
字符串的split用法
>>> s="Home page for Python"
>>> s.split()
['Home', 'page', 'for', 'Python']
字符串的split函数默认分隔符是空格 ' '
如果没有分隔符,就把整个字符串作为列表的一个元素
说明:
Python中没有字符类型的说法,只有字符串,这里所说的字符就是只包含一个字符的字符串!!!
这里这样写的原因只是为了方便理解,仅此而已。
由于敢接触Python,所以不保证以后还有没有其他用法,所以会在后面不断加入。。。
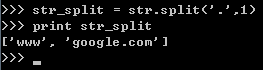
1.按某一个字符分割,如‘.’
1 2 3 4 | str = ('www.google.com')print strstr_split = str.split('.')print str_split |
结果如下:

2.按某一个字符分割,且分割n次。如按‘.’分割1次
1 2 3 4 | str = ('www.google.com')print strstr_split = str.split('.',1)print str_split |
结果如下:
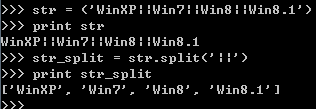
3.按某一字符串分割。如:‘||’
1 2 3 4 | str = ('WinXP||Win7||Win8||Win8.1')print strstr_split = str.split('||')print str_split |
结果如下:
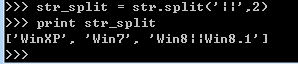
4.按某一字符串分割,且分割n次。如:按‘||’分割2次
1 2 3 4 | str = ('WinXP||Win7||Win8||Win8.1')print strstr_split = str.split('||',2)print str_split |
结果如下:
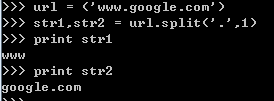
5.按某一字符(或字符串)分割,且分割n次,并将分割的完成的字符串(或字符)赋给新的(n+1)个变量。(注:见开头说明)
如:按‘.’分割字符,且分割1次,并将分割后的字符串赋给2个变量str1,str2
1 2 3 4 | url = ('www.google.com')str1, str2 = url.split('.', 1)print str1print str2 |
结果如下:
python join 和 split方法的使用,join用来连接字符串,split恰好相反,拆分字符串的。
1.join用法示例
>>>li = ['my','name','is','bob']
>>>' '.join(li)
'my name is bob'
>>>'_'.join(li)
'my_name_is_bob'
>>> s = ['my','name','is','bob']
>>> ' '.join(s)
'my name is bob'
>>> '..'.join(s)
'my..name..is..bob'
2.split用法示例
>>> b = 'my..name..is..bob'
>>> b.split()
['my..name..is..bob']
>>> b.split("..")
['my', 'name', 'is', 'bob']
>>> b.split("..",0)
['my..name..is..bob']
>>> b.split("..",1)
['my', 'name..is..bob']
>>> b.split("..",2)
['my', 'name', 'is..bob']
>>> b.split("..",-1)
['my', 'name', 'is', 'bob']
可以看出 b.split("..",-1)等价于b.split("..")
>>> urlstring = "http://www.google.com/"
>>> filepath.split('.|:|/')
['http://www.google.com']
>>> filepath.split('.')
['http://www', 'google', 'com']PYTHON常用字符串处理函数
在历史上string类在python中经历了一段轮回的历史。在最开始的时候,python有一个专门的string的module,要使用string的方法要先import,但后来由于众多的python使用者的建议,从python2.0开始, string方法改为用S.method()的形式调用,只要S是一个字符串对象就可以这样使用,而不用import。同时为了保持向后兼容,现在的 python中仍然保留了一个string的module,其中定义的方法与S.method()是相同的,这些方法都最后都指向了用S.method ()调用的函数。要注意,S.method()能调用的方法比string的module中的多,比如isdigit()、istitle()等就只能用 S.method()的方式调用。
对一个字符串对象,首先想到的操作可能就是计算它有多少个字符组成,很容易想到用S.len(),但这是错的,应该是len(S)。因为len()是内置函数,包括在__builtin__模块中。python不把len()包含在string类型中,乍看起来好像有点不可理解,其实一切有其合理的逻辑在里头。len()不仅可以计算字符串中的字符数,还可以计算list的成员数,tuple的成员数等等,因此单单把len()算在string里是不合适,因此一是可以把len()作为通用函数,用重载实现对不同类型的操作,还有就是可以在每种有len()运算的类型中都要包含一个len()函数。 python选择的是第一种解决办法。类似的还有str(arg)函数,它把arg用string类型表示出来。
