncheck"
"status" => "200"
"size" => "2"
"agent" => "Go-http-client/2.0"
再根据 status label 进行计算, status > 500 记为错误. 则最终告警语句如下:
sum(rate({job="nginx"} | pattern <ip> - - <_> "<method> <uri> <_>" <status> <size> <_> "<agent>" <_> | status > 500 [5m])) by (instance)
/
sum(rate({job="nginx"} [5m])) by (instance)
> 0.05
详细说明如下:
- 完整 LogQL 的含义是: NGINX 单个 instance 错误率 > 5%
{job="nginx"}Log Stream, 这里假设 NGINX 其job为nginx. 表明检索的是 NGINX 的日志.| pattern <ip> - - <_> "<method> <uri> <_>" <status> <size> <_> "<agent>" <_>使用 Pattern 解析器解析, 上文详细说明过了, 这里不做解释了| status > 500解析后得到statuslabel, 使用 Log Pipeline 筛选出status > 500的错误日志rate(... [5m])计算 5m 内的每秒 500 错误数sum () by (instance)按 instance 聚合, 即计算每个 instance 的每秒 500 错误数/ sum(rate({job="nginx"} [5m])) by (instance) > 0.05用 每个 instance 的每秒 500 错误数 / 每个 instance 的每秒请求总数得出每秒的错误率是否大于 5%
再使用该指标创建告警规则, 具体如下:
alert: NGINXRequestsErrorRate
expr: >-
sum(rate({job="nginx"} | pattern <ip> - - <_> "<method> <uri> <_>" <status> <size> <_> "<agent>" <_> | status > 500 [5m])) by (instance)
/
sum(rate({job="nginx"} [5m])) by (instance)
> 0.05
for: 1m
annotations:
summary: NGINX 实例{{ $labels.instance }}的错误率超过 5%.
description: ''
runbook_url: ''
labels:
severity: 'warning'
完成! 🎉🎉🎉
基于 Nomad 日志的心跳异常告警
Nomad 的日志的典型格式如下:
2023-12-08T21:39:09.718+0800 [WARN] nomad.heartbeat: node TTL expired: node_id=daf861cc-641d-f0a6-62ee-d954f6edd3a4
2023-12-07T21:39:04.905+0800 [ERROR] nomad.rpc: multiplex_v2 conn accept failed: error="keepalive timeout"
这里我尝试先使用 pattern 解析器进行解析, 解析表达式如下:
{unit="nomad.service", transport="stdout"}
| pattern <time> [<level>] <component>: <message>
结果解析异常, 解析后得到:
...
"level" => "WARN"
...
"level" => ERROR] nomad.rpc: multiplex_v2 conn accept failed: error="keepalive timeout"
level 解析明显不正确, 原因是 level 后面不是空格, 而是 tab 制表符. 导致在 [WARN] 时后面有 2 个空格; [ERROR] 时后面有 1 个空格. pattern 解析器对这种情况支持不好, 我查阅官方资料短期内并没有找到这种情况的解决办法.
所以最终只能通过 regexp 解析器进行解析.
