
这篇文章呢在自然语言处理领域有里程碑意义,是word embedding的开山之作。今天我们就来复现一下这篇文章的代码。
先回顾一下子模型结构
论文笔记看:MNLM:Word Embedding开山之作 A Neural Probabilistic Language Model_LolitaAnn的技术博客_51CTO博客
论文原文看:ResearchGate:A Neural Probabilistic Language Model
论文讲解视频看:MNLM:A neural probabilistic language model_哔哩哔哩_bilibili
写之前先回顾一下模型构造,知道构造才能知道要写什么嘛。
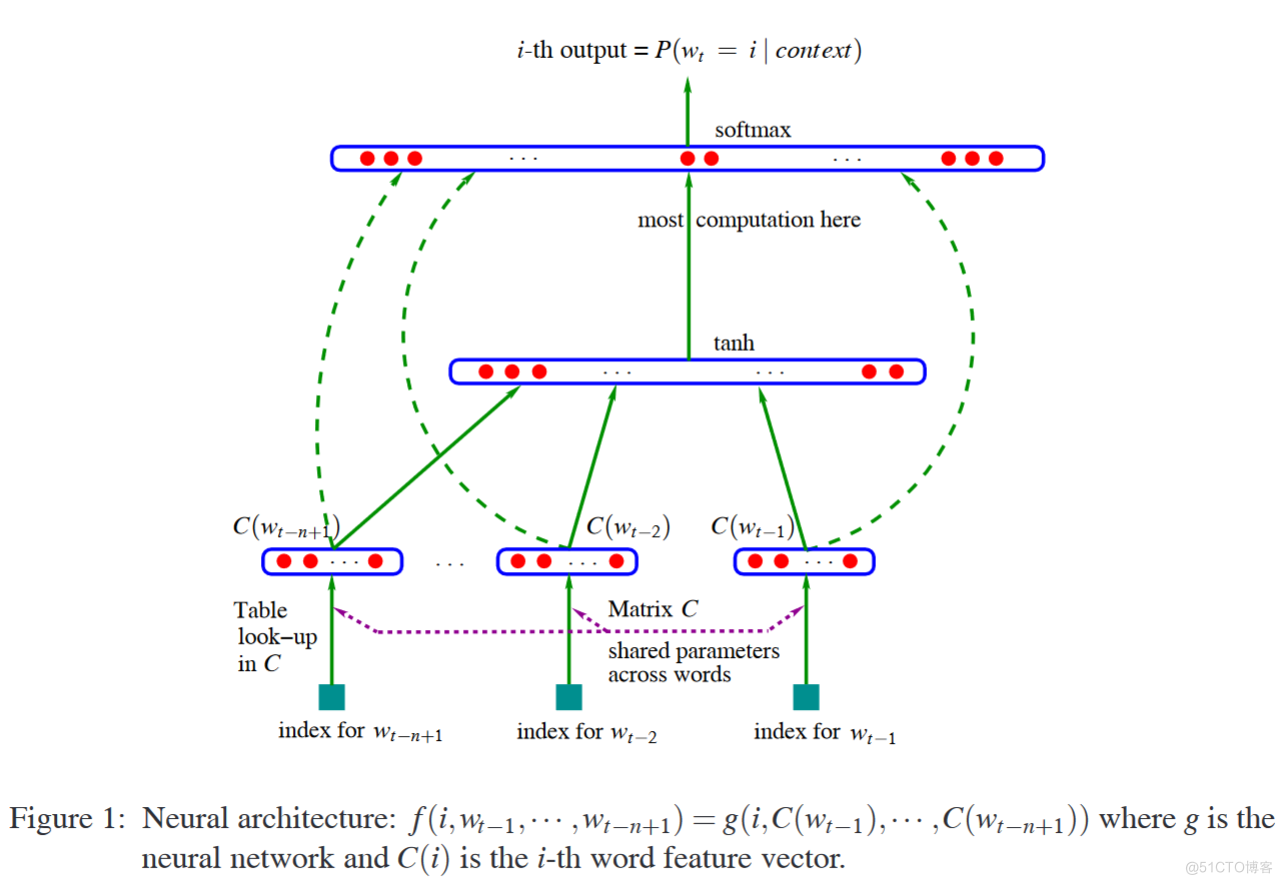
公式是:
$$ y=b+W x+U \tanh (d+H x) $$
- y 是输出
- x 是输入,之后会转化为图中的C,但是原文公式还用的x表示
- d 是隐藏层的bias
- H 是输入层到隐藏层的权重
- U 是隐藏层到输出层的权重
- W 是c直接到输出层的权重
- b 是输出层的bias
解释一下网络是怎么出来的
我们可以知道这是一个有一个隐藏层的神经网络。 并且看一下上图的注解,写的是$C(i)$是第i个单词的特征向量。所以输入要进行embedding处理。
这里我们还是要注意一点,就是虽然收入要经过一个embedding的处理,但是原公式中还是写的输入是X。
注意我标红的部分,这里是输入直接有一个到输出的。
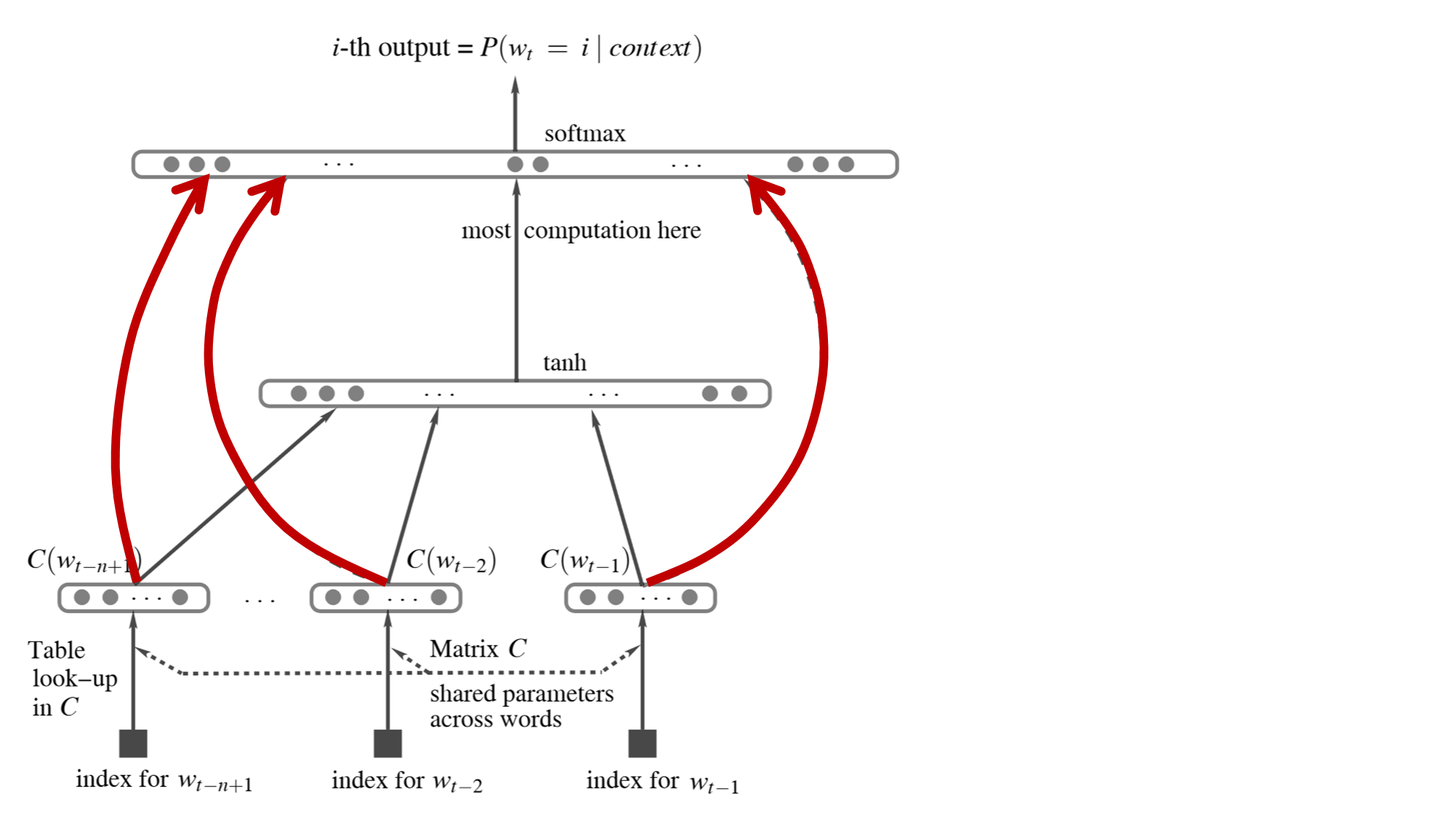
就是下图红框的部分。

去掉红框剩下的就是常规的多层感知机,就不用多解释了。

看一下论文原文部分:

这部分说了一下模型的参数设置,先是说了一下W和x这两个量。x是一个word embedding的矩阵。W是一个初始化为0的矩阵。然后就是剩下的几个参数说了一下参数的形状。
代码
模型代码
然后就可以创建好我们的网络了。
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(n_class, m)
self.H = nn.Parameter(torch.randn(len_sen * m, n_hidden,requires_grad=True))
self.d = nn.Parameter(torch.randn(n_hidden))
self.U = nn.Parameter(torch.randn(n_hidden, n_class,requires_grad=True))
self.W = nn.Parameter(torch.zeros(len_sen * m, n_class,requires_grad=True))
self.b = nn.Parameter(torch.randn(n_class))
def forward(self, X): # X : [batch_size, len_sen]
X = self.C(X) # X : [batch_size, len_sen, m]
X = X.view(-1, len_sen * m) # [batch_size, len_sen * m]
tanh = torch.tanh(self.d + X @ self.H) # [batch_size, n_hidden]
