
Nagios:状态监控工具,支持报警功能,自身有监控功能
1、nagios不同于cacti通过收集数据,并将结果以绘图的方式显示出来,而Nagios只返回状态值:
四种状态:
OK:正常状态
WARNING:警告状态
CRITICAL:紧急状态
UNKNOWN:未知状态
nagios不关心具体值的数据为多少,只根据返回的状态值而做出分析判断,当危机情况出现的时候能够启动强大的报警机制,向管理员发送报警通知
nagios也是插件式的,
nagios core不做监控工作,是一个监控平台,监控工作有插件来完成
(插件简单理解起来是脚本)
每一次检测只返回一个状态值;配置具有灵活性,复杂度也高
2、根据对象来实现监控工作的,
1)、主机对象:被监控的物理主机,虚拟机等,可归类为组
2)、服务/资源:统统称为服务;可划分为服务组
3)、联系人:联系人及联系人祖
4)、时段:对上面三种可以使用时段
5)、命令:可理解为命令模板,应用到某个被监控对象上,以实现具体的监控
多个被监控对象,如果有多个属相相同的时候,可定义为模板(template),
对某一个对象,可以套用模板,在定义自己独有的属性,
3、nagios监控方式有5大类:

1)、ssh:远程主机,在nagios server上是ssh的客户端,而client2上安装的是ssh的服务端sshd
实现过程是:由ssh向服务端sshd发送请求命令,并把结果返回给check_by_ssh插件,插件对返回结
果进行分析,把分析的结果再返回给插件核心,由核心决定是否对结果进行报警
2)、nrpe:专门用于监控unix/linux类的主机
2)、nrpe:专门用于监控unix/linux类的主机
需要在远程主机上专门安装nrpe守护进程和额外插件,在nagios server端要安装nrpe客户端软件

check_nrpe和nrpe(inetd)是基于c/s架构的
相当于子Nagios core和check_xyz之间增加了一个专门用于通信的层次,
信息流:nrpe-->nrpe(inetd) --> check_xyz --> nrep(inetd) --> nrpe --> nagios core -->决策
3)、snmp:
3)、snmp:
基于snmp和snmpd的通信机制
4)、NSCA:让nagios实现被动监控功能的
5)、check_xyz;用户可以自己定义取名的插件类型,直接获取远程主机的数据
4)、NSCA:让nagios实现被动监控功能的
5)、check_xyz;用户可以自己定义取名的插件类型,直接获取远程主机的数据
在Windows主机上使用的监控方式有:NSClient++和SNMp
在Linux主机上的监控方式:send_nsca和check_nrpe
4、各对象间的关系:

创建一个命令的过程就是实例化一个插件的过程
创建一个对象的过程就是实例化一个被监控对象的过程
软状态和硬状态:
报警是在状态发生转变时报警,但也不能一下就报警;
OK--> CRITICAL 时可以若干次检测之后 还是那样,就启动报警机制
在软状态时不会报警的,
当检测几次之后还是没有ok,就会报警;这是硬状态
flapping是一种特殊的状态,也是一种不正常状态间的转换,如OK-->WARNING-->OK-->CRITICAL-->UNKNOWN-->OK等
创建一个对象的过程就是实例化一个被监控对象的过程
软状态和硬状态:
报警是在状态发生转变时报警,但也不能一下就报警;
OK--> CRITICAL 时可以若干次检测之后 还是那样,就启动报警机制
在软状态时不会报警的,
当检测几次之后还是没有ok,就会报警;这是硬状态
flapping是一种特殊的状态,也是一种不正常状态间的转换,如OK-->WARNING-->OK-->CRITICAL-->UNKNOWN-->OK等
5、对象还有依赖关系:
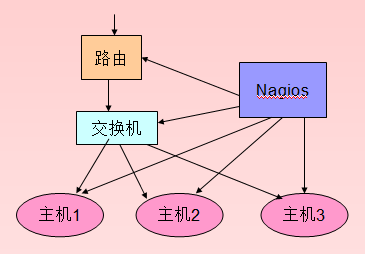
三台主机都连接在交换机上,当交换机故障时,nagios也就找不到主机了,此时也会认为主机为故障并会报警的,
但我们并不能确定主机就是否故障了,所以可以定义他们间的依赖关系,
所以当交换机故障报警时,我们对主机造成的影响不予考虑,此时联系人接受的报警是交换机的报警通知,
主机与其上的服务依赖关系:

当主机故障时,服务也就必然故障,也就没必要再监控服务了




