最终的解析表达式如下:
{unit="nomad.service", transport="stdout"}
| regexp `(?P<time>\S+)\s+\[(?P<level>\w+)\]\s+(?P<component>\S+): (.+)
详细说明如下:
(?P<time>\S+)解析时间. 以 Nomad 的格式, 就是第一批非空格字符串. 如:2023-12-08T21:39:09.718+0800\s+匹配时间和日志级别之间的空格\[(?P<level>\w+)\]\匹配告警级别, 如[WARN][ERROR], 这里[]是特殊字符, 所以前面要加\作为普通字符处理\s+匹配日志级别和组件之间的空白字符. 无论是一个/两个空格, 还是一个 tab 都能命中(?P<component>\S+):匹配组件, 这里的\S+匹配至少一个非空白字符, 即匹配到组件名. 这一段匹配如:nomad.heartbeat:和nomad.rpc:. component匹配到nomad.heartbeat和nomad.rpc注意这里有一个空格. 改为\s也行(.+)匹配日志最后的内容, 这里的(.+)匹配至少一个非空白字符, 即匹配到日志内容. 如:node TTL expired: node_id=daf861cc-641d-f0a6-62ee-d954f6edd3a4
解析后得到:
"time" => 2023-12-08T21:39:09.718+0800
"level_extracted" => WARN
"component" => nomad.heartbeat
"message" => node TTL expired: node_id=daf861cc-641d-f0a6-62ee-d954f6edd3a4
"time" => 2023-12-07T21:39:04.905+0800
"level_extracted" => ERROR
"component" => nomad.rpc
"message" => multiplex_v2 conn accept failed: error="keepalive timeout"
解析后再以此进行告警, 告警条件暂定为: component = nomad.heartbeat, level_extracted =~ WARN|ERROR
具体 LogQL 为:
count by(job)
(rate(
{unit="nomad.service", transport="stdout"}
| regexp `(?P<time>\S+)\s+\[(?P<level>\w+)\]\s+(?P<component>\S+): (.+)`
| component = `nomad.heartbeat`
| level_extracted =~ `WARN|ERROR` [5m]))
> 3
详细说明如下:
- Nomad 日志流为:
{unit="nomad.service", transport="stdout"}
{unit="nomad.service", transport="stdout"}
| regexp `(?P<time>\S+)\s+\[(?P<level>\w+)\]\s+(?P<component>\S+): (.+)`
| component = `nomad.heartbeat`
| level_extracted =~ `WARN|ERROR`
- 筛选出 component 为 nomad.heartbeat, level_extracted 为
WARN|ERROR的日志条目 - 每秒心跳错误数 > 3 就告警
最终告警规则如下:
alert: Nomad HeartBeat Error
for: 1m
annotations:
summary: Nomad Server和Client之间心跳异常.
description: ''
runbook_url: ''
labels:
severity: 'warning'
expr: >-
count by(job) (rate({unit="nomad.service", transport="stdout"} | regexp
`(?P<time>\S+)\s+\[(?P<level>\w+)\]\s+(?P<component>\S+): (.+)` | component =
`nomad.heartbeat` | level_extracted =~ `WARN|ERROR` [5m])) > 3
完成🎉🎉🎉
善用 Grafana UI 进行 LogQL
Grafana UI 对于 LogQL 的支持比较好, 有完善的提示/帮助和指南, 以及非常适合不了解 LogQL 语法的 Builder 模式及 Explain 功能. 读者上手的时候不要被前面大段大段的 LogQL 和 YAML 吓到, 可以直接使用 Grafana 构造自己想要的基于日志的查询和告警.