output = self.b + X @ self.W + tanh @ self.U # [batch_size, n_class]
return output
代码解析:
-
__init__(self)这部分是上面一些参数量。-
self.C是一个embedding操作。 -
其余的就是网络中的参数。提到的W初始化为0矩阵,所以W那里就用
torch.zeros,其余的就使用随机初始化torch.randn。
-
-
forward(self, X)就是设置前向传播,-
X = self.C(X),先将X进行一个embedding处理,然后再将结果还给X。就对应了我们前面提到的,虽然要经过一个embedding处理,但是原公式中输入还是用X表示的。 -
Tensor.view函数是修改张量形状的。torch.Tensor.view — PyTorch 1.11.0 documentation。 修改维度之后就是将每个句子中每个单词的word embedding向量拼接起来。 -
self.d + X @ self.H这里是输入层的隐藏层的计算。 -
tanh = torch.tanh(self.d + X @ self.H)计算结果要经过tanh的激活函数。这里是将tanh激活函数计算之后的结果直接赋值给了一个叫tanh的变量。 -
output = self.b + X @ self.W + tanh @ self.U然后是输出层计算。这里要注意输出层的结果是有两部分组成的。一部分是隐藏层传过来的结果,一部分是输入层传过来的结果,二者相加之后才是隐藏层的计算。
-
维度解析:
从第十一行代码开始,我在后面都标注了维度的。现在我们来解释一下。
最开始X是输入了几个句子,然后每个句子有不同的长度。这里你输入几个句子就是你的样本数量,我们用batch_size表示。每个句子的长度用len_sen表示。
m是embedding向量的长度。使用外号的向量表示一个单词的时候,你的词汇表有多长,你的表示向量就有多长。但是你现在使用特征值来表示一个单词。你仅需要设定你想表示的特征向量的长度即可,这个m是可以自己设置的。因为这个代码里用到的数据比较简单,所以你设置的小一点也没有关系。我在这里是设置为3。
隐藏层的大小设置为n_hidden。词汇表的长度是n_class。
-
最开始你的输入是一组句子嘛,所以你的输入X的形状应该是 [batch_size, len_sen]。此时矩阵的每一个元素都是一个单词。

-
经过第一步embedding计算之后,就会将其转化为特征向量表示。此时的X的形状应该是[batch_size, len_sen, m]。因为原来你是一个元素,表示一个词。现在变成了一个词,用一个特征向量来表示。所以就增加了一个维度来表示这个特征向量。现在变成了一个三维矩阵。

-
经过
Tensor.view修改形状。这里是X.view(-1, len_sen * m)修改为二维矩阵,矩阵的第二维是len_sen * m,第一维度自适应(-1是自适应的意思)。意思就是把一个句子中不同单词的表示做一个concate,拼接起来。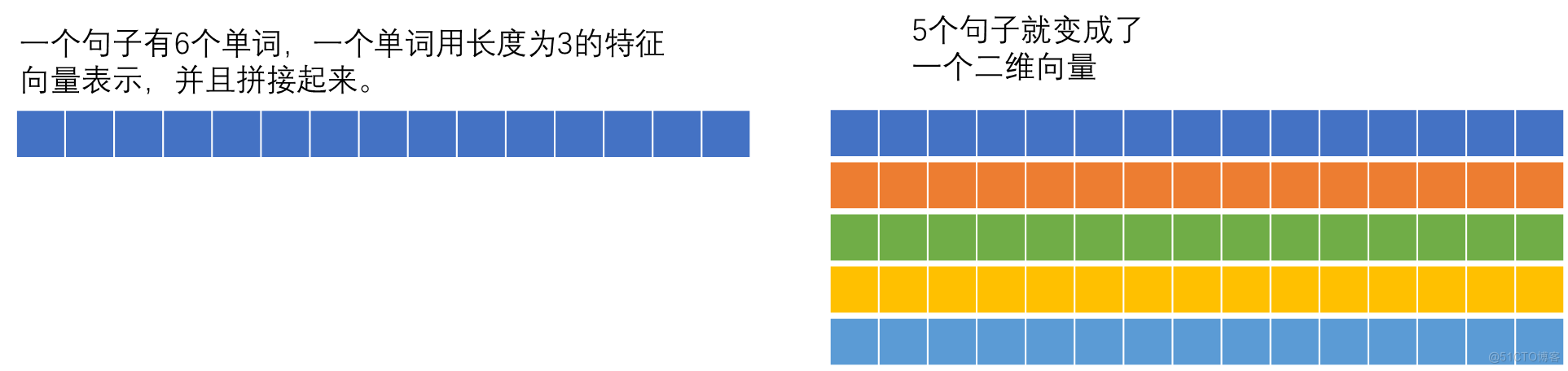
-
tanh这里已经到了隐藏层了。所以输入向量的长度会变成隐藏层的大小。这个隐藏层的大小n_hidden也是需要自己设置的。隐藏层大小决定网络的质量。当然我们这里数据量比较小,所以好不好其实隐藏层大小的影响根本就不大。一般隐藏层的大小遵循以下几个规则。假设:
- 输入层大小为$n$
- 输出层分为$m$类
- 样本数量为$s$
- 一个常数$c$
常见的观点有隐藏层数量$h$:
- $h = \frac{s}{c(n+m)} \quad c \in [2,10]$
- $h = \sqrt{n+m} + c \quad c \in [1,10]$
- $h = \sqrt{nm}$
- ……
- 神经网络中如何确定隐藏层的层数和大小_LolitaAnn的技术博客_51CTO博客
在这里我们就使用$h = \sqrt{nm}$。在我们的代码里输入的长度就是
len_sen * m。分类大小就是单词表的长度n_class。计算之后h的大小为14。此时的
tanh维度为[batch_size, n_hidden]。
-
输出层形状是[batch_size, n_class],输出层要做的对每一个样本计算最终获得一个向量。这向量的长度和单词表的长度一样,以此指出预测结果在单词表中的位置。

数据预处理部分的代码
我们先要制作一个单词表。这里是一个最基础的一个处理。用空格进行分词,然后把所有的单词都转化成小写放到单词表中,再制作好对应的索引。
sentences = ["The cat is walking in the bedroom",
"A dog was running in a room",
"The cat is running in a room",
"A dog is walking in a bedroom",
"The dog was walking in the room"]
word_list = " ".join(sentences).lower().split()
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)}
number_dict = {i: w for i, w in enumerate(word_list)}
- 第七行代码
word_list是把数据集中的所有句子都用空格拼接起来。然后再将其转化成小写。然后再用空格将其分开,分成不同的词。此时就得到了一个单词列表。但是现在里面会有很多重复的词。 - 第八行的代码
word_list先使用set,把上面得到的那个列表转换成一个集合,去掉重复的词,然后再转换回列表。 - 第九行和第十行代码就是使用枚举创建单词表的词典。
因为给定的数据是一堆句子,我们要把它分开,分为输入和输出,我们在这里做的一个任务是预测下一个词。我们选择用论文原文中的长度为7的句子,我们将前6个词作为输入来预测最后一个词。所以数据预处理部分就是先将一个句子拆分成输入和输出。
def dataset():
input = []
target = []
for sen in sentences:
word = sen.lower().split() # space tokenizer
i = [word_dict[n] for n in word[:-1]] # create (1~n-1) as input
t = word_dict[word[-1]] # create (n) as target, We usually call this 'casual language model'
input.append(i)
target.append(t)
return input, target
