
欢迎来到图神经网络的世界,在这里我们在图上构建深度学习模型。你可以认为这很简单。毕竟,我们难道不能重用使用正常数据的模型吗?

其实不是。在图中所有的数据点(节点)是相互连接的。这意味着数据不再是独立的,这使得大多数标准的机器学习模型毫无用处,因为它们的推导都强烈地基于这个假设。为了克服这个问题,可以从图中提取数字数据,或者使用直接对这类数据进行操作的模型。
创建直接在图上工作的模型更为理想,因为我们可以获得更多关于图的结构和属性的信息。在本文中,我们将研究一种专门为此类数据设计的架构,即消息传递神经网络(MPNNs)。
模型的各种变体

在将模型标准化为单个MPNN框架之前,几位独立研究人员已经发布了不同的变体。 这种类型的结构在化学中特别流行,可以帮助预测分子的性质。
Duvenaud等人在2015年发表了有关该主题的第一批著作之一[1]。 他使用消息传递体系结构从图分子中提取有价值的信息,然后将其转换为单个特征向量。 当时,他的工作具有开创性,因为他使体系结构与众不同。 实际上是最早可以在图上运行的卷积神经网络体系结构之一。

Duvenaud等人创建的消息传递体系结构。 他将模型定义为可区分的层的堆栈,其中每一层是传递消息的另一轮。 修改自[1]
Li等人在2016年对此构架进行了另一尝试[2]。 在这里,他们专注于图的顺序输出,例如在图[2]中找到最佳路径。 为此,他们将GRU(门控循环单元)嵌入其算法中。
尽管这些算法似乎完全不同,但是它们具有相同的基本概念,即消息在图中的节点之间传递。 我们将很快看到如何将这些模型组合成一个框架。
将模型统一到MPNN框架
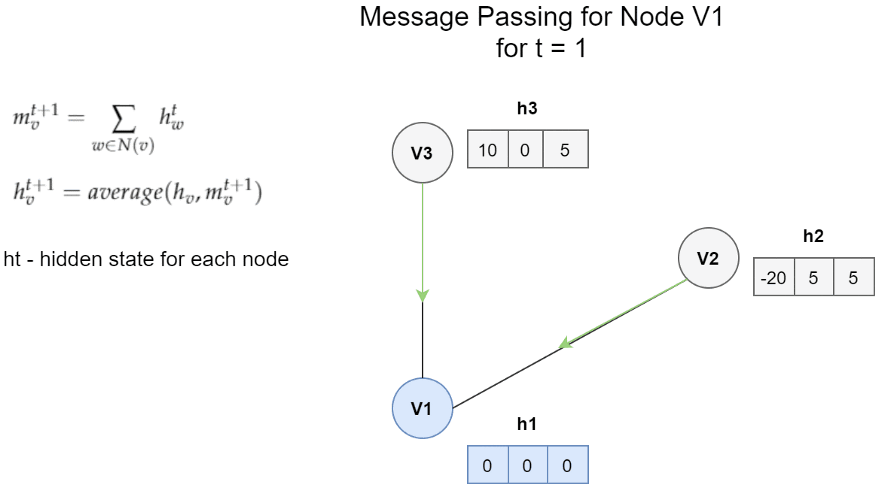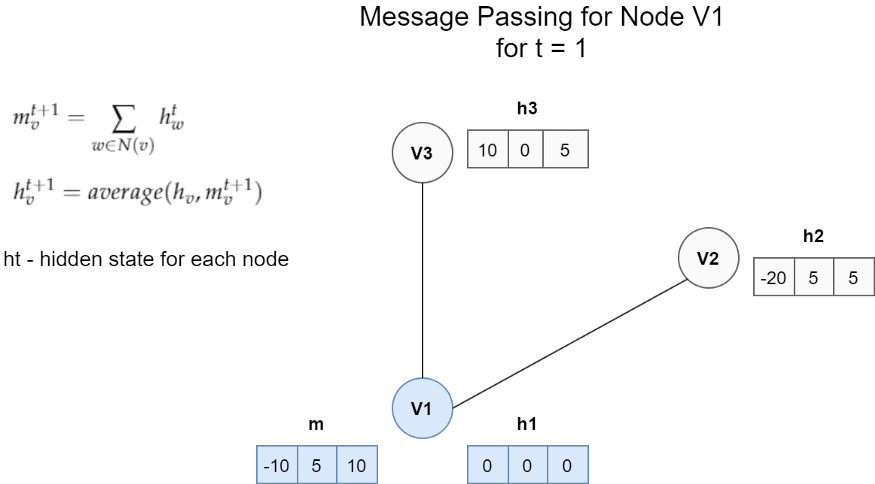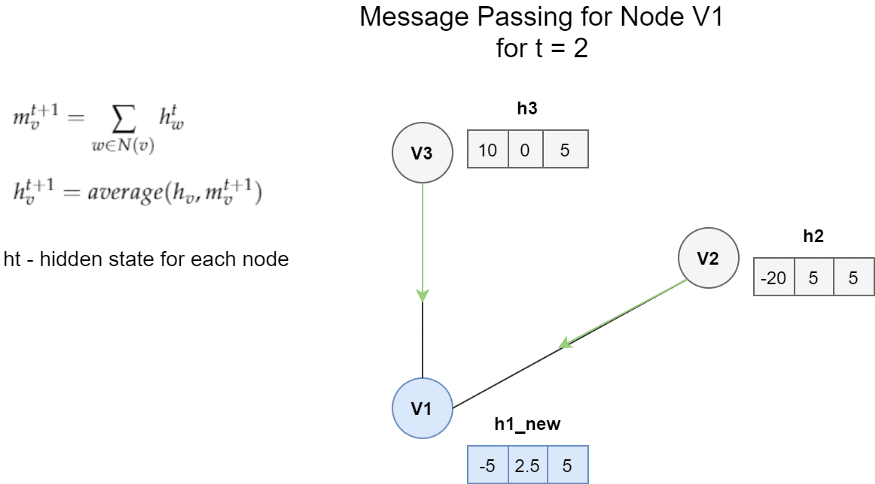
节点V1的消息传递体系结构的一个非常简单的示例。 在这种情况下,一条消息是邻居的隐藏状态的总和。 更新函数是消息m和h1之间的平均值。
毕竟,MPNN背后的想法在概念上很简单。
图中的每个节点都具有隐藏状态(即特征向量)。 对于每个节点Vt,我们将隐藏状态的函数以及所有相邻节点的边缘与节点Vt本身进行聚合。 然后,我们使用获得的消息和该节点的先前隐藏状态来更新节点Vt的隐藏状态。
有3个主要方程式定义图[3]上的MPNN框架。 从相邻节点获得的消息由以下公式给出:

从邻居节点获取消息。
它是从邻居获得的所有消息Mt的总和。 Mt是取决于隐藏状态和相邻节点边缘的任意函数。 我们可以通过保留一些输入参数来简化此功能。 在上面的示例中,我们仅求和不同的隐藏状态hw。
然后,我们使用一个简单的方程式更新节点Vt的隐藏状态:

使用先前的隐藏状态和新消息更新节点的状态。
简单地说,通过用新获得的消息mv更新旧的隐藏状态来获得节点Vt的隐藏状态。 在上述示例的情况下,更新函数Ut是先前隐藏状态和消息之间的平均值。
我们将此消息传递算法重复指定的次数。 之后,我们进入最后的读出阶段。

将获得的隐藏状态映射到描述整个图形的单个特征向量中。
在此步骤中,我们提取所有新近更新的隐藏状态,并创建描述整个图形的最终特征向量。 然后可以将此特征向量用作标准机器学习模型的输入。
就是这样! 这些是MPNN的基础。 这个框架非常强大,因为我们可以定义不同的消息并根据想要实现的功能更新功能。 我建议查看[3]以获得更多信息,以了解MPNN模型的不同变体。
在哪里可以找到模型的实现
MPNN已经被少数深度学习库实现。 以下是一些我可以找到的不同实现的列表:
原始模型代码 https://github.com/brain-research/mpnn
Deepchem整合https://github.com/deepchem/deepchem/tree/master/contrib/mpnn
PyTorch的Geometric实现 https://github.com/rusty1s/pytorch_geometric
总结
MPNN框架标准化了由多个研究人员独立创建的不同消息传递模型。 该框架的主要思想包括消息,更新和读出功能,它们在图中的不同节点上运行。 MPNN模型的一些变体共享此功能,但是它们的定义不同。
引用
[1] Convolutional Networks on Graphs for Learning Molecular Fingerprints
[2] Gated Graph Sequence Neural Networks
[3] Neural Message Passing for Quantum Chemistry
作者:Kacper Kubara
deephub翻译组


