Grafana 具体的功能增强有:
-
语法/拼写验证(查询表达式验证): 为了加快编写正确 LogQL 查询的过程,Grafana 9.4 添加了一项新功能:查询表达式验证。或者可以直观地叫做 "红色斜线 "功能,因为它使用的波浪线与您在文字处理器中输入错别字时看到的下划线文本相同🙂。有了查询验证功能,你就不必再运行查询来查看它是否正确了。相反,如果查询无效,你会得到实时反馈。出现这种情况时,红色斜线会显示错误的具体位置,以及哪些字符不正确。查询表达式验证还支持多行查询。
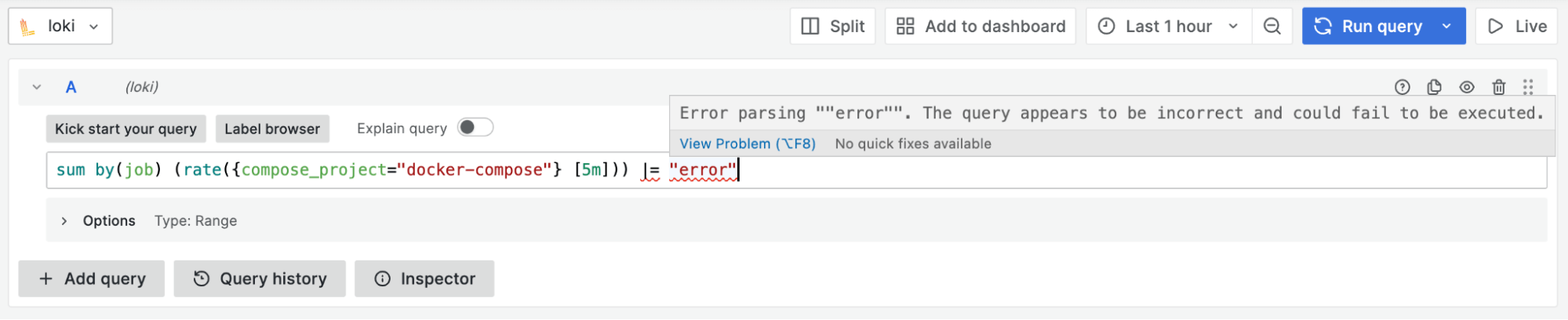
-
自动补全功能: 如可以根据查询查看建议的解析器类型(如