这张代码应该不用过多的解释了,看一下这个输出结果你们就能懂了。就是把每个样本都处理好了之后,再拼接到一个矩阵里面。

完整代码
import torch
import torch.nn as nn
import torch.optim as optim
def dataset():
input = []
target = []
for sen in sentences:
word = sen.lower().split() # space tokenizer
i = [word_dict[n] for n in word[:-1]] # create (1~n-1) as input
t = word_dict[word[-1]] # create (n) as target, We usually call this 'casual language model'
input.append(i)
target.append(t)
return input, target
# Model
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(n_class, m)
self.H = nn.Parameter(torch.randn(len_sen * m, n_hidden,requires_grad=True))
self.d = nn.Parameter(torch.randn(n_hidden))
self.U = nn.Parameter(torch.randn(n_hidden, n_class,requires_grad=True))
self.W = nn.Parameter(torch.zeros(len_sen * m, n_class,requires_grad=True))
self.b = nn.Parameter(torch.randn(n_class))
def forward(self, X): # X : [batch_size, len_sen, m]
X = self.C(X) # X : [batch_size, len_sen, m]
X = X.view(-1, len_sen * m) # [batch_size, len_sen * m]
tanh = torch.tanh(self.d + X @ self.H) # [batch_size, n_hidden]
output = self.b + X @ self.W + tanh @ self.U # [batch_size, n_class]
return output
if __name__ == '__main__':
sentences = ["The cat is walking in the bedroom",
"A dog was running in a room",
"The cat is running in a room",
"A dog is walking in a bedroom",
"The dog was walking in the room"]
word_list = " ".join(sentences).lower().split()
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)}
number_dict = {i: w for i, w in enumerate(word_list)}