字符串中字符大小写的变换:
S.lower() #小写
S.upper() #大写
S.swapcase() #大小写互换
S.capitalize() #首字母大写
String.capwords(S)
#这是模块中的方法。它把S用split()函数分开,然后用capitalize()把首字母变成大写,最后用join()合并到一起
S.title() #只有首字母大写,其余为小写,模块中没有这个方法
字符串在输出时的对齐:
S.ljust(width,[fillchar])
#输出width个字符,S左对齐,不足部分用fillchar填充,默认的为空格。
S.rjust(width,[fillchar]) #右对齐
S.center(width, [fillchar]) #中间对齐
S.zfill(width) #把S变成width长,并在右对齐,不足部分用0补足
字符串中的搜索和替换:
S.find(substr, [start, [end]])
#返回S中出现substr的第一个字母的标号,如果S中没有substr则返回-1。start和end作用就相当于在S[start:end]中搜索
S.index(substr, [start, [end]])
#与find()相同,只是在S中没有substr时,会返回一个运行时错误
S.rfind(substr, [start, [end]])
#返回S中最后出现的substr的第一个字母的标号,如果S中没有substr则返回-1,也就是说从右边算起的第一次出现的substr的首字母标号
S.rindex(substr, [start, [end]])
S.count(substr, [start, [end]]) #计算substr在S中出现的次数
S.replace(oldstr, newstr, [count])
#把S中的oldstar替换为newstr,count为替换次数。这是替换的通用形式,还有一些函数进行特殊字符的替换
S.strip([chars])
#把S中前后chars中有的字符全部去掉,可以理解为把S前后chars替换为None
S.lstrip([chars])
S.rstrip([chars])
S.expandtabs([tabsize])
#把S中的tab字符替换没空格,每个tab替换为tabsize个空格,默认是8个
字符串的分割和组合:
S.split([sep, [maxsplit]])
#以sep为分隔符,把S分成一个list。maxsplit表示分割的次数。默认的分割符为空白字符
S.rsplit([sep, [maxsplit]])
S.splitlines([keepends])
#把S按照行分割符分为一个list,keepends是一个bool值,如果为真每行后而会保留行分割符。
S.join(seq) #把seq代表的序列──字符串序列,用S连接起来
字符串的mapping,这一功能包含两个函数:
String.maketrans(from, to)
#返回一个256个字符组成的翻译表,其中from中的字符被一一对应地转换成to,所以from和to必须是等长的。
S.translate(table[,deletechars])
# 使用上面的函数产后的翻译表,把S进行翻译,并把deletechars中有的字符删掉。需要注意的是,如果S为unicode字符串,那么就不支持 deletechars参数,可以使用把某个字符翻译为None的方式实现相同的功能。此外还可以使用codecs模块的功能来创建更加功能强大的翻译表。
字符串还有一对编码和解码的函数:
S.encode([encoding,[errors]])
# 其中encoding可以有多种值,比如gb2312 gbk gb18030 bz2 zlib big5 bzse64等都支持。errors默认值为"strict",意思是UnicodeError。可能的值还有'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 和所有的通过codecs.register_error注册的值。这一部分内容涉及codecs模块,不是特明白
S.decode([encoding,[errors]])
字符串的测试函数,这一类函数在string模块中没有,这些函数返回的都是bool值:
S.startwith(prefix[,start[,end]])
#是否以prefix开头
S.endwith(suffix[,start[,end]])
#以suffix结尾
S.isalnum()
#是否全是字母和数字,并至少有一个字符
S.isalpha() #是否全是字母,并至少有一个字符
S.isdigit() #是否全是数字,并至少有一个字符
S.isspace() #是否全是空白字符,并至少有一个字符
S.islower() #S中的字母是否全是小写
S.isupper() #S中的字母是否便是大写
S.istitle() #S是否是首字母大写的
字符串类型转换函数,这几个函数只在string模块中有:
string.atoi(s[,base])
#base默认为10,如果为0,那么s就可以是012或0x23这种形式的字符串,如果是16那么s就只能是0x23或0X12这种形式的字符串
string.atol(s[,base]) #转成long
string.atof(s[,base]) #转成float
这里再强调一次,字符串对象是不可改变的,也就是说在python创建一个字符串后,你不能把这个字符中的某一部分改变。任何上面的函数改变了字符串后,都会返回一个新的字符串,原字串并没有变。其实这也是有变通的办法的,可以用S=list(S)这个函数把S变为由单个字符为成员的list,这样的话就可以使用S[3]='a'的方式改变值,然后再使用S=" ".join(S)还原成字符


