logfmt、JSON), 能帮助您为数据编写更合适的查询。此外,如果您在查询中使用解析器,所有标签(包括解析器提取的标签)都会在带分组的范围聚合(如sum by())中得到建议。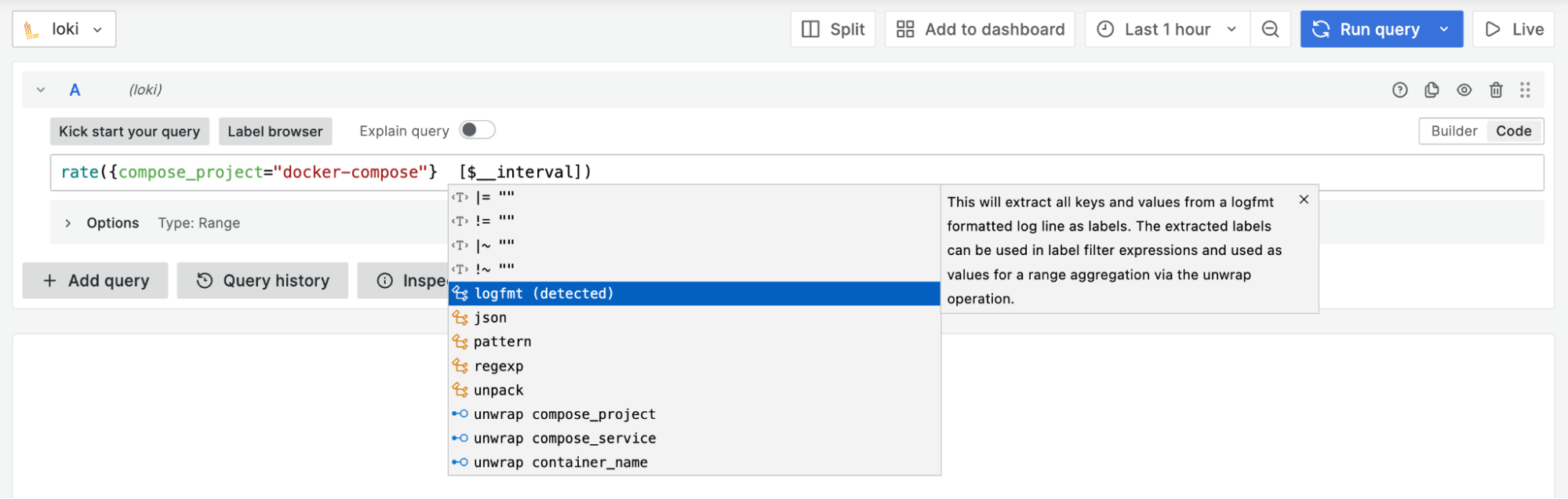
-
历史记录: Loki 的代码编辑器现在直接集成了查询历史记录。一旦您开始编写新查询,就会显示您之前运行的查询。此功能在 Explore 中特别有用,因为您通常不会从头开始,而是想利用以前的工作。
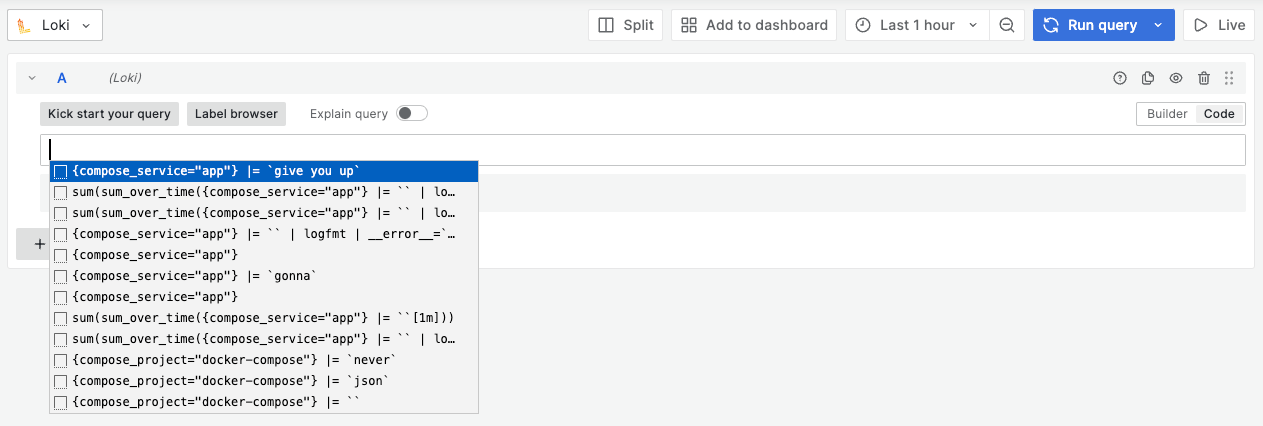
-
标签浏览器: 直接浏览所有标签, 并在查询中使用它们. 这对于快速浏览和查找标签非常有用.
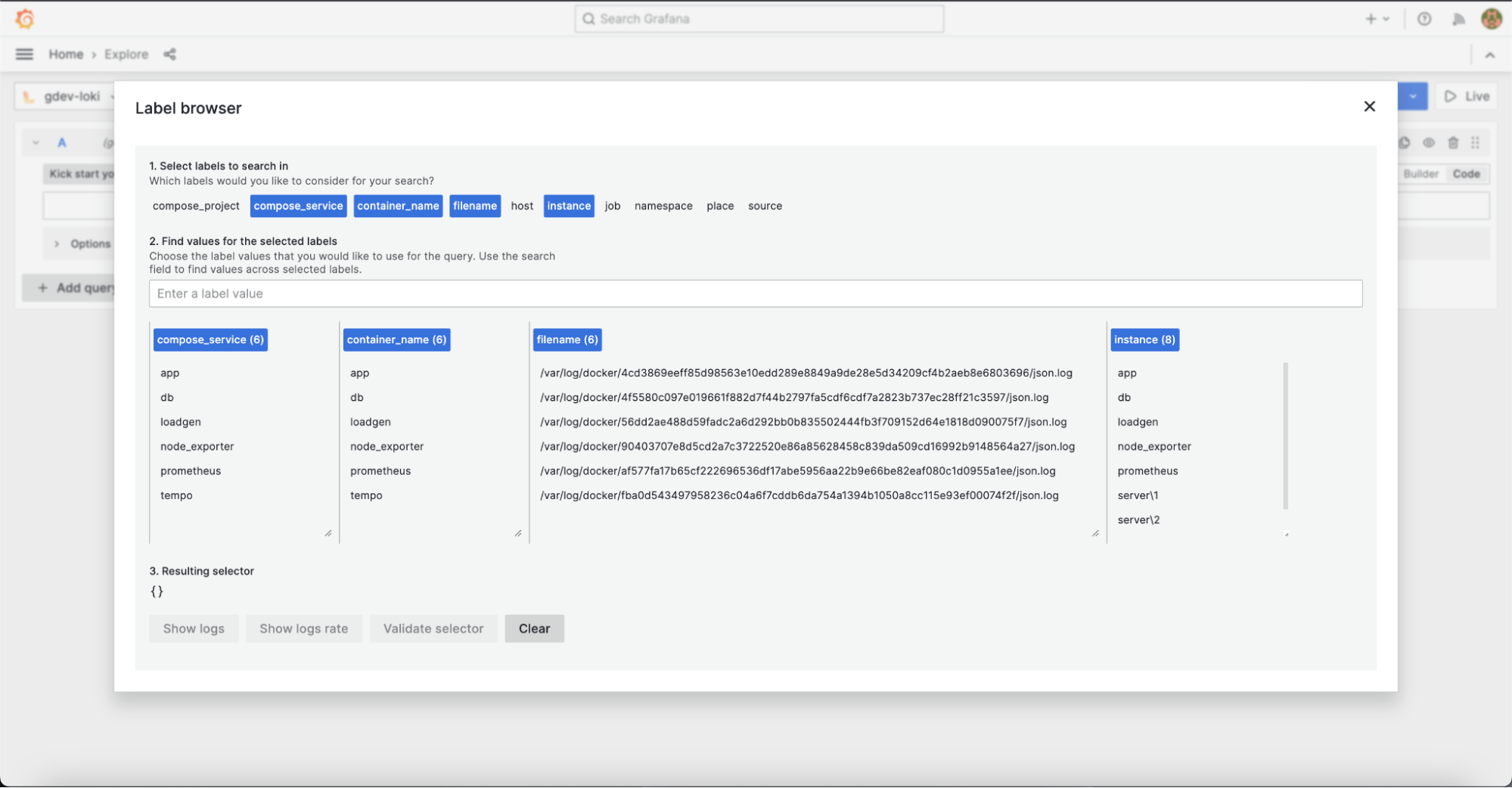
-