n_class = len(word_dict) # number of Vocabulary
len_sen = 6 # number of steps, n-1 in paper
m = 3 # embedding size, m in paper
n_hidden = (int)((len_sen*m*n_class)**0.5) # number of hidden size, h in paper
model = NNLM()
loss = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.003)
input, target = dataset()
input = torch.LongTensor(input)
target = torch.LongTensor(target)
# 训练之前先看一下效果。
predict = model(input).data.max(1, keepdim=True)[1]
print([sen.split()[:6] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()])
# Training
for epoch in range(5000):
optimizer.zero_grad()
output = model(input)
# output : [batch_size, n_class], target : [batch_size]
Loss = loss(output, target)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(Loss))
Loss.backward()
optimizer.step()
# Predict & test
predict = model(input).data.max(1, keepdim=True)[1]
print([sen.split()[:6] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()])
训练前后的输出对比:
[['The', 'cat', 'is', 'walking', 'in', 'the'], ['A', 'dog', 'was', 'running', 'in', 'a'], ['The', 'cat', 'is', 'running', 'in', 'a'], ['A', 'dog', 'is', 'walking', 'in', 'a'], ['The', 'dog', 'was', 'walking', 'in', 'the']] -> ['dog', 'walking', 'cat', 'a', 'walking']
[['The', 'cat', 'is', 'walking', 'in', 'the'], ['A', 'dog', 'was', 'running', 'in', 'a'], ['The', 'cat', 'is', 'running', 'in', 'a'], ['A', 'dog', 'is', 'walking', 'in', 'a'], ['The', 'dog', 'was', 'walking', 'in', 'the']] -> ['bedroom', 'room', 'room', 'bedroom', 'room']