日志样本: 我们知道,很多在 Explore 中进行度量查询的用户都希望看到促成该度量的日志行示例。这正是在 Grafana 9.4 中提供的新功能!这将有助于调试过程,主要是通过基于日志行内容的行过滤器或标签过滤器帮助您缩小度量查询的范围。
我其实对 LogQL 也刚开始学习, 这次也是主要在 Grafana 的帮助下完成, 具体如下:
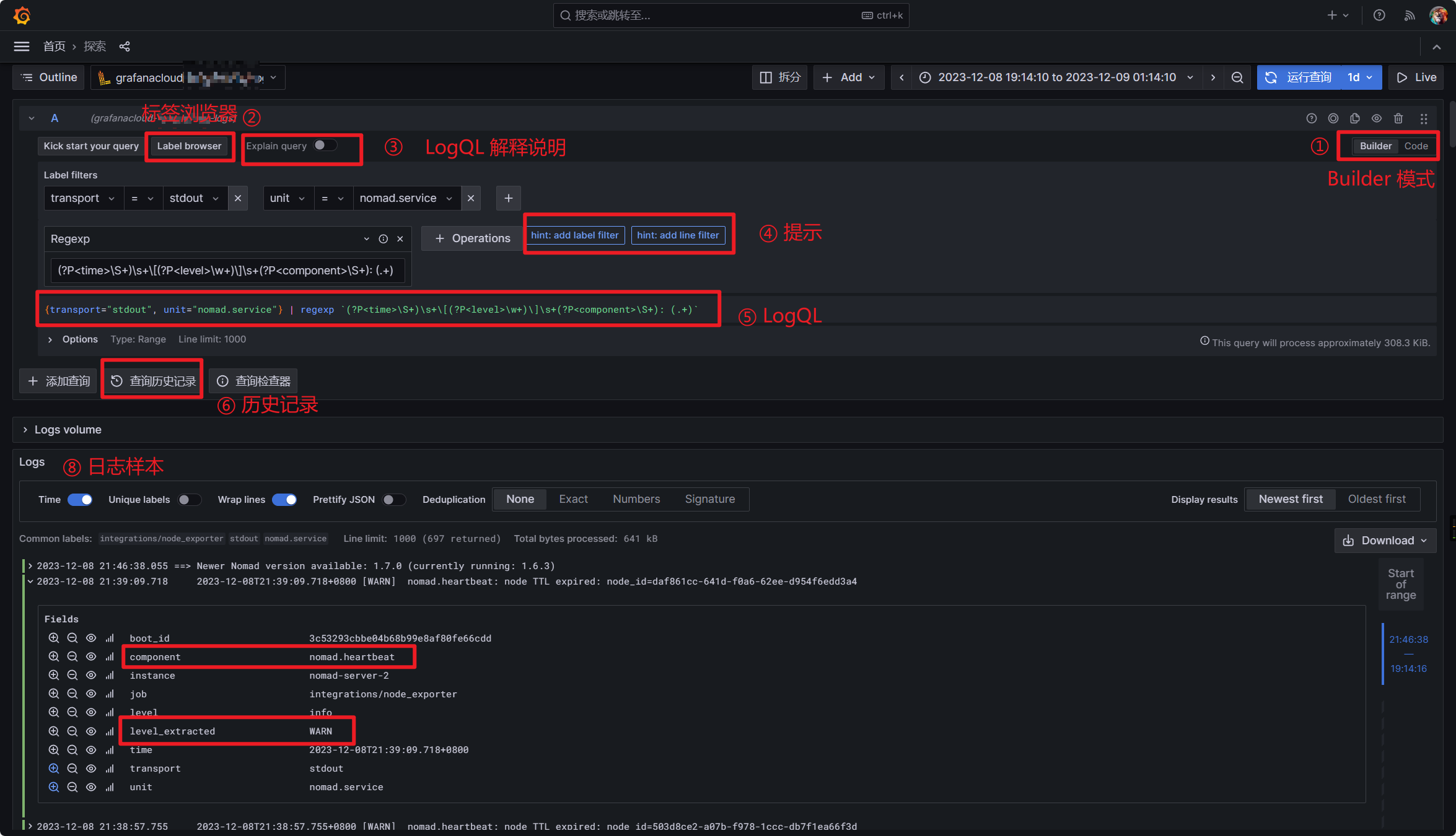
👍️👍️👍️
总结
以上就是基于 Loki 实现告警的基本流程. 告警之前往往需要对日志进行解析和筛选, 具体实现细节可以根据实际情况进行调整.
最后, 一定要结合 Grafana UI 进行 LogQL 的使用, 这样可以更加方便地进行 LogQL 的编写和调试.
希望本文对大家有所帮助.
📚️参考文档
- Log queries | Grafana Loki documentation --- 日志查询 | Grafana Loki 文档
- Loki 官方文档 - Alerting
- Write Loki queries easier with Grafana 9.4: Query validation, improved autocomplete, and more | Grafana Labs --- 使用 Grafana 9.4 更轻松地编写 Loki 查询:查询验证、改进的自动完成等等 |格拉法纳实验室
三人行, 必有我师; 知识共享, 天下为公. 本文由东风微鸣技术博客 EWhisper.cn 编写.




















